Scalability
Community Support: https://www.djangoproject.com/foundation/
Performance:
Ace and CodeMirror both support vim keybindings.
https://en.wikipedia.org/wiki/Comparison_of_JavaScript-based_source_code_editors
The complete Anaconda distribution includes these packages. Minimally, this should do it:
conda create -n envname python pip sqlalchemy ipython-notebook cython numexpr pandas xlrd xlswriter # matplotlib
Pandas is fantastic if you want to build some analysis scripts
http://pandas.pydata.org/pandas-docs/dev/io.html#io-sql
http://pandas.pydata.org/pandas-docs/dev/io.html#io-excel
https://gist.github.com/westurner/9df804df387733312b89 (sqla2hdfstore.py w/ Pandas)
Sandman generates a REST API and configurable class-based admin CRUD scaffolding by introspecting SQL databases with SQLAlchemy.
How difficult would it be to add RDF serialization for read-only functionality similar to d2rq / LDP? http://d2rq.org/
Cool. I had also written code to parse headers from the WDI datasets before I realized that Pandas includes an API for this: http://pandas.pydata.org/pandas-docs/dev/remote_data.html#remote-data-wb
I believe some of this data is also available through the Quandl API, for which there is a Python implementation which also reads data into Pandas DataFrames: http://pythonhosted.org//Quandl/
Using the IPython Notebook as a Teaching Tool
Posted 2013-03-24 by Greg Wilson in Education, Tooling.
Some helpful, relevant links to docs and sources:
IPython notebook reveal.js slides with nbconvert:
Jupyter:
http://scikit-learn.org/stable/auto_examples/
http://stanford.edu/~mwaskom/software/seaborn/examples/
classifier performance / feature extraction: is it a binary classifier from which you could derive a contingency table or a confusion matrix with frequencies of:
https://en.wikipedia.org/wiki/Receiver_operating_characteristic
http://scikit-learn.org/stable/auto_examples/plot_roc.html
http://scikit-learn.org/stable/auto_examples/plot_roc_crossval.html
http://scikit-learn.org/stable/modules/generated/sklearn.metrics.roc_curve.html
What operations work on SQL databases?
Most tabular operations, but not all. SQLAlchemy translation is a high priority. Failures include array operations like slicing and dot products don’t make sense in SQL. Additionally some operations like datetime access are not yet well supported through SQLAlchemy. Finally some databases, like SQLite, have limited support for common mathematical functions like
sin.
... /r/pystats (sidebar)
If you're set on an ORM, SQLAlchemy is great.
Django-nonrel is not yet updated to 1.7: https://github.com/django-nonrel/django/issues/15
Django has a Software Foundation: https://www.djangoproject.com/foundation/
A few links from https://github.com/westurner/wiki/wiki/awesome-python-testing#web-frameworks :
I am curious to hear from actual data scientists and also industrial engineers on what they think about my thoughts about industrial engineering as a basis to enter the data science field?
Data Science is domain independent?
https://en.wikipedia.org/wiki/Blind_experiment#Triple-blind_trials
http://www.datascienceassn.org/content/fourth-bubble-data-science-venn-diagram-social-sciences
As far as holism, there should be domain-independent terms in https://en.wikipedia.org/wiki/Glossary_of_systems_theory
http://today.slac.stanford.edu/images/2009/colloquium-web-collide.jpg
... https://en.wikipedia.org/wiki/Cybernetics just has a ring to it.
With this command, the pip in bin/pip installs into a conda env, just like virtualenv:
conda create --mkdir --prefix "$WORKON_HOME/envname" --yes python readline pip
Instead of python, python3 should also work.
Python 3:
from https://wrdrd.github.io/docs/consulting/knowledge-engineering.html :
https://en.wikipedia.org/wiki/Hypertext_Transfer_Protocol
http://www.w3.org/TR/HTTP-in-RDF10/
http://www.w3.org/TR/HTTP-in-RDF10/
| xmlns: @prefix http <http://www.w3.org/2011/http#>
| xmlns: @prefix http-headers <http://www.w3.org/2011/http-headers>
| xmlns: @prefix http-methods <http://www.w3.org/2011/http-methods>
| xmlns: @prefix http-statusCodes <http://www.w3.org/2011/http-statusCodes>
| LOVLink: http://lov.okfn.org/dataset/lov/details/vocabulary_http.html
https://en.wikipedia.org/wiki/HTTP/2
https://en.wikipedia.org/wiki/Resource_Description_Framework
http://www.w3.org/TR/rdf11-concepts/#section-html
| @prefix rdf: http://www.w3.org/1999/02/22-rdf-syntax-ns# .
| LOVLink: http://lov.okfn.org/dataset/lov/details/vocabulary_rdf.html
https://en.wikipedia.org/wiki/RDFa
https://en.wikipedia.org/wiki/JSON-LD
https://en.wikipedia.org/wiki/SPARQL
Challenges:
LIMIT clauses and paging windows
could allow for more efficient cachingLDP for more of a resource-based RESTful API
that can be implemented on top of
the graph pattery queries supported by SPARQL.http://www.w3.org/TR/ldp/#terms
| xmlns: @prefix ldp: <http://www.w3.org/ns/ldp#> .
| LOVLink: http://lov.okfn.org/dataset/lov/details/vocabulary_ldp.html
Features:
HTTP REST API for Linked Data Platform Containers (LDPC)
containing Linked Data Plaform Resources (LDPR)Additional ideas for IPython _repr_<type>_ methods:
_repr_rdfa_ = "text/html" (_repr_html_) + [xmlns: namespaces]_repr_jsonld_ = "application/json" (_repr_json_) + (@context = {})
@context
@base@vocabulary -- http://www.w3.org/TR/json-ld/#default-vocabularySo, from (https://github.com/ipython/ipython/blob/master/IPython/utils/capture.py and https://github.com/ipython/ipython/blob/master/IPython/utils/tests/test_capture.py#L27) and (https://github.com/ipython/ipython/blob/master/IPython/core/display.py and https://github.com/ipython/ipython/blob/master/IPython/core/tests/test_display.py) :
_mime_map = dict(
_repr_png_="image/png",
_repr_jpeg_="image/jpeg",
_repr_svg_="image/svg+xml",
_repr_html_="text/html",
_repr_json_="application/json",
_repr_javascript_="application/javascript",
)
# _repr_latex_ = "text/latex"
# _repr_retina_ = "image/png"
https://webargs.readthedocs.org/en/latest/#webargs.core.Parser.parse
https://webargs.readthedocs.org/en/latest/_modules/webargs/core.html#Parser.parse
https://github.com/sloria/webargs/blob/dev/webargs/core.py#L272
DEFAULT_TARGETS = ('querystring', 'form', 'json',)
#: Maps target => method name
__target_map__ = {
'json': 'parse_json',
'querystring': 'parse_querystring',
'query': 'parse_querystring',
'form': 'parse_form',
'headers': 'parse_headers',
'cookies': 'parse_cookies',
'files': 'parse_files',
}
I like that these are explicit and configurable, but I would default to just ('form',) (POST). ... logging could be helpful, if verbose.
"Linked Data Patterns: A pattern catalogue for modelling, publishing, and consuming Linked Data" http://patterns.dataincubator.org/book/
This is great; thanks!
Again, thanks!
So you couldnt say tht unicorns dont exist. You can only say that you habe no proof for Them.
https://en.wikipedia.org/wiki/Epistemology#A_priori_and_a_posteriori_knowledge
https://en.wikipedia.org/wiki/Epistemology#The_Gettier_problem
So, would these always be true?
isinstance(object(), Any)isinstance(3, Any)isinstance('str', Any)[EDIT] Whereas currently one would need to do the following for explicit runtime-type-checking:
isinstance(object(), (object, str, int, float, bool, ...))isinstance(3, (object, str, int, float, bool, ...))isinstance('str', (object, str, unicode, basestring, int, float, bool, ...))But the preferred duck-typing approach would be something like:
hasattr([], '__iter__')~ "This frame language is too rigid to contain my boundless aspirations"
There's nothing stopping one from creating a local schema/ontology (e.g. with UUID URNs (like Freebase)) and linking it later (thus adding complexity to a query meant to identify similarities and differences between local representations).
TBox statements describe a conceptualization, a set of concepts and properties for these concepts. ABox are TBox-compliant statements about individuals belonging to those concepts. For instance, a specific tree is an individual for the concept of "Tree", while it can be stated that trees as a concept are material beings that have to be positioned on some location it is possible to state the specific location that a tree takes at some specific time.
Together ABox and TBox statements make up a knowledge base. A TBox is a set of definitions and specializations.
Could a TBox be general enough to allow for flexible modeling in an ABox?
... https://wrdrd.github.io/docs/consulting/knowledge-engineering.html
I think hashtags is an example of user friendly SW.
I agree. And Linked Data ... http://5stardata.info/
Limitations of spreadsheets as an initial model for data conceptualization:
Why don't we all create our own ontologies, and then link them? (e.g. with SKOS and XKOS)
What sorts of usability enhancements would make it easy to reference existing terminology?
There are lots of tools with this sort of flexibility, though, indeed, none have reached critical popularity.
https://en.wikipedia.org/wiki/Entity%E2%80%93attribute%E2%80%93value_model
...
https://en.wikipedia.org/wiki/Resource_Description_Framework#History
https://en.wikipedia.org/wiki/Reification_%28computer_science%29#RDF_and_OWL
http://patterns.dataincubator.org/book/
http://patterns.dataincubator.org/book/nary-relation.html
http://patterns.dataincubator.org/book/qualified-relation.html
... @en
OS overhead
https://en.wikipedia.org/wiki/Docker_(software)
https://en.wikipedia.org/wiki/Operating_system%E2%80%93level_virtualization#Overhead
https://wiki.openstack.org/wiki/HypervisorSupportMatrix
http://docs.saltstack.com/en/latest/#getting-started
http://docs.saltstack.com/en/latest/ref/states/all/salt.states.dockerio.html
https://github.com/rvguha/schemaorg/issues/196
https://github.com/OpenGovLD/specs/issues/11
Or it might be possible to extend SKOS with
skos:prefPluralLabel.
It's called a pencil!
This.
One main issue is reification because RDF isn't n-ary.
http://patterns.dataincubator.org/book/nary-relation.html
http://patterns.dataincubator.org/book/qualified-relation.html
http://www.nagvis.org/ is web-based and generates topology diagrams.
https://shinken.readthedocs.org/en/latest/11_integration/nagvis.html
A few resources:
https://en.wikipedia.org/wiki/OpenCog
http://wiki.opencog.org/w/CogPrime_Overview
#Local_and_Global_Knowledge_Representation
https://en.wikipedia.org/wiki/Resource_Description_Framework
You can accomplish the same (and more) with many logshippers:
Awesome!
Could this graph extraction also be accomplished with http://dbpedia.org/sparql and/or http://wiki.dbpedia.org/Downloads2014 ?
seeAlso: https://www.reddit.com/r/Python/comments/2og2lq/trying_to_make_an_interactive_visualization_of_a/cmn6grn (cytoscape, sigma.js)
Is semantic web still a thing ?
You are correct.
I should have said, "if EDITOR is set to vim --servername VIM --remote-tab-silent [...]" (which is not what was suggested). ... IDK if expand_aliases has anything to with this.
It's worth mentioning that it's usually better to generate reports with a task function in a (rate-limited) queue in order to avoid resource exhaustion. JS can then poll for task status and redirect or refresh when then task is complete.
[EDIT] https://github.com/johnsensible/django-sendfile can make this much faster
If the file changes, the file path/querystring can/should also change to avoid caching issues.
If EDITOR is set to vim, this can cause problems with things like git commit that expect the editor to block until closed. (--remote-wait does this, but if there are other windows open, vim -f works)
... https://github.com/westurner/dotfiles/blob/master/etc/bash/20-bashrc.editor.sh
You can also configure a shortcut to the first local vim window:
set $editor_selector [class="Gvim"]
# <alt> v -- focus nearest: editor
bindsym $mod+v $editor_selector focus
And create a vim scratchpad window:
set $scratchpad_editor_selector [title="SCRATCHPAD"]
set $scratchpad_start_editor gvim --servername SCRATCHPAD --remote ~/TODO
# <XF86Favorites> -- show the $scratchpad_editor_selector
bindsym XF86Favorites $scratchpad_editor_selector scratchpad show
# # on (re)load, move $scratchpad_editor_selector windows to scratchpad
for_window $scratchpad_editor_selector move to scratchpad
# <alt><shift> s -- start scratchpad editor
bindsym $mod+Shift+s exec $scratchpad_start_editor
# <alt> <XF86Favorites> -- start scratchpad editor
bindsym $mod+XF86Favorites exec $scratchpad_start_editor
... https://github.com/westurner/dotfiles/blob/master/etc/.i3/config
Marmotta is written in Java.
A Marmotta client library written in Python would be great.
Any Python program can access a Linked Data server over SPARQL (HTTP); though it is far more safe to use a query-writing library that manages parametrization (and sane LIMIT clauses) than to build SPARQL query strings with naïve string concatenation.
5 ★ Open Data
Tooling, strong conventions, and code review are what make big projects a manageable reality.
Thanks!
Sysadmins are basically just engines that convert ethanol into computer knowledge.
Value added.
You're looking for a delta in one or more metrics. (Calculus, or chart reading)
There are lots of systems monitoring tools. These may be helpful:
[EDIT] Link to second derivative
Does something like this work?
https://pythonhosted.org/psutil/#psutil.process_iter
https://pythonhosted.org/psutil/#psutil.net_connections
pids = [x.pid for x in psutil.net_connections() if x.raddr[-1] in [80, 443]]
pids_dict = dict.fromkeys(pids)
processes = [x for x in psutil.process_iter() if x.pid in pids_dict]
for p in processes:
print(p.memory_info())
[EDIT] Here's this, which requires privs (on OSX): https://gist.github.com/westurner/91cbdcadaf0a51d1c3ba
I've grown to prefer sarge for the format strings: http://sarge.readthedocs.org/en/latest/
Frameworks solve problems that we didn't even know we had.
https://wrdrd.github.io/docs/consulting/web-development.html#web-development-checklist
https://wrdrd.github.io/docs/consulting/software-development.html#project-management
https://www.reddit.com/r/Python/comments/1eboql/python_website_tuts_that_dont_use_django/#c9yxl8w (Django is a great web framework)
http://symfony.com/doc/current/book/from_flat_php_to_symfony2.html
https://en.wikipedia.org/wiki/Graph_drawing
https://en.wikipedia.org/wiki/Category:Graph_drawing_software
Are there any particularly good graph libraries out there that are worth learning?
Gource VCS visualizations are pretty impressive background material:
IPython notebooks and/or Spyder are probably a good intro:
... "this is something you can do at home"
http://ipython.org/ipython-doc/dev/install/install.html
conda create -n py27 python readline pipconda install ipython-notebook spyderCool script!
I usually wrap code to be executed in a def main(*args) method, and then add:
if __name__ == "__main__":
main()
# import sys
# sys.exit(main()) # UNIX programs return '0' if there is not an error
This has (at least) two benefits:
import pywapitest, the script does not executeunittest.TestCase) possible+1. Catching exceptions and HTTP status codes with requests is far simpler: http://requests.readthedocs.org/en/latest/user/quickstart/#response-status-codes
cc'd from ipython-dev "A Reproducible IPython project template (was: Create New Notebook from Command-line)"
This could be a useful commandline option.
You could accomplish the same with a https://github.com/audreyr/cookiecutter jinja2 project template.
- There could be variations on such a template e.g. with default headings for:
- https://en.wikipedia.org/wiki/Scientific_method#Elements_of_the_scientific_method
- { Abstract, Question, Hypothesis, Experiment, Observations/Data, Analysis, Conclusion, ... }
Really, a reproducible project template could have:
- folders for e.g.
./data,./scripts,./notebooks(possibly ./lib for vendored libraries)- a
setup.pysupporting a necessary directory structure- a
Makefile(that generates an index with links to nbviewer)- an
install.shscript
- (miniconda;
conda create -n py27 python readline pip)- https://github.com/westurner/notebooks/blob/gh-pages/install.sh
- an extension (that I still believe should be included with IPython) that lists the versions of all installed (on the import path) and utilized libraries and extensions
requirements.txt for pip (or peep)We should also be interested in smaller software that are useful parts of a general intelligence, like statistical tools.
Opensource is not just a matter of philosophy. If we cant look into how it works and improve it for our own purposes, its not much use in AI research.
[...]
https://en.wikipedia.org/wiki/Ethics
https://en.wikipedia.org/wiki/Philosophy_of_artificial_intelligence
https://en.wikipedia.org/wiki/Developmental_psychology
https://en.wikipedia.org/wiki/Disability_Rating_Scale#Rating_Scale
...
This is great; thanks!
PyQt and PySide are also really easy to install with Anaconda:
conda install python readline pipconda install spyder should install Qtconda install ipython-notebook)This is abbreviated from https://github.com/westurner/pypfi/blob/da0e7267/pypfi/pypfi.py :
import numpy as np
import pandas as pd
colname = 'date'
n_rows = 100
start_date = '2014-01-01'
df = pd.DataFrame({
'date': pd.date_range(start=start_date, periods=n_rows ),
'amount': np.random.randint(0, 100, size=n_rows)})
df['year'] = df[colname].apply(lambda x: x.year)
df['yearmonth'] = df[colname].apply(lambda x: "%d-%02d" % (x.year, x.month))
df['month'] = df[colname].apply(lambda x: x.month)
df['weekday'] = df[colname].apply(lambda x: x.weekday())
df['hour'] = df[colname].apply(lambda x: x.hour)
by_year = df.groupby(df['year'], as_index=True)['amount'].sum()
by_yearmonth = df.groupby(df['yearmonth'], as_index=True)['amount'].sum()
by_year_mon = df.groupby((df['year', 'month']))
by_month = df.groupby(df['month'], as_index=True)['amount'].sum()
by_weekday = df.groupby(df['weekday_abbr'], as_index=True)['amount'].sum()
by_hour = df.groupby(df['hour'], as_index=True)['amount'].sum()
df_yearmonth = pd.pivot_table(df,
index=['date', 'index'],
columns=['year','month'],
values='amount',
aggfunc=np.sum,
margins=True)
output['pivot_by_yearmonth'] = df_yearmonth
Something similar could be useful in the pandas docs, which are here: https://github.com/pydata/pandas/tree/master/doc
These could be even more useful as an /r/IPython notebook. (e.g. though http://nbviewer.ipython.org/ or with https://github.com/jupyter/tmpnb etc.)
Does savetxt escape quotes?
"One, " two", three
Re: ORMs, performance, and expertise
What is the likelihood that you and your team are going to optimize object (de)serialization and instantiation better than SQLAlchemy? What do you want to need to write tests for?
If you don't need transactions, why even use a SQL database?
If there is a full time DBA who can write faster raw queries with engine.execute (or DB-API) (and read them into testable objects), who knows better than to concatenate strings into queries without parameterization (in order to prevent SQLi by default), who contributes to or maintains a database driver and understands the idiosyncrasies of other database drivers well-enough to implement workarounds when that's the best option, then hire that DBA to normalize the tables into performance land and cross your fingers that they want to train additional team members, for the future.
If performance profiling indicates that optimization is necessary (with a near-production architecture), then A/B and subtract.
Hynek Schlawack wrote an article that discusses this:
Thanks!
The one-sized Gunnar gaming glasses from bb definitely take the edge off.
I don't have another answer for that question
This generates HTML with Jinja2 from RDF:
Inputs: Turtle file n (Ontology, Ontologies, Instances)
https://github.com/westurner/healthref/blob/gh-pages/treatment_alternatives.ttl
Transforms: rdflib, pygments, optparse CLI script:
https://github.com/westurner/healthref/blob/6f41523/healthref.py
Transforms: jinja2, bootstrap template
https://github.com/westurner/healthref/blob/6f41523/templates/healthref.html
Outputs: static HTML for gh-pages (Git-backed CDN-hosted HTML with a low cache time)
https://github.com/westurner/healthref/blob/gh-pages/index.html
[EDIT]
https://github.com/westurner/pycd10api
http://www.reddit.com/r/medicine/comments/1iqxan/schemaorg_healthmedicine_docs_linked_data_types/ (https://westurner.github.io/redditlog/#submission/1iqxan)
"schema.org health/medicine docs: Linked Data types like MedicalScholarlyArticle, MedicalWebPage, MedicalGuideline, Dataset, and MedicalEntity"
http://schema.org/docs/meddocs.html
... http://www.reddit.com/r/Python/comments/29rn3q/science_programmers_i_need_to_analyse_a_diet/cioxv9d (https://westurner.github.io/redditlog/#comment/cioxv9d)
Copied from OT to a comment here so I can read this in my commentstream
With ReStructuredText::
```restructuredtext
========
Title
========
.. index:: DBPedia
.. _dbpedia:
`<Subject <#dbpedia>`__
============================
| Wikipedia: `<https://en.wikipedia.org/wiki/Dbpedia>`__
| Homepage: http://dbpedia.org
| Docs: http://dbpedia.org/About
| Docs: http://wiki.dbpedia.org/Downloads2014
| SPARQL: http://dbpedia.org/sparql
DBPedia is an extract of RDF facts from Wikipedia. (description)
```
From https://www.reddit.com/r/semanticweb/comments/2n1bea/is_there_an_awesomesemanticweb_or_an/cm9ffxx :
> Thing > CreativeWork > http://schema.org/SoftwareApplication
>
> Thing > CreativeWork > Article > http://schema.org/ScholarlyArticle
>
> Thing > CreativeWork > http://schema.org/Code
>
> Thing > CreativeWork > http://schema.org/Dataset
Thing > CreativeWork > http://schema.org/SoftwareApplication
Thing > CreativeWork > Article > http://schema.org/ScholarlyArticle
Thing > CreativeWork > http://schema.org/Code
Thing > CreativeWork > http://schema.org/Dataset
With Sphinx, a block of http://www.w3.org/TR/turtle/ syntax would need to be parsed at a different time in the build chain.
Are there roles or directives for sphinx or markdown which support
::
DBPedia
=========
Conjectured RDF in ReStructuredText and a request for
a comparable solution in Markdown.
:author: @westurner
:ref:`DBPedia ref <dbpedia>` is one way to go
:triplerole:`DBPedia triplerole <#dbpedia>` is another. Also, JSON-LD.
.. tripledirective::
:sourcefile:
:destfile:
:show_formats:
@prefix : <> . # TODO
@prefix dbp: <http://dbpedia.org/resource/> .
@prefix dbpedia-owl: <http://dbpedia.org/ontology/> .
@prefix foaf: <http://xmlns.com/foaf/0.1/> .
@prefix label: <http://purl.org/net/vocab/2004/03/label#> .
@prefix owl: <http://www.w3.org/2002/07/owl#> .
@prefix rdf: <http://www.w3.org/1999/02/22-rdf-syntax-ns#> .
@prefix rdfs: <http://www.w3.org/2000/01/rdf-schema#> .
@prefix schema: <http://schema.org/> .
@prefix td: <http://example.org/ns/todo#> .
<http://dbpedia.org/resource/DBpedia>
a owl:Thing ;
a schema:CreativeWork ;
a dbpedia-owl:Software ;
.
# http://dbpedia.org/page/DBpedia
# http://wiki.dbpedia.org/Datasets
# schema:WebPage
# http://schema.org/docs/full.html
@prefix dbp: <http://dbpedia.org/resource/> . URIs)https://github.com/bayandin/awesome-awesomeness
Thing > CreativeWork > http://schema.org/SoftwareApplication
Thing > CreativeWork > Article > http://schema.org/ScholarlyArticle
Thing > CreativeWork > http://schema.org/Code
Thing > CreativeWork > http://schema.org/Dataset
conda create -n notebooks python readline pip ipython-notebook spyder℅run -i # docs: %run?%logstart -o script1.log.pylinguistics [...] Jobs that ask for python and/or database software experience and Linux familiarity. Would it be enough to have a very basic knowledge and maybe be able to do very simple scripts in python?
It's difficult to believe that any degree program does not include any programming.
Python
Install a Python distribution. I like Anaconda.
Databases
Linguistics
Linux
Download a LiveCD and boot it in VirtualBox. Launch a terminal (bash). Run python. Run man python. Run python -m site.
Is this something you wrote and want to know if it's useful, or something you found and are asking what it does? If this is your code, it might be nice if you wrote up more of a description on what this is, why you wrote it, what it's for, and how it might be used.
Yup, sure did. stat and hg said 2011 before I dusted it off.
The stateful algorithm you present looks correct. It appears to be functionally equivalent to streamavg_running_segment ( https://gist.github.com/westurner/98453d572284ef7fa1ff#file-avgs-py-L67 ); with a different API. I'm not certain exactly what complexity class to assign to this problem. Thank you for your input.
Further documentation may be of use.
Thanks! I suppose the objective was to implement a streaming algorithm for calculating the mean of an iterable of numbers.
I've heard about Accumulo Iterators and Spark Streaming, but am not aware of any Python libraries that implement this (or other) simple streaming algorithm.
TL;DR this may or may not be useful for the Python 3.4 stats module or NumPy[Py].
Here's a start, without any charts (yet): https://gist.github.com/westurner/b0f07b71a692d49c9eec
Given a CSV (TSV), compute aggregations with Pandas and NumPy, then generate an HTML report with Bootstrap, JQuery, jquery.tocify, and floathead
[EDIT] To generate (d3js) charts with pandas: https://pandas-docs.github.io/pandas-docs-travis/ecosystem.html#visualization
Neither 0, 1, nor len(series) return the same output as test_61, which does seem overly verbose.
pandas.stats.moments.rolling_mean is documented here, as well: https://pandas-docs.github.io/pandas-docs-travis/computation.html#moving-rolling-statistics-moments
Also, here: http://pandas.pydata.org/pandas-docs/dev/api.html#standard-moving-window-functions
Thanks. Is there a way to do this with pandas.rolling_mean? I didn't try -1 (... What is the windowing function if all observations are equally weighted?)
I searched for "cumulative mean" and "momentary mean".
I wouldn't be surprised if the really good journals starting demanding this kind of thing in the future.
Open Access is a start.
Requiring Open Data - to enable independent statistical analyses [1] - is the next logical step up. [2]
[1] https://en.wikipedia.org/wiki/Blind_experiment#Triple-blind_trials
The Pandas DataFrame support is great, too! https://pandas-docs.github.io/pandas-docs-travis/ecosystem.html#spyder
Here's cheatsheet to map service and chkconfig commands to systemclt: https://fedoraproject.org/wiki/SysVinit_to_Systemd_Cheatsheet
systemctl list-unit-files --type=service(preferred)
ls /etc/systemd/system/*.wants/
Thanks!
Here's (another) cheatsheet for systemd and sysvinit:
http://linoxide.com/linux-command/systemd-vs-sysvinit-cheatsheet/
.
I would like to, eventually, leverage some continuous integration to ensure that RPMs are built properly and tested before release, too.
https://en.wikipedia.org/wiki/Continuous_integration#Principles
https://en.wikipedia.org/wiki/Continuous_delivery
How to create (and recreate) a clean RPM build environment.
Vim, IPython, and SQLAlchemy:
Manually templating SQL with string concatenation is a bad idea; I'd mistype something and not have a backup or a transaction log to undo it.
Writing the inverse operations helps to ensure that I actually know what I'm doing. Migration utilities like alembic and sqlalchemy-migrate support named upgrade and downgrade scripts which can (should) be checked into version control.
One great thing about SQLAlchemy and other ORM layers is that it's possible to manually and automatedly test things out on a local SQLite database with comparable fixtures.
TL;DR TDD DBA.
[EDIT] IPython %logstart [-o] <filename.py> logs input [and output] to a script.
In bash, to get the documentation for . (source), you can use help:
help .
help source
https://en.wikipedia.org/wiki/Euclid's_Elements
That's a real nice table of logarithms you've got there.
* Neither the name of the <organization> nor the
names of its contributors may be used to endorse or promote products
derived from this software without specific prior written permission.
Unintended consequences, I'm sure.
Good question. There are lots of plugins for https://en.wikipedia.org/wiki/Taskwarrior (e.g. http://bugwarrior.readthedocs.org/en/latest/ ) ... https://westurner.github.io/wiki/workflow.html#issue-attributes
[EDIT]
You could also subclass collections.namedtuple and add a ._repr_json_ method:
import collections, json
_Item = collections.namedtuple('Item', 'type lvl task')
class Item(_Item):
def _repr_json_(self):
return json.dumps(self._asdict())
item = Item('mind',1,'Create a todo list for the week')
assert item.lvl == 1
print(item)
print(item.__str__())
print(item._repr_json_())
_ = {'type': 'mind', 'lvl': 2, 'task': 'Catch up on emails'}
item2 = Item(**_)
assert item2.lvl == '2
Consider the following CSV input file::
type, lvl, task
test",0,"test"
mind,1,"Create a to do list for the week"
mind,2,"Catch up on emails"
You could store and work with this type of data with tablib, dataset, Blaze, pandas, pyld:
CSV, JSON, YAML, XLS
Python
https://tablib.readthedocs.org/en/latest/
https://tablib.readthedocs.org/en/latest/tutorial/
CSV, JSON, SQLAlchemy
Python
http://dataset.readthedocs.org/en/latest/
http://dataset.readthedocs.org/en/latest/quickstart.html#running-custom-sql-queries
CSV, JSON, HDF, PyTables, Pandas, SQLAlchemy, MongoDB, Spark
Python + NumPy (C, FORTRAN, ATLAS)
http://blaze.pydata.org/docs/latest/overview.html
http://blaze.pydata.org/docs/latest/quickstart.html
CSV, Excel, HDF, PyTables, SQL, SQLAlchemy, JSON, msgpack, HTML, BigQuery, stata, clipboard
Python + Cython + NumPy (C, FORTRAN, ATLAS)
http://pandas.pydata.org/pandas-docs/stable/
http://pandas.pydata.org/pandas-docs/stable/io.html
http://pandas.pydata.org/pandas-docs/dev/ecosystem.html
JSON-LD
Python
https://github.com/ipython/ipython/wiki/Extensions-Index#matlab
The Python MATLAB bridge enables calling of MATLAB code and functions from an IPython session and adds a%% matlab cell magic, which allows embedding matlab code in IPython notebooks.
http://www.pyzo.org/python_vs_matlab.html
http://www.reddit.com/r/TrueReddit/comments/2fcy9q/the_unstoppable_ti84_plus_how_an_outdated/ck8cfxs
... IPython + SciPyStack, SAGEMath
I'm not sure what you mean by this, but the vm's IP itself is not changing, instead my pfsense's wan ip is changing. So the script hits an internet site that echo's my wan ip and then I use that to update cloudflare. As far as I know I can't update cloudflare through pfsense's dyndns options, but I may be able to do it via a proxy service of some sort...
Ah. There must be a NEWIP event of some sort to hook so that you don't have to wait for the next cron poll to update the DNS record / CDN configuration.
It would be great if pfSense had a webhook for a NEWIP event; while it shouldn't require an external service: https://github.com/saltstack/salt-contrib/blob/master/grains/external_ip.py
[EDIT] IDK how this would work with CARP / bonding / IPv6 (when there are multiple external IPs).
- I run a python script in an hourly cron job on a random home server that checks if my ip has changed and if it has updates my root domain ip entry on cloudlfare via their api (based on this script) (The other option is to run their perl ddclient)
- I also wrote a script that allows me to add subdomains to cloudflare using their api so when I spin up a new service I don't have to login to cloudflare's site to configure it.
[EDIT] https://www.debian.org/doc/manuals/debian-reference/ch05.en.html#_scripting_with_the_ifupdown_system
With this combination I get free valid ssl for my home server's, along with dynamic dns. It should be noted that using cloudlfare with the cdn enabled means I can't just hit <rooturl>:<servicePort> since that points to cloudflare's servers, instead you have to use a subdomain that isn't configured, for example use h.<rooturl> to get by that.
Thanks!
What value a PHP Framework adds:
http://symfony.com/doc/current/book/from_flat_php_to_symfony2.html
How are you testing the framework and the application now?
https://github.com/westurner/wiki/wiki/awesome-python-testing#web-frameworks
https://github.com/TechEmpower/FrameworkBenchmarks
https://en.wikipedia.org/wiki/Comparison_of_web_application_frameworks
https://en.wikipedia.org/wiki/Package_manager
https://en.wikipedia.org/wiki/Template:Package_management_systems
We currently deploy a Java enterprise application on Tomcat.
https://en.wikipedia.org/wiki/Apache_Maven
https://en.wikipedia.org/wiki/Apache_Ivy
Redhat is the linux distro of choice with MySQL as the database.
https://en.wikipedia.org/wiki/RPM_Package_Manager
https://fedoraproject.org/wiki/How_to_create_an_RPM_package
https://en.wikipedia.org/wiki/Yellowdog_Updater,_Modified
To install java we just untar it into a certain file location. To install tomcat we untar into a different file location. MySQL is generally untarred and softlinked to /usr/local/mysql
Most of these source installs are being installed in /usr/local with the exception being Java in /usr/java.
https://en.wikipedia.org/wiki/Comparison_of_open-source_configuration_management_software
For comments, there should be body and body_html attributes: https://github.com/reddit/reddit/wiki/JSON#comment-implements-votable--created
For submissions, there should be selftext and selftext_html attributes: https://github.com/reddit/reddit/wiki/JSON#link-implements-votable--created
TIL about Vasa: https://en.wikipedia.org/wiki/Vasa_(ship) ... Yet another reminder that unit and dimensional metadata are essential to preventing costly errors in science, technology, engineering, and mathematics.
Advantages:
https://en.wikipedia.org/wiki/Dimensional_analysis
It's not clear to me why this was downvoted?
Are dimensional analysis and units of measure not foundational to reducing error in science, technology, engineering, and math?
[EDIT] https://en.wikipedia.org/wiki/Turtle_(syntax)
# schemas
@prefix dtype: <http://www.linkedmodel.org/1.0/schema/dtype> .
@prefix dimension: <http://qudt.org/1.1/schema/dimension> .
@prefix quantity: <http://qudt.org/1.1/schema/quantity> .
@prefix qudt: <http://qudt.org/1.1/schema/qudt> .
@prefix vaem: <http://www.linkedmodel.org/1.2/schema/vaem> .
@prefix voag: <http://voag.linkedmodel.org/1.0/schema/voag> .
# vocabularies
@prefix qudt-dimensionalunit: <http://qudt.org/1.1/vocab/dimensionalunit> .
@prefix qudt-dimension: <http://qudt.org/1.1/vocab/dimension> .
@prefix qudt-quantity: <http://qudt.org/1.1/vocab/quantity> .
@prefix unit: <http://qudt.org/1.1/vocab/unit> .
Context: I am looking at developing RDF support for Pandas (to_rdf, read_rdf). I can see value in both qb: and csvw:, with csvw: clearly being the simpler spec to implement first.
I'm sure there's been discussion of advantages / merits of each ontology.
Disadvantages:
Justification (over CSV):
Is there something of value that you feel you've added here?
I create a vim server for each virtualenv by setting $EDITOR and aliases _edit, e so that
we dotfiles # ~workon (source $VIRTUAL_ENV/bin/activate)
e <path>
opens in that virtualenv's (virtualenvwrapper) vim server.
[EDIT]
https://github.com/westurner/dotfiles/blob/master/etc/ipython/ipython_config.py#L360
https://github.com/westurner/dotfiles/blob/master/etc/bash/10-bashrc.venv.sh#L34
From "ENH: Linked Datasets (RDF)" https://github.com/pydata/pandas/issues/3402 :
```
Ten Simple Rules for Reproducible Computational Research (3, 4, 5, 7, 8, 10)
```
[EDIT]
SeeAlso:
http://pandas.pydata.org/pandas-docs/stable/
pandas is a Python package providing fast, flexible, and expressive data structures designed to make working with “relational” or “labeled” data both easy and intuitive. It aims to be the fundamental high-level building block for doing practical, real world data analysis in Python.
Thank you for your time and input!
It is computationally expensive to determine what is and is not a datetime during JSON deserialization if there is no JSON schema (such as a JSON-LD @context) to indicate which fields to try and map into a (timezone-aware) datetime.date / datetime.datetime / numpy.datetime64 / arrow; I didn't mean to imply that it's not a specific limitation of jsonpickle.
Awesome; thanks!
https://en.wikipedia.org/wiki/Category:Visual_thinking
https://en.wikipedia.org/wiki/Visual_language
https://en.wikipedia.org/wiki/Visual_thinking
https://en.wikipedia.org/wiki/Metaphor
https://en.wikipedia.org/wiki/Image_schema
https://en.wikipedia.org/wiki/Neuroesthetics#Visual_metaphors
"Looking for good music to work to? Try video game soundtracks. The music's designed to provide a stimulating background that doesn't mess with your concentration." https://www.reddit.com/r/LifeProTips/comments/1kgc9k/looking_for_good_music_to_work_to_try_video_game/
What is your objective?
Would an FM-index (e.g. bowtie) be fastest for read alignment?
https://en.wikipedia.org/wiki/FM-index
jsonpickle is useful for many of the same use cases, though datetime support is not easy: https://github.com/jsonpickle/jsonpickle
For many applications, the overhead of JSON-LD serialization is worth the extra time: http://json-ld.org/#developers
[EDIT] A bit OT, but schema.org provides an already-developed (extensible) schema with URIs for JSON-LD attributes: http://schema.org/docs/full.html
Pickle is almost never the correct choice.
If you would like risk execution of arbitrary code in the process space of your Python application, pickle is a good way to do that.
From "DOC: Pickle is unsafe" https://github.com/zopefoundation/zodbpickle/issues/2 :
From http://docs.python.org/2/library/pickle.html#pickle-python-object-serialization
Warning The pickle module is not intended to be secure against erroneous or maliciously constructed data. Never unpickle data received from an untrusted or unauthenticated source.
With pickle, there is no data/code boundary. See: https://en.wikipedia.org/wiki/Separation_of_concerns
You seem to be proposing a use case and rejecting the usefulness of this method for that use case.
As it stands, this is far more useful than adding ad-hoc patterns of '%s' and '%r' in logging messages.
It may even be possible to add a shell-injection filter as a cross-cutting concern, given that this provides a standard key-value API for logging.
https://en.wikipedia.org/wiki/Axiom#Logical_axioms
Does/can/could research findings be derived from extant (Open Data) /r/datasets, given sufficiently appropriate coding (Linked Data URIs) for study/experimental controls?
... Also from https://wrdrd.github.io/docs/consulting/data-science.html#automated-workflows :
- “Ten Simple Rules for Reproducible Computational Research” http://www.ploscompbiol.org/article/info%3Adoi%2F10.1371%2Fjournal.pcbi.1003285
http://www.structlog.org/en/0.4.2/why.html
Structured logging means that you don’t write hard-to-parse and hard-to-keep-consistent prose in your logs but that you log events that happen in a context instead.
https://pypi.python.org/pypi/sphinxcontrib-napoleon supports NumPy-style docstrings:
As of Sphinx 1.3, the napoleon extension will come packaged with Sphinx under sphinx.ext.napoleon.
There's a lot of overlap between Data Science and Bioinformatics.
Bioinformatics requires both Data Science and domain knowledge.
Both Data Science and Bioinformatics require an understanding of data structures and algorithms.
https://en.wikipedia.org/wiki/Data_science
Excellent syllabus; thanks!
I wish more instructors would start with TDD; it'd make grading that much easier ... https://github.com/westurner/wiki/wiki/awesome-python-testing
Suggestion: https://wrdrd.github.io/docs/consulting/knowledge-engineering.html
If you're teaching students with no prior knowledge of programming, shouldn't you be teaching them the basics first? Things like if/else, while, for... Perhaps Boolean logic? I mean, teaching modules like Pillow and pygame require basic knowledge first.
http://scipy-lectures.github.io/intro/language/python_language.html
Traditional methodology has always suggested this would be true; but more sensory exercises are likely to be far more engaging.
Code.org probably has some research to indicate what is most successful with various segments:
Yeah, that is it. I want to make things visible for them. The Turtle Graphics were great for that. They understood things much better than expected.
(Freshman CS ~101) "Introduction to Computing and Programming in Python: A Multimedia Approach" http://www.amazon.com/Introduction-Computing-Programming-Python-Edition/dp/0132923513
The book's hands-on approach shows how programs can be used to build multimedia computer science applications that include sound, graphics, music, pictures, and movies.
Yeah, a VM is a good idea, however I want to make the studying process as easy as possible. I think a VM brings a level of complexity I want to avoid.
You could require a standard SciPy Stack distribution:
Pip works with conda environments.
Further Resources
https://github.com/akahuku/wasavi
wasavi is an extension for Chrome, Opera and Firefox. wasavi transforms TEXTAREA element of any page into a VI editor, so you can edit the text in VI. wasavi supports almost all VI commands and some ex commands.
.1. How big of a handicap is my lack of formal training? What can I do to offset that?
.2. I know I'm just scratching the surface here. To be really employable, what are the required skills and proficiency?
[EDIT]
[/EDIT]
.3. Folks who have successfully transitioned into Web devs w/o formal training or prior experience, could you please share your experience.
[EDIT] Markdown syntax
I've heard that mirrors of PyPI cause a lot of 'downloads'. I wish someone would implement some kind of filtering so the numbers were more realistic.
It would be easy to do periodic sampling in order to establish a baseline.
... [EDIT]
https://github.com/pypa/warehouse/blob/master/warehouse/urls.py
https://github.com/pypa/warehouse/blob/master/warehouse/packaging/views.py#L127
https://github.com/pypa/warehouse/blob/master/warehouse/packaging/db.py#L40
Thanks! How does this compare to mpltools and seaborn?
From http://www.reddit.com/r/Python/comments/2cofg1/ipython_notebook_with_interactive_plots/cjhwf0t :
http://www.w3.org/TR/ld-glossary/#x5-star-linked-open-data :
- ☆ Publish data on the Web in any format (e.g., PDF, JPEG) accompanied by an explicit Open License (expression of rights).
- ☆☆ Publish structured data on the Web in a machine-readable format (e.g., XML).
- ☆☆☆ Publish structured data on the Web in a documented, non-proprietary data format (e.g., CSV, KML).
- ☆☆☆☆ Publish structured data on the Web as RDF (eg Turtle, RDFa, JSON-LD, SPARQL)
- ☆☆☆☆☆ In your RDF, have the identifiers be links (URLs) to useful data sources.
Thank you for this IPython notebook tutorial!
First off, this could be much easier if this was in a structured data format (CSV, JSON, XML, RDFa).
Second, LXML is great; but, occasionally, LXML fails to parse bad markup. BeautifulSoup is much more tolerant of malformed markup.
Third, here are a three resources for helping with web scraping:
https://github.com/taigaio supports Scrum and Kanban
[EDIT]
https://github.com/zopefoundation/zodbpickle/issues/2 (~shelve)
...
https://github.com/jsonpickle/jsonpickle
http://json-ld.org/#developers
https://github.com/digitalbazaar/pyld
...
https://github.com/pydata/pandas/issues/3402 (supports {sqlalchemy, csv, json, HDF5, ...})
https://github.com/dahlia/awesome-sqlalchemy#thin-abstractions (dataset (sqlalchemy, csv, json))
...
http://blaze.pydata.org/docs/latest/data.html (supports {sqlalchemy, csv, json, HDF5, ...})
...
https://github.com/google/protobuf/
https://developers.google.com/protocol-buffers/
http://elasticsearch-py.readthedocs.org/en/master/transports.html#thriftconnection (supports {thrift, JSON,})
http://pyes.readthedocs.org/en/latest/guide/reference/modules/thrift.html#thrift (supports {thrift, JSON,})
Theory / Definitions / Identifiers:
The alternatives to shared memory are distributed memory and distributed shared memory, each having a similar set of issues. See also Non-Uniform Memory Access.
Python APIs:
.
http://www.youtube.com/watch?v=rENyyRwxpHo
"The Laniakea supercluster of galaxies" doi:10.1038/nature13674 (03 September 2014) http://www.nature.com/nature/journal/v513/n7516/full/nature13674.html
So this process is called entailment then? Where the transitive relation properties are sort of merged (although not persisted) to seem to be part of the triple?
(RDFS) Entailment / Materialization / Inferencing
How I learned about this: http://www.usna.edu/Users/cs/adina/research/Rya_ISjournal2013.pdf p.8
4. Query Processing
One of RDF's strengths is the ability to 'infer' relationships or properties. Rya supports
rdfs:subClassOf,rdfs:subPropertyOf,owl:equivalentProperty,owl:inverseOf,owl:SymmetricProperty, andowl:TransitivePropertyinferences. We describe below our methods for query processing.
There are lots of SPARQL implementations:
http://www.w3.org/wiki/SparqlImplementations
http://www.w3.org/2009/sparql/implementations/#sparql11-entailment
There are now SPARQL 1.1 standards for entailment:
http://www.w3.org/TR/sparql11-overview/#sparql11-entailment
http://www.w3.org/TR/sparql11-entailment/
Though many stores support their own implementations:
https://code.google.com/p/arq-inference/ (Jena + ARQ)
http://marmotta.apache.org/platform/sparql-module.html (Marmotta)
https://en.wikipedia.org/wiki/Trigonometry
.
http://blaze.pydata.org/docs/latest/backends.html (pandas, sqlalchemy, postgres, mongodb, pytables, spark, ...)
Thanks!
https://en.wikipedia.org/wiki/List_of_mathematical_symbols
https://en.wikipedia.org/wiki/List_of_mathematical_symbols_by_subject
https://en.wikipedia.org/wiki/Mathematical_operators_and_symbols_in_Unicode
https://en.wikipedia.org/wiki/Greek_letters_used_in_mathematics,_science,_and_engineering
https://en.wikipedia.org/wiki/Notation_in_probability_and_statistics
I'm a huge South Park fan, and last night the first episode of the new season aired. And to my joy, it took the piss out of all of these entrepreneurs who think you can make a business by getting funding for nothing on Kickstarter.
He summed up his company's whole business model as:
Start up
Cash in
Sell out
Bro down
As seen on https://twitter.com/SouthPark/status/515004503104319488
https://en.wikipedia.org/wiki/Turn_on,_tune_in,_drop_out
http://www.fcc.gov/files/ecfs/14-28/ecfs-files.htm
Data
XSD
Description of Fields
How do they have access to "virtually all" of the comments?
[EDIT] "Request: The "Sunlight Foundation" analyzed FCC comments for net neutrality: is anyone able to find an existing dataset of the comments?" http://www.reddit.com/r/opendata/comments/2fdemj/request_the_sunlight_foundation_analyzed_fcc/
Low man on the totem pole of course, same as it has always been.
"Socialism for the rich, capitalism for the poor" https://en.wikipedia.org/wiki/Corporate_welfare#.22Socialism_for_the_rich.2C_capitalism_for_the_poor.22
[EDIT]
HARM: https://en.wikipedia.org/wiki/Suppression_of_dissent
VALUE: Free flow of information is the essential feedback mechanism of a functional democracy.
VALUE: Diversity
VALUE: httpS://en.wikipedia.org/wiki/Fourth_branch_of_government
That's just how they compete. Use their power to destroy their rivals legislatively rather than beating them in the marketplace.
No, that's illegal misappropriation.
This is a company that gives cupcakes to the agency which regulates it, every year.
If the first option is cheaper and equally effective, capitalism says it's the best option.
And who pays for the externalities?
LPT: Use http://schema.org/Date (schema:Date) in RDFa (HTML + RDFa @content tags and attributes + RDF subjects, predicates, and objects), JSONLD, {...}
When you run pip install --upgrade -r requirements.txt, does it not satisfy the constraints specified in the requirements file (possibly output from pip freeze)?
Would file permissions be more helpful in that case? (When it's not feasible to simply create a new virtualenv and install the modified set of requirements)
Or would nesting of requirements files accomplish such a dependency pinning objective?
Here's a requirements.lock discussion: https://github.com/pypa/pip/issues/1175
Here's an article about pip-compile: http://nvie.com/posts/better-package-management/ ([EDIT] requirements.in)
Is this why conda requires pycosat: http://conda.pydata.org/docs/#requirements
https://pip.readthedocs.org/en/latest/user_guide.html#requirements-files
This is a valid pip requirements file:
pkg1
pkg2
pkg3>=1.0,<=2.0
[EDIT] Create a virtualenv, pip install, run adequate tests
Cool; thanks!
http://www.structlog.org/en/latest/logging-best-practices.html (log to txt, JSON)
https://docs.python.org/2/library/functools.html#functools.wraps (log args, kwargs)
https://github.com/westurner/dotfiles/blob/master/etc/usrlog.sh (log shell input with date time and a session id)
string.Template may compile templates once: https://docs.python.org/2/library/string.html
Learn to code, build an app, maintain releases (e.g. git hubflow, semver.org), package for each platform, profit
[EDIT]
Great write-up; thanks!
https://docs.python.org/2/library/stdtypes.html#string-formatting
http://legacy.python.org/dev/peps/pep-3101/ (EDIT)
https://docs.python.org/3/library/string.html#formatstrings (EDIT)
string concatenation -> string interpolation -> XSS, ___ injection, http://cwe.mitre.org/top25/ :
... Markdown, ReStructuredText
http://ipython.org/ipython-doc/dev/install/install.html#readline says:
# for OSX
pip install gnureadline
http://www.reddit.com/r/Python/comments/2bv2op/help_me_move_from_r_to_python/cj9hhk0 (IPython, scipy-lectures, scientific-python-lectures)
Try pip3 install readline? ... http://docs.continuum.io/anaconda/pkg-docs.html
wasavi is an extension for Chrome, Firefox, and Opera. wasavi changes a textarea element to virtual vi editor which supports almost all the vi/ex commands.
always ... something like topical cross-referencing (https://westurner.github.io/redditlog/, https://github.com/westurner/redem)
First, I'm not sure what you're getting at by quoting or linking-to all the Wikipedia articles...
Just taking notes, thanks!
"Solar steam generation by heat localization" doi:10.1038/ncomms5449 (2014) http://www.nature.com/ncomms/2014/140721/ncomms5449/full/ncomms5449.html
In particular, the replacement of incandescent light bulbs with compact fluorescent lamps can have a drastic effect on energy consumption.
https://en.wikipedia.org/wiki/Photosensitive_epilepsy#Fluorescent_lighting
Is it possible to produce graphene out of air?
https://en.wikipedia.org/wiki/Graphene == Carbon (one atom thick)
'''TIL "that 95 percent of a tree is actually from carbon dioxide"''' http://www.reddit.com/r/todayilearned/comments/29e1ju/til_that_95_percent_of_a_tree_is_actually_from/
usually <15% of the energy produced is used during the process (albeit, the energy produced (read: (syn)gases) are usually used for subsequent loads after being cleaned up ... and the 'waste' heat is used for the extra-drying of the upcoming load to be gasified ... larger capacity facilities usually end up with a 90%+ amount of energy being made available
http://en.wikipedia.org/wiki/Syngas ("synthesis gas")
some biomass feedstocks are much more energy dense than others [...] leafier plants... or, plants, or parts of plants... that are 'looser' or less carbon-dense (read: leaves vs branches vs trunks, etc) will break down into a gas much faster & easier
https://en.wikipedia.org/wiki/Biomass
https://en.wikipedia.org/wiki/Energy_crop
but, diesel engines are like canons essentially...
https://en.wikipedia.org/wiki/Diesel_exhaust
https://en.wikipedia.org/wiki/List_of_IARC_Group_1_carcinogens#Mixtures (does this apply to alternative fuels?)
carbon that was otherwise pulled out of the atmosphere during the plants 'respiration'
lab exercise: https://en.wikipedia.org/wiki/Respirometry
also, there's a lot of CO in flue gases... same in tail pipe emissions of cars, hence catalytic converters... which specifically 'up-convert' CO into CO2
https://en.wikipedia.org/wiki/Catalytic_converter
... hence tail pipes have a lot of water coming out of them... at that... N2, O2, H2O and CO2 are all great for plants. [...] at that, these can be 'fed' into greenhouses, increasing the yields pretty damn significantly ... again, depending on plant type but... yield increases of 300-400% are pretty common, and as high as 800% shouldn't be overly surprising... vs a control outside... of course, this just increases plant yield and, thus, carbon within the plant.. which can be used to make biochar and, thus, graphene. ...and, in the process, also produce more gases ... more plant = more gases ... 'fruits' tend to be more plentiful as well... including hydrocarbons or bio-oils... as such... you end up converting a lot of energy into a usable form... that's ever-increasingly a straight-swap for our current energy infrastructure ..
https://en.wikipedia.org/wiki/Greenhouse_gas#Removal_from_the_atmosphere_.28.22sinks.22.29
https://en.wikipedia.org/wiki/Oxygen_mask
Lastly, separate from all of that ... yes, you can use flue stack emissions or even just atmospheric carbon for graphene production in essentially the same way... just capture the CO2, crack it so that it's C & O2 or C & o1 & o1 ... and, refine it out so that they're separate .. and, then do what you'd like with the C ... but, this is not anywhere near as dense as biochar is... as well, it would require energy, vs biochar's creation process resulting in excess energy (vs what's needed to make it)
https://en.wikipedia.org/wiki/Biochar
Thank you so much!
https://en.wikipedia.org/wiki/Toxoplasmosis
Up to a third of the world's human population is estimated to carry a Toxoplasma infection.
[...]
Recent research has also linked toxoplasmosis with attention deficit hyperactivity disorder, obsessive compulsive disorder, and schizophrenia.
I wouldn't say the title is inaccurate. The 95-100% certainty figure is from the IPCC Fifth Assessment Report, not the research in question:
"Climate Change 2013: The Physical Science Basis" http://www.ipcc.ch/report/ar5/wg1/
I'm a bit beyond my level of comprehension here.
How does the process you describe (thanks!) compare with http://www.acs.org/content/acs/en/pressroom/newsreleases/2014/august/could-hemp-nanosheets-topple-graphene-for-making-the-ideal-supercapacitor.html ?
I suppose I was thinking more of a process which could work before/in a smokestack; producing graphene air filters from waste carbon dioxide onsite.
TIL about http://en.m.wikipedia.org/wiki/Biochar (thanks!)
How would one determine comparative net energy needs for these different approaches?
Helpful for developing /r/datascience skills to be listed (linked to!) on a social network profile: https://github.com/datasciencemasters/go
My concern is with pure statisticians and data scientists moving into HR big data. I am seeing it happen right now. They don't understand psychological data and because they are purely data miners they end up with all kinds of conclusions that don't really represent the data accurately.
I caught one presentation where they dissected a likert question into categories using chi-square and then used that 1 response on the likert scale as groups and talked about how they responded to other items. Apparently a 3 is completely different than a 4 or a 2 in a likert scale..........I never knew!!
So there wasn't enough metadata to indicate that it was a scalar variable and not a categorical variable; in order to perform a triple-blind (domain independent) analysis?
[EDIT] http://en.wikipedia.org/wiki/Likert_scale#Scoring_and_analysis
.4. Build the service using agile and iterative practices
.6. Assign one leader and hold that person accountable
https://en.wikipedia.org/wiki/Accountability
.10. Automate testing and deployments
https://en.wikipedia.org/wiki/Continuous_integration#Principles
https://en.wikipedia.org/wiki/Continuous_delivery
.12. Use data to drive decisions
https://en.wikipedia.org/wiki/Data_driven
https://en.wikipedia.org/wiki/Data_science
.13. Default to open
https://en.wikipedia.org/wiki/Open_science
- Understand what people need
- Address the whole experience, from start to finish
- Make it simple and intuitive
- Build the service using agile and iterative practices
- Structure budgets and contracts to support delivery
- Assign one leader and hold that person accountable
- Bring in experienced teams
- Choose a modern technology stack
- Deploy in a flexible hosting environment
- Automate testing and deployments
- Manage security and privacy through reusable processes
- Use data to drive decisions
- Default to open
A helpful set of criteria to evaluate existing and proposed solutions.
For each item:
Lack of (RDF + JavaScript) GUI framework integrations?
I really think it's because we just can't comprehend how much more useful structured linked data is than a document raster-encoded into PDF. Which is ironic, because of the amount of time we all spend with HTTP, HTML, and URIs/URLs.
https://en.wikipedia.org/wiki/Linked_data#Principles :
Use URIs to denote things.
Use HTTP URIs so that these things can be referred to and looked up ("dereferenced") by people and user agents.
Provide useful information about the thing when its URI is dereferenced, leveraging standards such as RDF, SPARQL.
Include links to other related things (using their URIs) when publishing data on the Web.
http://www.w3.org/TR/ld-glossary/#x5-star-linked-open-data (http://5stardata.info/):
- ☆ Publish data on the Web in any format (e.g., PDF, JPEG) accompanied by an explicit Open License (expression of rights).
- ☆☆ Publish structured data on the Web in a machine-readable format (e.g., XML).
- ☆☆☆ Publish structured data on the Web in a documented, non-proprietary data format (e.g., CSV, KML).
- ☆☆☆☆ Publish structured data on the Web as RDF (eg Turtle, RDFa, JSON-LD, SPARQL)
- ☆☆☆☆☆ In your RDF, have the identifiers be links (URLs) to useful data sources.
...
Moar helpful unlabeled edges:
[EDIT]
[EDIT]
RDF+JS (GUI Applications)
"The Pragmatic Programmer: From Journeyman to Master" (1999) https://en.wikipedia.org/wiki/The_Pragmatic_Programmer
Micro Python is a lean and fast implementation of the Python 3 programming language that is optimised to run on a microcontroller.
The price of textbooks has increased 82 percent during the last decade, a new report finds.
...
Not Mint, but you could easily work with a list of numbers in /r/ipython notebook (e.g. with Pandas http://pandas.pydata.org/pandas-docs/stable/10min.html). Anaconda is one easy way to get IPython and Pandas: https://store.continuum.io/cshop/anaconda/ (All FREE)
[EDIT] For double entry accounting, http://en.wikipedia.org/wiki/GnuCash is also great; though US banks, unfortunately, tend to develop proprietary interchange mechanisms that require periodic manual download and importing into accounting software.
Meanwhile the Raspberry Pi is shipping with Mathematica for $35 apiece which leads me to think that a $120 calculator running Mathematica is probably possible in the near future.
TI-84: $120
Raspberry Pi: $35 (with Mathematica)
/r/ipython notebook: FREE
New requirement: repeatable, reproducible analyses
See also: "I think we should do away with TI calculators, and math students should use calculators which are nothing more than hand-held python shells, with something like matplotlib for plotting." http://www.reddit.com/r/Python/comments/20i2ga/i_think_we_should_do_away_with_ti_calculators_and/#cg3tyr9 ... /r/ipython
It's kind of problematic:
foo.gat = 1
foo.git = 2
foo.get = 3 #oops, overwritten dict.get
This. (... Requires an additional lookup of class attrs for inconsistent syntax.)
http://legacy.python.org/dev/peps/pep-0020/ :
In the face of ambiguity, refuse the temptation to guess.
There should be one-- and preferably only one --obvious way to do it.
http://en.wikipedia.org/wiki/Fluoxetine <---> { Neuroplasticity, Serotonin }
So, this [string folding] optimization is not (yet?) a pull request to pydata/pandas?
How does this compare with native pandas.sql methods? Are these safe optimizations? Are they already merged upstream?
Also not Python, but would be helpful for anyone writing a book:
https://en.wikipedia.org/wiki/Calculus
https://en.wikipedia.org/wiki/Python_(programming_language)
Not Python, but still very helpful:
(Waiting for an email from python-ideas to come through, so I can respond to the mailman archive, because mailman 3 is still in beta *)
+1 for static typing for certain problems.
MyPy
Static type checking at compile time (linting) looks really neat.
Do we need a separate approach for actual type assertions at runtime? Will that ever be in scope for mypy?
Existing Uses for Annotations
PyContracts
https://andreacensi.github.io/contracts/#introduction-to-pycontracts :
Contracts can be specified in three ways:
.1. Using the
@contractdecorator:
@contract(a='int,>0', b='list[N],N>0', returns='list[N]')
def my_function(a, b):
...
.2. Using annotations (for Python 3):
@contract
def my_function(a : 'int,>0', b : 'list[N],N>0') -> 'list[N]':
# Requires b to be a nonempty list, and the return
# value to have the same length.
...
.3. Using docstrings, with the
:type:and:rtype:tags:
@contract
def my_function(a, b):
""" Function description.
:type a: int,>0
:type b: list[N],N>0
:rtype: list[N]
"""
...
[EDIT] Markdown, http://www.mypy-lang.org/examples.html
Your 1st link is broken.
http://blaze.pydata.org/docs/latest/
The stackoverflow one doesn't have an answer.
Are you sure? There are links in the comments.
Thanks!
setw -g mode-mouse on
set -g mouse-select-window on
set -g mouse-select-pane on
set -g mouse-resize-pane on
What does "editable" mean here? It's not clear to me.
From http://www.reddit.com/r/Python/comments/21itpp/what_is_the_proper_way_to_mix_regular_python/cgdgaxh :
http://www.pip-installer.org/en/latest/reference/pip_install.html#editable-installs
pip install -e git+ssh://git@github.com/pyqtgraph/pyqtgraph#egg=pyqtgraphClones the sourcecode from GitHub into
./src/pyqtgraph(with git over SSH) and then creates apyqtgraph.egg-linkfile insite-packagescontaining the path to the cloned source; which functions like a cross-platform symlink.python -m siteShould list the source code directory in
site-packages/pyqtgraph.egg-link.
Cool!
/u/SQLZane mentioned a number of additional potential factors to consider.
It would be cool if:
we could download this analysis as code
e.g. as an /r/IPython notebook: https://github.com/ipython/ipython/wiki/A-gallery-of-interesting-IPython-Notebooks#pandas-for-data-analysis
An example (with an interactive Plotly chart): http://www.reddit.com/r/Python/comments/2cofg1/ipython_notebook_with_interactive_plots/
[EDIT]
If you can rely on users having pip configured to pull from an index server (default: pypi.python.org) which has a package named what you have in your requirements.txt, something like django-extensions==1.3.10 in requirements.txt should work fine.
Sometimes, I'll add a requirements-dev.txt with a -e <vc>+<uri> editable line for everything, in manually-topologically-sorted order.
There's been discussion of supporting requirements.lock.txt files (to separate version specifiers from just package names in requirements.txt).
To install a specific version of a Python package (with a setup.py) from GitHub with pip:
Option 2c
Install from a git tag and/or a GitHub release: https://github.com/django-extensions/django-extensions/releases
$ pip install https://github.com/django-extensions/django-extensions/archive/1.3.10.tar.gz
# - or -
$ pip install https://github.com/django-extensions/django-extensions/archive/1.3.10.zip
Option 3b
Install as editable (git clone, cd, python setup.py develop).
Add a version specifier to the editable URI:
$ pip install -e git+https://github.com/django-extensions/django-extensions.git@1.3.10#egg=django-extensions
https://en.wikipedia.org/wiki/Impact_factor
https://en.wikipedia.org/wiki/Plotly
https://en.wikipedia.org/wiki/IPython
Thanks for the parsing code! A caching REST API would be great!
http://www.w3.org/TR/ld-glossary/#x5-star-linked-open-data :
- ☆ Publish data on the Web in any format (e.g., PDF, JPEG) accompanied by an explicit Open License (expression of rights).
- ☆☆ Publish structured data on the Web in a machine-readable format (e.g., XML).
- ☆☆☆ Publish structured data on the Web in a documented, non-proprietary data format (e.g., CSV, KML).
- ☆☆☆☆ Publish structured data on the Web as RDF (eg Turtle, RDFa, JSON-LD, SPARQL)
- ☆☆☆☆☆ In your RDF, have the identifiers be links (URLs) to useful data sources.
And it would likely be able to do so with unmatched patience and skill. The human student would be able to ask endless questions and repeatedly be told the same concepts without the AI ever getting mad or irritated with the students in regards to their ability to learn.
https://en.wikipedia.org/wiki/Spaced_repetition
What sorts of educational objectives could narrow and general AI help with?
https://en.wikipedia.org/wiki/Bloom%27s_taxonomy#See_also
Am I expecting too much of humanity?
[EDIT]
itertools.izip(_longest) may be faster:
As /u/casualbon mentioned, DataFrame.apply is likely faster than tuple unpacking with multiple function call overhead:
General performance resources:
Separating the computation from the data (e.g. with apply) makes it easier to push a computation kernel to the data, rather than streaming the data through the computation:
... Fortran:
... Weather:
This made RDF fairly simple to understand, IMHO: https://rdflib.readthedocs.org/en/latest/intro_to_creating_rdf.html
For REST (as a resource/service facade for SPARQL), the newer (now, W3C) spec is Linked Data Platform (LDP): http://www.w3.org/TR/ldp/
LDP also abstracts SPARQL queries into HTTP REST verb-able collections, which can have server-side paging limits (potentially limiting the impact of queries with clauses like LIMIT 100000).
Linked Data is the use of RDF:SeeAlso and OWL:SameAs relationships (amongst others) to publish data and interlink the instances between different data sets. (For example, from geonames to dbpedia) http://linkeddata.org/
RDF:seeAlso and OWL:sameAs are frequently recurring predicates. There are many RDF predicates (URIs) which link subjects (URIs) and objects (URIs): http://lov.okfn.org/dataset/lov/ .
Of particular interest is Linked open data, which is published with an open license. http://lod-cloud.net/
http://www.w3.org/TR/ld-glossary/#x5-star-linked-open-data:
- ☆ Publish data on the Web in any format (e.g., PDF, JPEG) accompanied by an explicit Open License (expression of rights).
- ☆☆ Publish structured data on the Web in a machine-readable format (e.g., XML).
- ☆☆☆ Publish structured data on the Web in a documented, non-proprietary data format (e.g., CSV, KML).
- ☆☆☆☆ Publish structured data on the Web as RDF (eg Turtle, RDFa, JSON-LD, SPARQL)
- ☆☆☆☆☆ In your RDF, have the identifiers be links (URLs) to useful data sources.
Many of these would be helpful in the /r/pystats sidebar
/r/pystats (sidebar)
Setup Pip, Conda, Anaconda
Install Conda -- http://conda.pydata.org/docs/index.html
pip install conda
Install IPython -- https://github.com/ipython/ipython/wiki/A-gallery-of-interesting-IPython-Notebooks
conda install ipython ipython-notebook ipython-qtconsole
Install Spyder IDE (and Qt) -- https://code.google.com/p/spyderlib/
conda install spyder
(optional) Install anaconda -- http://docs.continuum.io/anaconda/install.html , http://docs.continuum.io/anaconda/pkg-docs.html
conda install anaconda
IPython
Pandas
Statsmodels
Scikit-learn
Categorical assertions:
https://en.wikipedia.org/wiki/Computational_linguistics
https://en.wikipedia.org/wiki/Information_theory
https://en.wikipedia.org/wiki/Metric_(mathematics) (Distance)
Armchair linguist here. The question seems to be about distance between words. There must be a distinction between morphemically similar (e.g. cognates) and semantically similar (car, truck, bicycle).
https://en.wikipedia.org/wiki/Morpheme :
https://en.wikipedia.org/wiki/Semantic_similarity#Taxonomy
https://en.wikipedia.org/wiki/Memetics#Terminology
https://en.wikipedia.org/wiki/Phoneme#Assignment_of_speech_sounds_to_phonemes
[EDIT] http://research.google.com/pubs/NaturalLanguageProcessing.html
http://research.google.com/pubs/pub42526.html
[EDIT]
From "Data sets to 'practise' with while studying machine learning?" http://www.reddit.com/r/MachineLearning/comments/1xsx9n/data_sets_to_practise_with_while_studying_machine/cfeccln :
[...]
"Mathematics for Computer Science" http://courses.csail.mit.edu/6.042/spring14/mcs.pdf
https://stellar.mit.edu/S/course/6/sp14/6.042/ > Materials > Readings
[EDIT] #OER
Resources
The sidebars of these subreddits list some great resources:
Here are a few more for NumPy, SciPy, Scikit-learn, and statsmodels:
Tools
Spent an hour and a half here at work just trying to do basic things like read a .py file to see its contents.
Which editor are you working with?
Print file contents with IPython:
!cat ./filename.py
/r/ipython can display objects with _repr_<format> methods (PNG, HTML, etc.) with the display system: http://nbviewer.ipython.org/github/ipython/ipython/blob/master/examples/Notebook/Display%20System.ipynb
For example, this will load a CSV file into a dataframe and display it as HTML in IPython notebook: http://nbviewer.ipython.org/github/jvns/talks/blob/master/pydatanyc2013/PyData%20NYC%202013%20tutorial.ipynb :
people = pd.read_csv('tiny.csv')
people
To print to a string:
print(people.to_string())
Excel
There may be a data entry grid with topologically sorted evaluation of un-named functions which works within the IPython notebook interface.
Pandas (conda install pandas) can read/write CSV, XLS, XLSX, SQL tables and queries with SQLAlchemy, BigTable, HDFS, and a number of other formats: http://pandas.pydata.org/pandas-docs/stable/io.html
Dataset (pip install dataset) makes working with CSV, JSON, SQLAlchemy {...} very easy and relatively schema-less: http://dataset.readthedocs.org/en/latest/
Spyder (conda install spyder) is an open IDE with a built-in IPython console: https://code.google.com/p/spyderlib/
It looks like Pandas DataFrame support will be in Spyder 2.3.1: https://bitbucket.org/spyder-ide/spyderlib/pull-request/31/implementation-of-pandas-dataframe-issue/diff
With each thing I try to do I go to 5.7 urls on average trying to figure out how to change my directory to open the file so I can read it.
Change directory with IPython:
!cd <path>
Is this a request for solutions, empathy, or a negative attack ad?
"PLOS Computational Biology: Ten Simple Rules" http://www.ploscollections.org/article/browse/issue/info%3Adoi%2F10.1371%2Fissue.pcol.v03.i01
"Ten Simple Rules for Reproducible Computational Research" http://www.ploscollections.org/article/info%3Adoi%2F10.1371%2Fjournal.pcbi.1003285
http://datasciencemasters.org/
https://www.class-central.com/search?q=statistics
https://stats.stackexchange.com/questions/170/free-statistical-textbooks
[EDIT] https://en.wikipedia.org/wiki/Randomized_controlled_trial#Classifications_of_RCTs
tl;dr: Trying to turn a python project in to a simple .exe and having an endless amount of headaches.
https://pypi.python.org/pypi/esky :
esky: keep frozen apps fresh
Esky is an auto-update framework for frozen Python applications. It provides a simple API through which apps can find, fetch and install updates, and a bootstrapping mechanism that keeps the app safe in the face of failed or partial updates.
Esky is currently capable of freezing apps with py2exe, py2app, cxfreeze and bbfreeze. Adding support for other freezer programs should be straightforward; patches will be gratefully accepted.
In summary, you ultimately have two options:
- Do what you would do otherwise, but also collect data.
Absolutely.
(datetime, [(feature_name, feature_value),], "text") with type information (e.g. as CSV, JSON, JSON-LD that can be mapped to an RDF schema).In 10, maybe 20 years you may be able to make some interesting conclusions from this data.
In clinical practice, I would imagine that a physician would be doing something like A/B testing and root-cause analysis (like building a decision tree), and multi-armed bandit, with pharmacological certification.
Near-term optimization objectives:
Your question is also ill-posed, in the sense that you can't show the variable doesn't help (with frequentist analysis).
Is this like building a decision tree?
http://en.wikipedia.org/wiki/Decision_tree_learning#Information_gain
http://en.wikipedia.org/wiki/Receiver_operating_characteristic
[EDIT] http://scikit-learn.org/stable/tutorial/machine_learning_map/
With a http://en.wikipedia.org/wiki/Randomized_controlled_trial , n > 1:
A randomised controlled trial (or randomised control trial; RCT) is a specific type of scientific experiment, and the gold standard for a clinical trial. RCTs are often used to test the efficacy or effectiveness of various types of medical intervention within a patient population. RCTs may also provide an opportunity to gather useful information about adverse effects, such as drug reactions.
Collect links from Medline and other sites
Overlapping sets of reported "adverse events" with incidence rates
[Overlapping] sets of physical http://en.wikipedia.org/wiki/Pathway#See_also
feature_x__and__feature_y[EDIT]
... http://journals.plos.org/ploscompbiol/article?id=10.1371/journal.pcbi.1003285
Which is a long way of saying IANAD and IDK.
[EDIT]
In terms of http://en.wikipedia.org/wiki/Personalized_medicine , are you seeking to develop models to:
Causality with few samples is hard to justify, but logical pattern sequence identification may be helpful.
Sort of like looking for a certain chord with characteristic resonance.
https://en.wikipedia.org/wiki/Receiver_operating_characteristic#Basic_concept
[EDIT] https://en.wikipedia.org/wiki/Graphical_model
[EDIT] https://en.wikipedia.org/wiki/Symbolic_regression
I can easily come up with 10 better ways to handle the examples given in the post. I'm sure they could too. What went wrong?
How could this be more simply modeled?
Is this reification, or is there a more descriptive term for the diagram presented?
"Quantum droplets of electrons and holes" (Nature)
http://www.nature.com/nature/journal/v506/n7489/full/nature12994.html
" Graph the data. If you cannot see the effect with your bare eyes, it's not worth caring about." Valid statement?
The trouble is knowing what to plot. Even for small effects in high dimensional data, if an effect is real then there is some visualization of the data that will make it apparent to the eye.
If you need to know what to plot before applying the heuristic, you are not using the heuristic.
Fair enough. Had I elaborated I would have said that the statement is nearly useless as guide to the proper analysis, but it is helpful as a post-hoc check that the analysis is reasonable.
With two variables scaled to the viewing area, sure.
With 3+ variables, I don't know what the probability of choosing the most visually helpful projection into a 2-dimensional plane is.
http://blaze.pydata.org/docs/dev/backends.html#pandas
http://numba.pydata.org: LLVM JIT
http://pandas.pydata.org/pandas-docs/stable/enhancingperf.html: Cython
http://docs.continuum.io/iopro/index.html :
IOPro loads NumPy arrays (and Pandas DataFrames) directly from files, SQL databases, and NoSQL stores, without creating millions of temporary, intermediate Python objects, or requiring expensive array resizing operations.
http://www.haskell.org/haskellwiki/Applications_and_libraries/Mathematics#Linear_algebra
http://www.haskell.org/haskellwiki/Applications_and_libraries/Theorem_provers
http://www.haskell.org/haskellwiki/Applications_and_libraries/Concurrency_and_parallelism
...
"Ask HN: What is the best functional programming language for data science?" https://news.ycombinator.com/item?id=6980260
"Thank you for your time."
Nice!
https://github.com/jrjohansson/version_information/blob/master/version_information.py performs a subset of these functions with _repr_<fmt>_ functions and escaping.
This is a description of a theory-driven model. You start with a theory or observation about how the world works, assuming that theory is true, what predictions can you make; or in this case, what model can you build? If the theory is correct, the theory model will fit nicely.
https://en.wikipedia.org/wiki/Randomized_controlled_trial
https://en.wikipedia.org/wiki/Blind_experiment#Triple-blind_trials
The problem with what you're describing is that it tells you nothing about why the model is specified the way it is. Sure if you train and build on split half models, you'll get a great model fit. The problem is that you'll have no idea what the model is saying, especially if it spits back a model with nonsensical parameters (like correlated error terms).
https://en.wikipedia.org/wiki/Pathway#See_also
The Google flu model is a great example of the downfall of algorithm based model building. Sure the model fits well when it fits. But you have no idea what external factors you're omitting that may cause the model to fail. For example, ice cream and murder rates are highly correlated.
"Spurious Correlations" demonstrates quite a few peculiar correlations.
Another great example of correlation and causal relations: Heart medication <---> heart disease.
... Domain data/information/knowledge/wisdom and logical proofs.
A training model would find that correlation and model it really we'll. but what a theory driven model would tell you is that this correlation is driven by heat - ice cream and murder rates both increase with temperature. If something occurred to change that relationship, knowing WHY the relationship exists would help explain when the model will fail and, more importantly, why it's failing
So, the difference here is that a theory-driven model allows us to postulate about root causes (like latent causal variables)?
Probabilistic logic may be a topic more fit for an AI discussion; but I wonder where the optimal boundary between attempting to confirm (necessarily biased) theory with arbitrarily defined thresholds of confidence and significance and making inference from the data and more data is.
I tend to think about this in physical cognitive terms like relative and absolute (Earth North) bearings (useful for wayfinding and orienteering).
You need to start with a specified model a priori. You build a model based on your readings of the literature and by using existing theories. You do not fish around for the perfect model as this increases your rate of false positives and is grossly an unethical treatment of the data.
What? Could you demonstrate how what you are describing is not confirmation bias? If this were a proof, how would you inductively justify priors 'inferred' from select literature that says that the world is flat?
If you have a bunch of data and don't know what model you're building, you need to go back and hit the books because you've out the cart before the horse. Figure out what you're trying to test and test it. Don't collect a bunch of data and find the best fitting model. This is essentially p-hacking.
What you seem to be describing is a walk around a (possibly local) hypothesis extrema.
I admire your civil tone, a standard that I have not lived up to recently in a lot my comments. Thanks, and cheers.
Peace.
Re: ANOVA, that was my mistake; ANOVA is really just the GLM anyway (as is multiple regression), so I tend to use a lot of these terms interchangeably, which is obviously not good practice.
From http://en.wikipedia.org/wiki/General_linear_model :
The general linear model incorporates a number of different statistical models: ANOVA, ANCOVA, MANOVA, MANCOVA, ordinary linear regression, t-test and F-test. The general linear model is a generalization of multiple linear regression model to the case of more than one dependent variable.
http://en.m.wikipedia.org/wiki/Comparison_of_general_and_generalized_linear_models is also interesting.
OLS just solves for parameter estimates, it has no feature selection step exactly. So, it is up to the user to specify the features.
This is where prior biases creep in.
I agree that exploration of ML algorithms could be helpful, and I should have said so in my post (I have the nasty habit of just highlighting where I disagree with people, rather than highlighting points on agreement; it's an irksome quirk of my training, personality, or both).
Counterexamples abound.
In particular I would refer the OP to Zelazo's late 90's-early 2000's meta-analysis of the A-not-B error which is in many cases analogous to the task OP is analyzing. Zelazo used a neural network to do the meta-analysis, so a case could be made for it here, too.
Thanks for the reference. I suppose the random seed would need to be recorded with (recurrent) nets.
Pushing for the use of PCA/ICA/etc might be a bit harder, since there isn't prior art to work from. In fact, I'm not aware of a single meta-analytic study using those approaches, so it's likely that some basic statistics papers would have to be published on this first.
I'd have to dig through arxiv and Google Scholar for relevant matches.
Personally, if the OP were to be interested in pursuing some more complex techniques, I'd recommend a hierarchical Bayesian meta-analysis (not nearly as hard as it sounds).
http://scikit-learn.org/stable/modules/classes.html#module-sklearn.cluster
URIs for study designs, controls, and blinding could be helpful. I reviewed the PRISMA statement checklist recently, IIRC.
But, given the quality of reviews that OP encountered (and alas that are standard in psychology; there is a generational war going on), these are unlikely to result in a published paper in anything less than a year or so of back and forth, waiting on the availability of reviewers with the requisite expertise, etc.
This is why I feel it is appropriate to publish just data with parenthetical summarizations in PDFs, for web comments (e.g. with OpenAnnotation).
These are all cool techniques but you seem to have dived into the deep end without realizing this is problem is solvable in the baby pool, which makes me think you're in over your head (forgive the extended metaphor).
That must be the case.
For example, independence between variables is not an assumption of ANOVA (you're thinking of independence of errors, or possibly collinearity [which as noted above is a problem only at high levels of collinearity]).
Who mentioned ANOVA?
Another example is your link to an arcane technique (combinatorial optimization) seemingly without realizing the OP is just doing OLS multiple regression.
Does OLS identify combinations of inverse features?
Forgive me, but it seems like you're missing training in basic statistics, and are plowing through really unusual techniques without a solid grounding. This makes you not the ideal candidate to be providing advice.
I suppose one could look at each pixel at a time.
I will admit to having voted you down for these reasons; I've removed that vote, but I hope you see my intention. The issue was that your suggestion is overly-complex, seemingly misinformed, and distracting from the suggestions of others who appear to have greater training. This is not always apparent to the OPs themselves, so it can be helpful for others to vote unhelpful things down.
Thank you for your feedback. I should have been more clear that I feel that OLS is inadequate; and further exploration into standard machine learning algorithms (like PCA and ICA) may or may not be necessary OR helpful.
"You have 30 minutes to teach business folk about data science - go" http://www.reddit.com/r/datascience/comments/1xxsvh/you_have_30_minutes_to_teach_business_folk_about/cffzl9b
"I'm a student interested in the Data Science field, any tips?" http://www.reddit.com/r/datascience/comments/21d5a9/im_a_student_interested_in_the_data_science_field/cgcuskp
- "The Open Source Data Science Masters" http://datasciencemasters.org/
- "Ten Simple Rules for Reproducible Computational Analysis" http://www.reddit.com/r/statistics/comments/1rt7u3/ten_simple_rules_for_reproducible_computational/
"The Fourth Bubble in the Data Science Venn Diagram: Social Sciences (DSA)" http://www.reddit.com/r/psychology/comments/1zd7uk/the_fourth_bubble_in_the_data_science_venn/
Exactly my point. Thank you. I was correct for the point I was trying to make, AND what's-his-name was correct for pointing out an important qualification to my point.
https://en.wikipedia.org/wiki/Principle_of_maximum_entropy#Maximum_entropy_models
We can work collaboratively.
+1 ... w/ /r/pystats tooling for this problem:
(anaconda + /r/ipython (also works with R) ... https://plus.google.com/+KayurPatel/posts/P89KQiKdXBk)
OLS:
http://statsmodels.sourceforge.net/devel/index.html#table-of-contents
http://statsmodels.sourceforge.net/devel/example_formulas.html
http://scikit-learn.org/stable/modules/linear_model.html
https://github.com/paulgb/sklearn-pandas#usage
PCA, Factor Analysis, ICA:
http://scikit-learn.org/stable/modules/decomposition.html
MIC:
http://minepy.sourceforge.net/
...:
+1. Logical connectives exist. [1]
statistics - inference in probabilistic models
machine learning - sometimes probabilistic models, sometimes minimizing a nonstatistical cost function
AI - logic not statistics
Inference (probably statistical) and reasoning (not outside of statistics)
This is a cool illustration: http://today.slac.stanford.edu/images/2009/colloquium-web-collide.jpg
Data mining - sometimes machine learning, sometimes referring to the process of acquiring and preprocessing data
Great answer; thanks!
...
(These may be helpful for the sidebar)
Is there a reason that PCA or MIC would or would not be applicable here?
http://en.wikipedia.org/wiki/Principal_component_analysis
http://en.wikipedia.org/wiki/Mutual_Information#Multivariate_mutual_information
IIUC you're doing combinatorial linear regression with a random seed?
[EDIT] http://en.wikipedia.org/wiki/Combinatorial_optimization
[EDIT] Why is this downvoted in /r/statistics?
Manual linear regression is unfortunately biased.
There seems to be an assumption of independence between variables that may not be valid and would be missed by classical regression. (e.g. see "feature extraction")
They've been providing a superior package tool (open source) and binaries across three platforms for years
+1
before pip finally caught up conceptually with 'wheels' (which is still in practice rarely available for one platform, let alone 3, and feels like a case of catch-up NIH syndrome)
Wheels predate conda, which solves a wider problem.
http://legacy.python.org/dev/peps/pep-0427/
http://pip.readthedocs.org/en/latest/reference/pip_wheel.html
https://github.com/conda/conda/releases?after=1.7.0
Conda environments are compatible with pip.
http://conda.pydata.org/docs/faq.html#installation
Conda tries pip last (see: --no-pip)
How many employers want Python programmers?
Here are alot of Python jobs (I searched for "python jobs"):
- http://www.python.org/community/jobs/
- https://jobs.github.com/positions?description=python
- http://careers.joelonsoftware.com/jobs?searchTerm=python
- http://www.linkedin.com/jsearch?keywords=python
- http://www.indeed.com/q-Python-jobs.html
- http://www.simplyhired.com/a/jobs/list/q-python
- http://seeker.dice.com/jobsearch/servlet/JobSearch?op=300&FREE_TEXT=python
- http://careers.stackoverflow.com/jobs/tag/python
- http://www.pythonjobs.com/
- http://www.djangojobs.org/
Is Python better as a stepping stone to more complicated languages?
Is Python better than what?
- Python is a good first language.
- Python is a good second language.
- Python interfaces with C, C++, R, Java, CLR, [...]
- I would agree that C++ is a traditional language.
- Python to Cython to C++ might be a good progression.
Numba is pretty fast, too.
How can you ascribe the semantic meaning of 'like' to upvote and downvote?
I may not 'like' something, but feel that more people should be aware of it.
These both support SQL and CSV.
With positive externalities to include:
If you could pump the fda data into the semantic thesaurus you might be able to find some cool results.
Could be useful for identifying pathways [1]; but the lack of case histories may be the limiting factor. [2]
Mapping to RDF [3][4] could dramatically simplify a join/merge. [4][5]
It probably wouldn't be too difficult to create a JSON-LD @context for these schema (e.g with RDFLib-jsonld). [6]
From there, linking to recent/relevant studies could be accomplished with MESH [7] headings (as from PubMed [8] and understood by UMLS) and bibliographic metadata (edges) [9]
Unfortunately, RDFa is not yet widely prevalent with (medical) journals. [10]
From [11]:
Standard Forms for Sharing Analyses (as structured data with structured citations)
- Quantitative summarizations
- Computed aggregations / rollups
- Inter-study qualitative linkages (seemsToConfirm, disproves, suggestsNeedForFurtherStudyOf)
It may be helpful to connect Schema.org [12] health/medical types with UMLS.
[1] https://en.wikipedia.org/wiki/Clinical_pathway#Selection_Criteria
[2] https://github.com/FDA/openfda/blob/master/schemas/faers_mapping.md
[3] https://github.com/FDA/openfda/blob/master/schemas/faers_mapping.json
[4] https://en.wikipedia.org/wiki/Join_(relational_algebra)#Joins_and_join-like_operators
[6] http://www.reddit.com/r/Python/comments/1wtdyj/rdflibjsonld_jsonld_linked_data_parser_and/cf56g69
[7] http://www.nlm.nih.gov/mesh/
[8] www.ncbi.nlm.nih.gov/pubmed/
[9] http://www.reddit.com/r/semanticweb/comments/1z7q2q/bibtex_rdf_and_citations_pdf_or_html/cfrax12
[11] http://www.reddit.com/r/semanticweb/comments/21w5cr/rfc_reproducible_statistics_and_linked_data/
Fascinating!
You should cite verbatim exactly which sidebar policies you feel these comments to be in violation of.
I feel that I am being bullied and coerced.
I work in websec and netsec. Links with 'here' as anchor text are not useful to me. (are not ctrl-f 'able) [edit]
Value?
What the [...] does Maslow's Hierarchy of Needs have to do with a judgemental map of Omaha?
What a disrespectful role model.
That would be a valid framework for analyzing which needs the author was attempting to satisfy. Acceptance?
Anyhow, point is lists of links is spam, which is against the rules of reddit, which I won't allow here on Omaha,
No. Lists of links to commercial resources within which the author has a financial interest would be frowned upon. Spam is unsolicited bulk communications.
and if it continues I will ban your account again, and this time I won't unban you as I've already discussed this with you plenty at length in the past.
You do have the power to do that.
If you want to do your thing with Semantic Web for machine readable internet, be my guest. Just please insert some information in there as well for us humans as reddit is primarily for humans, not machines.
Should we have a talk about information and entropy? Read the links or don't. Upvote or downvote.
The two comments I linked in the other comment as well as your submission about MOOCs are great examples of acceptable contribution.
Again, thank you for your feedback.
[Edit] upvote/downvote. [...]
See: __getattr__ and __setattr__ (links above)
Except a context manager doesn't create a separate scope.
Except? Is this a request for a new PEP?
What are the objectives? Encapsulation? Overloading that makes static analysis more difficult?
"PEP 227: Statically Nested Scopes" http://legacy.python.org/dev/peps/pep-0227/
"PEP 343: the 'with' statement" http://legacy.python.org/dev/peps/pep-0343/
"PEP 1: PEP Purpose and Guidelines" http://legacy.python.org/dev/peps/pep-0001/
Thank you for your feedback.
It is unfortunate that you are unable to comprehend the value of those links as compared to worthwhile snarky comments about https://en.wikipedia.org/wiki/Narcissistic_rage_and_narcissistic_injury
Not an operating system, but really helpful w/ a netbook: https://en.wikipedia.org/wiki/I3_(window_manager)
Thanks!
https://en.wikipedia.org/wiki/Frequentist_probability
https://en.wikipedia.org/wiki/Bayesian_probability
https://en.wikipedia.org/wiki/Bayesian_inference
https://en.wikipedia.org/wiki/Bayesian_experimental_design
I suppose one could define a with context manager for a UserDict with __setattr__ (namespacing)
[EDIT]
e.g.
with MyNestedScopeDict() as s:
s.one = 'red'
s['two'] = 'green'
s.one, s.two
# NameError: name 's' is not defined
From http://www.reddit.com/r/Python/comments/1kqewk/should_objects_return_data_or_bind_attributes/cbs2pbk :
Values
- https://en.wikipedia.org/wiki/Principle_of_least_privilege
- https://en.wikipedia.org/wiki/Information_hiding#See_also
- https://en.wikipedia.org/wiki/Encapsulation_(object-oriented_programming)
Docs
From http://legacy.python.org/dev/peps/pep-0020/ :
Namespaces are one honking great idea -- let's do more of those!
__varname names are mangled@property without a setterhttps://en.wikipedia.org/wiki/Map%E2%80%93territory_relation#See_also
https://en.wikipedia.org/wiki/Boundary_delimitation
https://en.wikipedia.org/wiki/Personal_boundaries
https://en.wikipedia.org/wiki/Superiority_complex
( https://en.wikipedia.org/wiki/Inferiority_complex )
https://en.wikipedia.org/wiki/Commercialism
https://en.wikipedia.org/wiki/Grit_(personality_trait)#Grit_and_personality_measures
The grit measure has been compared to the Big Five personality model, which are a group of broad personality dimensions consisting of openness to experience, conscientiousness, extraversion, agreeableness, and neuroticism.[10] In one study by Duckworth and Quinn, the Short Grit Scale (Grit–S) and 12-item self-report measure of grit (Grit–O) measuring grit was strongly correlated with conscientiousness (r = .77, p <.001 and r = .73, p <.001) (2009). While grit is related to conscientiousness measures, it also differs from conscientiousness in important ways. For example, while both grit and conscientiousness are often associated with short term accomplishments, grit is also associated with longer term and multi-year goals.[3] This long-term persistence and dependability are important aspects that make grit distinct from conscientiousness. Another personality characteristic that is often linked to grit is the need for achievement. One way in which grit differs from the need for achievement is that individuals with high scores in grit often set extremely long-term goals for themselves and pursue them deliberately even without positive feedback,[3] while need for achievement lacks this long-term component. [Emphasis Added]
They were called 'mice' and 'keyboards'.
So I'm looking to experiment and try a mini project with my new python/econometrics skills.
http://www.kevinsheppard.com/Python_for_Econometrics
I'm looking to keep it relatively basic, but kinda make it a full-rounded project, basically just:
- a little data scraping maybe,
http://www.reddit.com/r/Python/comments/1qnbq3/webscraping_selenium_vs_conventional_tools/#cdeq2t7
http://pandas.pydata.org/pandas-docs/stable/io.html#io-read-html
- some analysis involving any of Ordinary Least Squares, Generalized Method of Moments, Method of Simulated Moments, and/or Maximum Likelihood Estimation,
http://statsmodels.sourceforge.net/stable/#table-of-contents
- some nice plotting
https://scipy-lectures.github.io/intro/matplotlib/matplotlib.html
http://www.reddit.com/r/pystats/comments/1r7zv0/request_from_my_company_plots_that_they_can/#cdqb0bq
I'm working out of the Anaconda collection of packages
+1 http://docs.continuum.io/anaconda/index.html
I don't know if it's better for me to just pick some random data to analyze and see what I come up with, or maybe just try to replicate some analysis that's already out there.
There's probably enough overlap/intersection that it's really easy to use common core worksheets; although there is not yet an official state standards position on a forthcoming transition to common core.
I understand that I can put basically everything into the requirements.txt but is there a way that pip also "executes" a requirements.txt of the dependency package? I think requirements.txt are flat and have no way to deal with recursive dependencies.
Not that I'm aware of.
There's nothing stopping a subprocess.call(['pip','install','-r','././requirements.txt']) from being added to a setup.py install task. (A wild goose chase down a yellow brick road).
In my case pyramid would be another in-house library with somebody making changes and updates to frequently and has its own requirements.txt that needs execution. Maybe I don't get it, but for me it seems like I several steps to install: 1. pip install my_application_from_git 2. pip install -r requirements.txt (from my_application_from_git) 3. look into every dependency if itself has some requirements.txt that needs to be installed
A Makefile or a shell script with git_clone and a for loop would be a simple solution for supporting a development install.
Pip is designed to work with pkgname<=>versionspec pairs which are read from setup.py and resolved from an index and find-links (optionally accessed through a proxy).
I can't remember where I read about why things are decoupled this way.
And no I can not prepare a flat requirements.txt in advance. We are right in the middle of getting everything into packages and it can be that a script that ones was one now consists of several sub-packages. It is just not possible to keep all the requirements.txt up to date on a daily basis. I'd think even keeping track would be hard.
Your situation sounds similar to the zope eggification. They work with (zc.)buildout, which is IMHO harder to debug than a Makefile; but there lots of extensions for various build tasks.
Python packages are designed to have versions, checksums, and signatures.
Yeah, I saw a while back some online thing that tried walking me through some simple division problem using the common core technique.
http://www.corestandards.org/Math/Content/3/introduction/
https://www.khanacademy.org/math/arithmetic/multiplication-division
[EDIT] Are you talking about "Dividing with Number Lines"?
What's the deal with common core anyway? All I've really seen about it is their new approach to elementary mathematics, which, to my post-elementary mathematics brain, seems pretty damned ridiculous.
So, different algorithms are bound to be more intuitive to different people; depending on what they were taught and how they physically conceptualize their environment.
There's certainly more than one way to do it. If we are to understand students from various systems, it's not that hard to learn an additional cognitive algorithm.
[EDIT]
We're not accustomed to change. (e.g. coping with new (and entirely unnecessary technology)
https://en.wikipedia.org/wiki/Tuckman's_stages_of_group_development#John_Fairhurst_TPR_Model
[...] tactic.
It's really not a partisan issue, though it is an outrage that "[...] fewer than 30% of America’s schools have the broadband they need to connect to today’s technology."
It's just badly understood and some of the commercial content generated (In the supposed name of common core) by [...] text book companies is easily attacked.
With aligned standards, the market for educational materials is becoming a bit different: creating room for greater dialogue and conversation.
A search for "Open Educational Resources" (#OER) finds lots of CreativeWorks which our community can evaluate and work into curriculum.
https://en.wikipedia.org/wiki/Set_(mathematics)#Basic_operations
Clearly, there were/are large intersections between Common Core and state-level standards.
I don't think it's a subset / superset relation.
Our standards also focus more on what is important for Nebraskans to know (ie. Famous people, arbor day, and state history) which as an educator I think is pretty important.
I'm sure there's room for legislated state-level civics requirements.
I've heard from teachers, our standards are much more demanding and higher than what is required by Core Curriculum.
That may be subjectively true. As producers of graduates which will apply to undergraduate programs across the United States, I think it would be helpful for us to determine exactly where those set complements are.
The main differences between our standards and core curriculum is the core curriculum focuses much more on non fiction and informational text while our standards allow for more exploration of fictional materials.
This must be a difficult regional variation to generalize for all 314 million people here (and for the 1.85 million citizens of all ages in Nebraska).
To me, the name "Common Core" implies that Common Core is a subset of state-level education standards.
Shared contextual #OER annotations with http://hypothes.is/ could also be helpful.
I think it's 1 because we're Nebraska and we're rebels,
Outstanding.
and 2 because we need to teach the importance of writing structure vs. forced answers.
I also feel core doesn't show a student's true writing potential.
Thanks!
Basically, we have that extra test on writing. We teach writing as something separate instead of heavily incorporating it into Math and Reading.
Why? http://www.corestandards.org/ELA-Literacy/
The kids are able to just answer the questions without having an essay explanation of the answers and what not.
It all though seems to come down to the state testing.
OPS Curriculum Standards
Thanks! These appear to be the same as the PDFs from education.ne.gov/academicstandards/ with Mathematics as the exception (linking to "Compendium of Course Content Standards" [2008-09] http://district.ops.org/Portals/0/CurrandLearn/08-09%20Content%20Standards-OPS.pdf).
Thanks! So this is a different page: http://www.education.ne.gov/academicstandards/index.html
Nebraska Statute requires the Nebraska State Board of Education to update standards for each subject area every five years according to the following schedule:
- Language Arts - April 2009
- Mathematics - October 2010
- Science and Social Studies - November 2010
- Social Studies - December 2012
It looks like there are PDF and DOC versions.
It would be much easier to link things [1] to the specific curriculum #headings [2] with an HTML version.
With RDFa, the community could collaboratively link learning resources to curriculum headings. Schema.org can be expressed in RDFa (HTML + very useful extra attributes).
Schema.org [3][4] has an 'educationalAlignment' property for CreativeWork [5] (and all subclasses e.g. Article, Blog, Book, Movie, Photograph, Question) based on LRMI (Learning Resource Metadata Initiative). [6]
Search engines support schema.org metadata.
This could be of great help in creating lesson plans.
[1] https://en.wikipedia.org/wiki/Requirements_traceability
[2] https://en.wikipedia.org/wiki/Fragment_identifier
[3] https://en.wikipedia.org/wiki/Schema.org
[4] http://schema.org/docs/full.html
These are great, free, and can be rewound and watched [again] at home:
I like the dashboard because there's instant feedback. What a helpful refresher.
http://code.edx.org/ is Open Source and mostly written in /r/Python (/r/learnpython).
There may be a few Python programmers with the CERN and/or HCC teams.
This is a valid requirements.txt file:
jinja2
-e git+ssh://git@github.com/pyramid/pyramid@1.5.1#egg=pyramid
-r requirements-dev.txt
-r requirements-docs.txt
From a devops perspective, compared to testing and maintaining a script (shell, Makefile, fabric, ...) with sudo or root privileges, configuration management is a win. A high-level break-down of app installation:
The problem with
--find-linksis that I have tons of internal links to put in there. It's not just to long type without but also no one will remember all those links to put when they want to install or update (and this happens often) anything.
There's a distutils.cfg file and a PIP_CONFIG_FILE (~/pip/pip.conf)
http://pip.readthedocs.org/en/latest/user_guide.html#config-file
There may be answers in the "Python Packaging User Guide", which is relatively new.
You could create a pip repository.txt file with topologically sorted editable VCS URLs containing explicit @tag_branch_or_revid specifiers. Or, wheels.
http://www.reddit.com/r/Python/comments/21itpp/what_is_the_proper_way_to_mix_regular_python/#cgdgaxh
"Prolonged Fasting Reduces IGF-1/PKA to Promote Hematopoietic-Stem-Cell-Based Regeneration and Reverse Immunosuppression"
http://www.cell.com/cell-stem-cell/abstract/S1934-5909(14)00151-9
https://en.wikipedia.org/wiki/Self-realization
https://en.wikipedia.org/wiki/%C4%80tman_(Hinduism)
Ātman (IAST: ātman, Sanskrit: आत्मन्) is a Sanskrit word that means 'inner-self' or 'soul'. In Hindu philosophy, especially in the Vedanta school of Hinduism, Ātman is the first principle,[1] the true self of an individual beyond identification with phenomena, the essence of an individual. In order to attain salvation (liberation), a human being must acquire self-knowledge (atma jnana), which is to realize that one's true self (Ātman) is identical with the transcendent self Brahman:
If atman is brahman in a pot (the body), then one need merely break the pot to fully realize the primordial unity of the individual soul with the plentitude of Being that was the Absolute
https://en.wikipedia.org/wiki/Anatta
In Buddhism, the term anattā (Pāli) or anātman (Sanskrit: अनात्मन्) refers to the notion of "not-self" or the illusion of "self". In the early texts, the Buddha commonly uses the word in the context of teaching that all things perceived by the senses (including the mental sense) are not really "I" or "mine", and for this reason one should not cling to them.
https://en.wikipedia.org/wiki/Sunyata
.
https://en.wikipedia.org/wiki/Know_thyself
~ "Know Thyself"
http://biblehub.com/genesis/1-27.htm
"So God created mankind in his own image, in the image of God he created them; male and female he created them."
https://en.wikipedia.org/wiki/Image
https://en.wikipedia.org/wiki/Image_(mathematics)
https://en.wikipedia.org/wiki/Through_a_glass,_darkly_(phrase)#.22Through_a_glass.2C_darkly.22
"For now we see through a glass, darkly."
https://en.wikipedia.org/wiki/Babylonian_Talmud
"All the prophets gazed through a speculum that does not shine, while Moses our teacher gazed through a speculum that shines.
http://www.sacred-texts.com/isl/tah/tah05.htm
"KNOWLEDGE of self is the key to the knowledge of God, according to the saying: "He who knows himself knows God,"[1]"
https://en.m.wikipedia.org/wiki/Self-knowledge_(psychology)
[EDIT] Link to self-realization, rough chronology (Western upbringing)
Did the authors make any effort to correct the inaccuracies that they identified?
http://docs.scipy.org/doc/numpy/user/basics.broadcasting.html
https://github.com/dwf/rescued-scipy-wiki/blob/master/EricsBroadcastingDoc.rst (TODO: update link in NumPy docs)
http://scipy-lectures.github.io/intro/numpy/operations.html#broadcasting
[EDIT] http://deeplearning.net/software/theano/library/tensor/basic.html#broadcasting-in-theano-vs-numpy
Long running Python jobs that consume a lot of memory while running may not return that memory to the operating system until the process actually terminates, even if everything is garbage collected properly. That was news to me, but it’s true. What this means is that processes that do need to use a lot of memory will exhibit a “high water” behavior, where they remain forever at the level of memory usage that they required at their peak.
https://docs.python.org/2/reference/simple_stmts.html#the-del-statement
https://docs.python.org/2/library/gc.html#gc.collect
A way to get around this is to fork child processes that are short lived and that do not keep large complex objects around for the life of the parent process.
+1
In addition, I would not recommend using threads for concurrent middleware when writing in Python since you can't compartmentalize its memory consumption to the life of the thread (this was my theory as to why I chose not to use threads, though I don't have proof of this behavior in the wild).
This is why cgroups exist at the OS level.
After working with messaging and middleware for a few years now, I would recommend using ZeroMQ (if you don't want/need to run a broker) or ActiveMQ (if you need a broker, which it seems like at the enterprise level you might).
While fast, 0mq does not solve for reliable delivery or transport security.
Easier maintainability
Less KLOC is better for maintenance.
If there are tests, they should all be passing; with coverage.
Parsing Messages
Java has strong support for XML. Python has some XML support in the standard library. External XML modules are largely written in C.
Multithreading
In Python -- as with most languages -- it is much easier to debug and develop multiprocess applications; which, by design, are more easily distributable. There are threading primitives, but the GIL remains the limiting factor for threaded Python applications.
There are lots of Python libraries for various standard protocols and interfaces.
Message Brokers
AMQP is a protocol. ZeroMQ is a messaging library.
AMQP offers flow control and reliable delivery.
Enterprise Python
Java -> Python
[Edit]
OpenAnnotation spec: http://openannotation.org/spec/core/
I don't see (common carrier) infrastructure as a partisan issue.
"[...] fewer than 30% of America’s schools have the broadband they need"
To the extent that my desire to record n 4k streams of content at the same time (to avoid re-downloading - 'streaming' - the same video from the other side of the country) supports getting broadband to schools, I feel like I'm helping.
So, if we want to support tech in Omaha, Nebraska - by hosting local datacenters - we should be (have been) focused on developing our (smart) power grid?
Some time ago, I was terribly excited about the ability to produce Plone archetype stub code from UML models.
Then, we realized that round trip was infeasible, and, had we not been concerned with impressive diagrams containing gradients and stick gfigures, we could have iteratively reached a comparable solution with less tool dependency... YMMV
Equal pay for equal hours.
What relation is there between ability to satisfy grades and employment success?
Note: I haven't read the study design or selection criteria.
Programmer Competency Matrix Checklist : http://competency-checklist.appspot.com/
Ctrlp could support command lookup.
There's also FuzzyFinder http://www.vim.org/scripts/script.php?script_id=1984
FuzzyFinder provides convenient ways to quickly reach the buffer/file/command/ bookmark/tag you want.
Here's a patch to add Schema.org Video support (adds RDFa to template) for pyvideo.org: https://github.com/willkg/richard/pull/213
For the other useful resources listed here, within http://schema.org/CreativeWork there are "More specific Types".
FWIU, Python 2 compatibility.
https://github.com/alex/zero_buffer/blob/master/zero_buffer.py
To do this in-band with RDF (not with external version control), there are a number of approaches. The top three Google Search results for "rdf changesets":
Datahub.io is a CKAN site:
AST is killer feature. For sure. Lots of interesting applications in goal programming.
"Half of jailed NYC Teens have history of traumatic brain injury (TBI)" http://www.reddit.com/r/psychology/comments/23omku/half_of_jailed_nyc_teens_have_history_of/
"Almost half of homeless men had traumatic brain injury in their lifetime, 87% of which occured before they lost their home, new study finds" http://www.reddit.com/r/science/comments/23ympx/almost_half_of_homeless_men_had_traumatic_brain/
Here's a link to an updated text for the same course: http://courses.csail.mit.edu/6.042/fall13/mcs.pdf (Creative Commons) #OER
(http://www.reddit.com/r/math/comments/20x901/math_classes_most_applicable_to_theoretical/#cg7lbb4)
"Decoding > Tokenizing > Parsing > AST > Compiling"
Thanks!
"From Python to Code: How CPython's Compiler Works" Dr. Brett Cannon. PyCon CA 2013
My interpretation of the author's assertion may have been a bit muddled by work with C3 linearization of the Python MRO; but would it be fair to call the COMP process a heuristic?
It seems similar to an ontology mapping problem with a 'cost function' predicated upon a magnitude of correlation. [1]
Humorous delight in drawing unexpected analogies and metaphors, then, becomes all the more interesting.
Not in the word, metaphor.
Reductionistic metaphorical personification of metaphor as a cognitive process identifier.
If we look for a thing/mental object, idea, we won't find it.
http://schema.org/docs/full.html (http://schema.org/Thing)
Thank you for the clarification!
To take a step back, the article seems to present a dichotomy of roles between 'developer' and 'operations' (e.g. 'web application developer' and 'systems administrator').
The job, as I understand it, is information systems engineer. As an information systems engineer, the job objective is to produce a system which supports information flows between a number of appropriate clients, while minimizing error.
The job, whether it is 'more on the developer side' or 'more on the operations side' is to support this objective; as a valued component of a team that is (maybe should) always operating with relatively constrained resources.
I don't know how the article could suggest that operational process control and change control are at all preventing developers from coding.
"I can't get anything done because I've suddenly realized how much work it is to realistically run my own PaaS on an IaaS with my standby 'install.sh'" is not a valid argument.
It makes perfect sense to minimize error. Developers should be concerned with scale. Systems should be concerned with which applications they are putting in the cloud.
I routinely argue for holism in science fields to counteract specialization entropy. The fields intersect; that is where inefficient communication and handoffs happen.
"a new organic-based flow battery using quinone, a molecule nearly identical to one found in rhubarb. It can be found in green plants or synthesized from crude oil, and costs about $27 per kilowatt hour of storage capacity, compared with $700 for conventional metal batteries." http://redd.it/1uujjw
Planning poker is one way to elicit relative quantitative valuations for feature effort/complexity. You could crowd-source the factor weights similarly; though, for the domain, Fibonacci numbers might not be as helpful as a simple qualitative scale e.g. from least important to most important.
I know I need to use some type of statistical analysis, but I don't really know where to start. Clustering? PCA? Factor analysis? Regression model? Bayesian methods? Other??
https://en.wikipedia.org/wiki/Decision-matrix_method
https://en.wikipedia.org/wiki/Information_criterion_(disambiguation)
http://www.quandl.com/usa/usa-health-data
https://www.google.com/publicdata/explore?ds=kthk374hkr6tr_
http://en.wikipedia.org/wiki/World_Health_Organization_ranking_of_health_systems_in_2000#See_also
http://en.wikipedia.org/wiki/List_of_countries_by_life_expectancy
if you want to play semantic acronym game, THEN:
Acronyms ... LOD : http://lod-cloud.net/
Linked Open Government Data
reigns supreme
;)
Are there tools and processes which simplify statistical data analysis workflows with linked data?
Ten Simple Rules for Reproducible Computational Research:
- Rule 1: For Every Result, Keep Track of How It Was Produced
- Rule 2: Avoid Manual Data Manipulation Steps
- Rule 3: Archive the Exact Versions of All External Programs Used
- Rule 4: Version Control All Custom Scripts
- Rule 5: Record All Intermediate Results, When Possible in Standardized Formats
- Rule 6: For Analyses That Include Randomness, Note Underlying Random Seeds
- Rule 7: Always Store Raw Data behind Plots
- Rule 8: Generate Hierarchical Analysis Output, Allowing Layers of Increasing Detail to Be Inspected
- Rule 9: Connect Textual Statements to Underlying Results
- Rule 10: Provide Public Access to Scripts, Runs, and Results
.
Possible topics/categories/clusters:
- ETL data to and from RDF and/or SPARQL
Relational selection and projection into tabular form for use with standard statistical tools is easy enough; if wastefully duplicative.
One issue with CSV and tabular data tools like spreadsheets is where to store columnar metadata (URI, provenance, units, precision).
- https://en.wikipedia.org/wiki/Data_management#Topics_in_Data_Management
- How to express Units and Precision with quantitative data in RDF?
Units
http://www.qudt.org/ (qudt:)
Precision
- Verifying and reproducing point-in-time queries
Batch intermediate queries and transformations do seem most appropriate.
See rules 1, 3, 5, 6, 7, 8.
- Data Science Analysis
- (There are no tests for significance in http://www.w3.org/TR/sparql11-query/#aggregates )
Clearly, statistical test preferences are out of scope for the SPARQL query language.
I'm not aware of any standards for maintaining precision or tracking provenance with RDF data transformed through SPARQL.
- Which tools and libraries preserve relevant metadata like units and precision?
In Python-land, Pint and Quantities extend standard NumPy datatypes.
QUDT?
- How feasible is round trip?
In terms of Knowledge Discovery with changesets that preserve units and precision while tracking provenance.
- Standard Forms for Sharing Analyses (as structured data with structured citations)
PLOS seems to be at the forefront of modern science in this respect; with a data access policy and HTML compatibility.
Where is RDFa?
- Quantitative summarizations
In terms of traceability (provenance), how does one say, in a structured way, that a particular statistical calculation (e.g a correlation) traces back to a particular transform on a particular dataset? (Rule 9; 1-10).
- Computed aggregations / rollups
There's raw data and there's (temporal, nonstationary) binning.
- Inter-study qualitative linkages (seemsToConfirm, disproves, suggestsNeedForFurtherStudyOf)
Do we have standards for linking between studies?
Do we have peer review for such determinations?
The PRISMA meta-analysis checklist presents standard procedures for conducting these types of categorical assertions of multiple studies.
It would seem that each meta-analysis must review and store lots of potentially valuable metadata; that could/should be stored and shared, depending on blinding protocols.
Linked data can and will make it easier to automate knowledge discovery between and among many fields.
Most practically, given a CSV (really any dataset) accompanying a study PDF, how do we encourage standards for expressing that said CSV:
It seems strange that we've had computational capabilities available to us for so long, and yet we're still operating on parenthetical summarizations of statistical analyses devoid of anything but tabular summarizations of collected data.
PLOS' open access data sharing policy is a major step forward. It does not demand Linked Data with standard interchange forms for provenance, units, and precision.
In "SPARQL in the Cloud using Rya", the authors describe layering OpenRDF/Sesame SAIL onto three Accumulo (BigTable/HDFS) tables (SPO, POS, OSP) also for billions of triples.
For realtime processing, integration with Apache Storm would be neat; though batch processing (like infovore) is associated with more reproducible computational analyses, and normalization/granularity would be a challenge.
Do you script/record the graphical data analysis procedure to limit bias and ensure validity and reproducibility?
So, what's the best way to learn pandas?
Read the docs: http://pandas.pydata.org/pandas-docs/stable/api.html
I think of myself as an ok Python and SQL developer, but I just can't grasp pandas. I have a simple task to build some gantt-type graphs from simple set of tasks with transfer speed and start/end dates, but I just can't wrap my mind around it.
If, when you say "Gantt-type graphs" you mean "error bars", #3796 adds error bar support: http://pandas-docs.github.io/pandas-docs-travis/whatsnew.html#plotting-with-errorbars
Is there an example in http://matplotlib.org/gallery.html similar to what you have in mind?
... "ENH: Linked Datasets (RDF)" https://github.com/pydata/pandas/issues/3402
https://code.google.com/p/spyderlib/
conda install spyder
I recently got my PhD in Computer Science, and noticed all work experience I have is Academic. I've been programming in Python for the last 6 years or so, mostly with data mining, image processing and data visualization. I worked a few very meaningful but classified (government sponsored) projects I'm not allowed to talk about, which is a HUGE pain as they can't go to my resume.
I enjoy science and research, but I really want to start working "for real" now. What kind of skills should I develop to become more hirable than the fresh PhD with no real-world experience I am right now?
It sounds like you are talking about making the transition from academic Research and Development (R&D) to Production Systems Development.
What kind of skills should I invest on?
For those of you with academic background that were able to join the (non academic) market, what kind of skills you had to learn to be hire-able?
(Sorry about the English, non-native here)
I would imagine that different environments require different hard and soft skills.
Open Source development could help distinguish your quality of work.
Many of the following Wikipedia links are translated to multiple languages:
Software Development
- https://en.wikipedia.org/wiki/User_story
- https://en.wikipedia.org/wiki/Pair_programming
- https://en.wikipedia.org/wiki/Distributed_revision_control [1]
- https://en.wikipedia.org/wiki/Test_automation [2]
- https://en.wikipedia.org/wiki/Test-driven_development#Test-driven_development_cycle
- https://en.wikipedia.org/wiki/Continuous_integration#Principles
- https://en.wikipedia.org/wiki/Code_review
- https://en.wikipedia.org/wiki/Release_management
- https://en.wikipedia.org/wiki/Build_automation
- https://en.wikipedia.org/wiki/Continuous_deployment
Communication: Documentation
- https://en.wikipedia.org/wiki/Technical_communication
- https://en.wikipedia.org/wiki/Software_documentation
- https://en.wikipedia.org/wiki/Specification_(technical_standard)#Information_technology
- http://docs.python.org/devguide/documenting.html
- http://write-the-docs.readthedocs.org/en/latest/
Open Source Teams
- https://en.wikipedia.org/wiki/Open-source_software [3]
- https://en.wikipedia.org/wiki/Open-source_software_security
- https://en.wikipedia.org/wiki/Business_models_for_open-source_software
- https://en.wikipedia.org/wiki/Comparison_of_free_software_licenses
- https://github.com/blog/1530-choosing-an-open-source-license
- https://github.com/pydata/pandas/blob/master/CONTRIBUTING.md
[1] Revision Control (CVS, SVN) and Distributed Revision Control (Git, Hg, Bzr)
- http://documentup.com/skwp/git-workflows-book
- http://book.git-scm.com/index.html
- http://hgbook.red-bean.com/
[2] Automated Testing
[3] The Art of Unix Programming: Best Practices for Working with Open-Source Developers
Teams
- https://en.wikipedia.org/wiki/Team
- https://en.wikipedia.org/wiki/Team_building
- https://en.wikipedia.org/wiki/Tuckman%27s_stages_of_group_development
- https://en.wikipedia.org/wiki/The_Five_Dysfunctions_of_a_Team
- https://en.wikipedia.org/wiki/Collaboration#Technology
- https://en.wikipedia.org/wiki/List_of_collaborative_software
Without use cases, I question whether these are 'design flaws' or implementation flaws.
I like Celery. Celery solves problems that most task queue frameworks don't even realize exist; like retries, rate limiting, monitoring, statistics, and safe serialization.
The (non-SQLAlchemy) features you suggest could be added to pyramid_celery.
Global Configuration
Decorators are syntactic sugar for functional composition.
You could create a class factory, or apply a task wrapper with (unspecified) special configuration information. Thread locals? How often must configuration information be read?
Transparency
http://celery.readthedocs.org/en/latest/userguide/tasks.html#names :
A best practice is to use the module name as a namespace, this way names won’t collide if there’s already a task with that name defined in another module.
@app.task(name='tasks.add')
def add(x, y):
return x + y
http://celery.readthedocs.org/en/latest/userguide/tasks.html#automatic-naming-and-relative-imports
Task Context & Transaction Integration
One could write a decorator (e.g. with functools.wraps) to wrap the function in application-specific transaction management.
http://celery.readthedocs.org/en/latest/userguide/tasks.html#built-in-states
Parameter Handling
There is room for more tightly coupled bridges between ORMs and the task framework.
http://celery.readthedocs.org/en/latest/userguide/tasks.html#state :
Another gotcha is Django model objects. They shouldn’t be passed on as arguments to tasks. It’s almost always better to re-fetch the object from the database when the task is running instead, as using old data may lead to race conditions.
IPython dev now supports dill
Pickles are not safe:
From http://docs.python.org/2/library/pickle.html#pickle-python-object-serialization
Warning The pickle module is not intended to be secure against erroneous or maliciously constructed data. Never unpickle data received from an untrusted or unauthenticated source.
http://celery.readthedocs.org/en/latest/userguide/security.html#message-signing
Personally, I like msgpack and JSON for inter-language portability. (datetime, http://json-ld.org/)
http://www.pip-installer.org/en/latest/reference/pip_install.html#editable-installs
pip install -e git+ssh://git@github.com/pyqtgraph/pyqtgraph#egg=pyqtgraph
Clones the sourcecode from GitHub into ./src/pyqtgraph (with git over SSH) and then creates a pyqtgraph.egg-link file in site-packages containing the path to the cloned source; which functions like a cross-platform symlink.
python -m site
Should list the source code directory in site-packages/pyqtgraph.egg-link.
If you'd rather avoid globally installing in-development code; pip install -e should work with all of the following:
conda install qt)http://plato.stanford.edu/entries/logic-inductive/#2.1
It is now generally held that the core idea of Bayesian logicism is fatally flawed—that syntactic logical structure cannot be the sole determiner of the degree to which premises inductively support conclusions. A crucial facet of the problem faced by Bayesian logicism involves how the logic is supposed to apply to scientific contexts where the conclusion sentence is some hypothesis or theory, and the premises are evidence claims. The difficulty is that in any probabilistic logic that satisfies the usual axioms for probabilities, the inductive support for a hypothesis must depend in part on its prior probability. This prior probability represents how plausible the hypothesis is supposed to be based on considerations other than the observational and experimental evidence (e.g., perhaps due to relevant plausibility arguments). A Bayesian logicist must tell us how to assign values to these pre-evidential prior probabilities of hypotheses, for each of the hypotheses or theories under consideration. Furthermore, this kind of Bayesian logicist must determine these prior probability values in a way that relies only on the syntactic logical structure of these hypotheses, perhaps based on some measure of their syntactic simplicities. There are severe technical problems with getting this idea to work. Moreover, various kinds of examples seem to show that such an approach must assign intuitively quite unreasonable prior probabilities to hypotheses in specific cases (see the footnote cited near the end of section 3.2 for details). Furthermore, for this idea to apply to the evidential support of real scientific theories, scientists would have to formalize theories in a way that makes their relevant syntactic structures apparent, and then evaluate theeories solely on that syntactic basis (together with their syntactic relationships to evidence statements). Are we to evaluate alternative theories of gravitation (and alternative quantum theories) this way? This seems an extremely doubtful approach to the evaluation of real scientific theories and hypotheses.
https://en.wikipedia.org/wiki/Data_science
http://www.reddit.com/r/datascience/comments/1z6s9j/will_data_scientists_be_automated_away/
http://www.reddit.com/r/datasets/comments/1yg1jx/looking_for_any_large_dataset_of_1_million_records/
It may seem irrelevant, but how do we define "action"? Transmutation of energy [and enact a physical change?
Thought as action complicates such a definition. e.g. "don't think about a pink elephant"
https://en.wikipedia.org/wiki/Alchemy
If [condition set] then [output set]:
It is now generally held that the core idea of Bayesian logicism is fatally flawed—that syntactic logical structure cannot be the sole determiner of the degree to which premises inductively support conclusions.
.
one of the four philosophical questions of creating intelligence.
A few categorical assertions:
https://en.wikipedia.org/wiki/Conceptual_metaphor
https://en.wikipedia.org/wiki/Cognitive_psychology#Mental_processes
https://en.wikipedia.org/wiki/Numerical_cognition
https://en.wikipedia.org/wiki/Cognitive_neuropsychology
https://en.wikipedia.org/wiki/Cognitive_neuroscience
Calling everything an analogy in conversation is a bit extreme. Actually, one could call then everything a metaphor, which would be about the same thing, or a parable, a fable, a simile, and anecdote, etc. But that doesn't make sense.
Are you making a (hierarchical) categorical assertion about analogy as distinct from metaphor based upon correlative activations?
https://en.wikipedia.org/wiki/Analogy
Analogy (from Greek ἀναλογία, analogia, "proportion"[1][2]) is a cognitive process of transferring information or meaning from a particular subject (the analogue or source) to another particular subject (the target), or a linguistic expression corresponding to such a process.
[...]
The concepts of association, comparison, correspondence, mathematical and morphological homology, homomorphism, iconicity, isomorphism, metaphor, resemblance, and similarity are closely related to analogy. In cognitive linguistics, the notion of conceptual metaphor may be equivalent to that of analogy.
https://en.wikipedia.org/wiki/Metaphor
A metaphor is a figure of speech that describes a subject by asserting that it is, on some point of comparison, the same as another otherwise unrelated object. Metaphor is a type of analogy and is closely related to other rhetorical figures of speech that achieve their effects via association, comparison or resemblance including allegory, hyperbole, and simile.
In simpler terms, a metaphor compares two objects/things without using the words "like" or "as".
Source -> Target ... Directed Graph ... http://www.scholarpedia.org/article/Recurrent_neural_networks
Configuration Management tools written in Python for desktop support / system administration.
https://en.wikipedia.org/wiki/Comparison_of_open-source_configuration_management_software
https://github.com/saltstack/salt
https://github.com/ansible/ansible
https://github.com/fabric/fabric
https://github.com/chocolatey/chocolatey
http://docs.saltstack.com/ref/modules/all/salt.modules.chocolatey.html
Python 3.4 asyncio (codename: tulip) is an abstraction for asynchronous concurrent programming which, by yield-ing when waiting for input/output calls to return, can run other code in the meantime; making single-threaded code faster.
"Life is what happens while you are busy making other plans." -- John Lennon
https://en.wikipedia.org/wiki/Abuse
https://en.wikipedia.org/wiki/Ethics
https://en.wikipedia.org/wiki/Philosophy_of_artificial_intelligence (Narrow/Weak // Strong/AGI)
https://en.wikipedia.org/wiki/Developmental_psychology
https://en.wikipedia.org/wiki/Disability_Rating_Scale#Rating_Scale
https://en.wikipedia.org/wiki/Sentience_quotient [EDIT]
Mathematics for Computer Science
[EDIT] Artificial Intelligence: A Modern Approach http://aima.cs.berkeley.edu/
Presumably we will be able to lawyer our way out of cancer and aids; and that's why STEM fields are 100% worthy.
HHS
FDA
NIH
CDC
SAMHSA
...
Data.gov
[EDIT] UMLS Terminology Services (UTS) (RxNorm)
HHS
FDA
NIH
CDC
SAMHSA
...
Data.gov
[EDIT] UMLS Terminology Services (UTS) (RxNorm)
https://en.wikipedia.org/wiki/Strawman
I'm struggling to determine the author's objectives in disproving such a nationally-strategic hypothesis.
If it's to point people towards careers with projected growth: http://www.bls.gov/ooh/fastest-growing.htm
If it's to 'tip the scales' between business and science, there seems to be no comprehension of the wide-applicability of "general STEM competency", as the RAND report puts it.
Automation is nigh. Creative, reproducible, verifiable approaches to experiment-driven science and business are hard to find.
All have concluded that U.S. higher education produces far more science and engineering graduates annually than there are S&E job openings—the only disagreement is whether it is 100 percent or 200 percent more. Were there to be a genuine shortage at present, there would be evidence of employers raising wage offers to attract the scientists and engineers they want. But the evidence points in the other direction: Most studies report that real wages in many—but not all—science and engineering occupations have been flat or slow-growing, and unemployment as high or higher than in many comparably-skilled occupations.
I found no such conclusion in 'all'. There seems to be a disproportionate focus on margins; as compared to health. Wages are a very poor indicator of our need for capable STEM personnel in research fields like Cancer and AIDS.
http://www.nature.com/nature/journal/v483/n7391/full/483531a.html
http://www.computinginthecore.org/facts-resources
The Bureau of Labor Statistics projects that by the year 2020, there will be 4.2 million jobs in computing and information technology in the U.S., putting these fields among the fastest growing occupational fields
Not everyone has or wants to use root privileges to run software downloaded from the internet. It is (and should be) possible to manage Python packages with either conda or enpkg without sudo (root privileges). If you run conda or enpkg as root, the installed files will be owned by root.
Sage, Anaconda, and Canopy include different package sets:
All three include IPython notebook. Anaconda and Canopy both support installing packages with conda/enpkg and pip. Anaconda has conda environments instead of virtualenvs.
https://gist.github.com/westurner/9458621 ...
"Nielsen's Law of Internet Bandwidth" http://www.nngroup.com/articles/law-of-bandwidth/ :
Summary: Users' bandwidth grows by 50% per year (10% less than Moore's Law). The new law fits data from 1983 to 2013.
Akamai State of the Internet http://www.akamai.com/stateoftheinternet/ (2008 - present)
http://www.measurementlab.net (2008 - present)
YouTube Video Quality Report http://www.google.com/get/videoqualityreport/ (2010 - present)
Netflix ISP Speed Index http://ispspeedindex.netflix.com/usa (2012 - present)
http://en.wikipedia.org/wiki/Measuring_network_throughput
[EDIT] Fixed public data link
https://hypothes.is/what-is-it/ :
We are a non-profit organization, funded through the generosity of the Sloan, Shuttleworth and Mellon Foundations – and through the support of hundreds of individuals like yourself that want to see this idea come to fruition.
http://www.openannotation.org/spec/core/#abstract :
The Open Annotation Core Data Model specifies an interoperable framework for creating associations between related resources, annotations, using a methodology that conforms to the Architecture of the World Wide Web. Open Annotations can easily be shared between platforms, with sufficient richness of expression to satisfy complex requirements while remaining simple enough to also allow for the most common use cases, such as attaching a piece of text to a single web resource.
An Annotation is considered to be a set of connected resources, typically including a body and target, where the body is somehow about the target. The full model supports additional functionality, enabling semantic annotations, embedding content, selecting segments of resources, choosing the appropriate representation of a resource and providing styling hints for consuming clients.
http://www.openannotation.org/spec/core/#Namespaces :
Prefix Namespace Description oa http://www.w3.org/ns/oa# The Open Annotation ontology cnt http://www.w3.org/2011/content# Representing Content in RDF dc http://purl.org/dc/elements/1.1/ Dublin Core Elements dcterms http://purl.org/dc/terms/ Dublin Core Terms dctypes http://purl.org/dc/dcmitype/ Dublin Core Type Vocabulary foaf http://xmlns.com/foaf/0.1/ Friend-of-a-Friend Vocabulary prov http://www.w3.org/ns/prov# Provenance Ontology rdf http://www.w3.org/1999/02/22-rdf-syntax-ns# RDF rdfs http://www.w3.org/2000/01/rdf-schema# RDF Schema skos http://www.w3.org/2004/02/skos/core# Simple Knowledge Organization System trig http://www.w3.org/2004/03/trix/rdfg-1/ TriG Named Graphs
TIL about "Open Annotation Data Model" W3C Community Draft (2013)
https://github.com/hypothesis/h#development
See the project wiki for the roadmap and additional information and join us in #hypothes.is on freenode for discussion.
http://docs.python.org/2/library/decimal.html
From http://www.reddit.com/r/Python/comments/1k31m9/pep_450_adding_a_statistics_module_to_the/cbl5nj8 :
From here:
(TIL Python floats are like IEEE-754 binary64 doubles, which have 53 bits of precision and that BigFloat wraps GNU MPFR in order to utilize arbitrary-precision arithmetic, while gmpy2 implements "a new mpfr type based on the [MPFR] library".)
... sympy also wraps MPFR: http://docs.sympy.org/dev/modules/mpmath/technical.html#precision-and-representation-issues
Khan Academy seems to do a good job with presenting or not presenting a calculator for introductory algorithmic exercises.
https://www.khanacademy.org/library #Math
Realistically, I never use a graphing calculator to write reproducible, testable, verifiable analyses.
In retrospect, I would have much rather been required to deliver a Python script which produced reproducible, testable answers.
AFAIU, there's no analog of %logstart -o problem_1.py with existing graphing calculators from any manufacturer.
I think understanding math as the tests for science is crucial.
Cornice + SQLAlchemy + Colander: https://github.com/mozilla-services/cornice-sqla/blob/master/examples/blog/myblog/views.py
%rehashx will create aliases for each executable found in the directories listed in $PATH
http://ipython.org/ipython-doc/stable/interactive/shell.html#aliases
http://cwe.mitre.org/data/definitions/20.html #relationships
http://cwe.mitre.org/data/definitions/74.html #relationships
... "IPV4 regex" / "IPV6 regex"
http://en.wikipedia.org/wiki/Luciferase (bioluminescence like in fireflies)
Well that's a tricky question and may require some coordination with Enthought.
Probably a better option would be for the IPython developers to insist that Canopy have a button in its GUI called "Upgrade IPython".
Canopy
IPython
Applications/Canopy.app/appdata/canopy-1.3.0.1715.macosx-x86_64/Canopy.app/Contents/bin/enpkg
https://en.wikipedia.org/wiki/Filesystem_Hierarchy_Standard#Directory_structure
It sounds like you are suggesting that reddit feature development is stagnant because there is an (excellent) third party extension which also adds features.
That was a serious question. Markdown live preview would be value-added in terms of content quality and user experience. That's probably why it's also in RES.
This is like a 10 line patch and a push to CDN.
How many users do you think know about or have RES installed in their browser?
Maybe only load the editor widget onRelease?
Maybe only load the editor widget onRelease?
GitHub and StackExchange sites support live Markdown preview without an extension.
1. a. IPython is built on a two-process model; there's a Kernel and there are Clients (console, qtconsole, notebook). http://ipython.org/ipython-doc/stable/overview.html#decoupled-two-process-model
c. Demo notebooks: From http://ipython.org/
To get started with the IPython Notebook, see our official example collection [1]. Our notebook gallery [2] is an excellent way to see the many things you can do with IPython while learning about a variety of topics, from basic programming to advanced statistics or quantum mechanics.
To learn more about IPython, you can watch our videos and screencasts, download our talks and presentations, or read our extensive documentation. IPython is open source (BSD license), and is used by a range of other projects; add your project to that list if it uses IPython as a library, and please don’t forget to cite the project.
.2.
.2a. Local installs are the better option. If there are no OS-level resource constraints on CPU and RAM, execution of arbitrary code provided over the internet in any language is inviting resource exhaustion (DOS). (e.g. say python -c '1000000**1000000' five times fast)
.2b. As far as reproducible scientific workflows, I prefer the GitHub forge model (e.g. for bundling data with a notebook, revision control, writing and running automated tests). jsFiddle is quite novel; but there's no Ctrl-C (infinite loop -> browser crash -> lost work). http://nbviewer.ipython.org/ is read-only. I suppose there is room for more Cloud Services on the /r/ipython sidebar. See 2a.
.3. What would you suggest adding to the IPython installation documentation to help someone experiencing the same difficulties with the PATH variable (on OSX)?
.4. Distribution authors can certainly contribute patches upstream.
.5.
.5a. Installation: enpkg ipython and conda install ipython[-notebook] really raise the bar.
.5b. GUI Launcher: You could create a shortcut [3]. There could be a start/stop/log GUI [4].
.6. See 5
.7. See 1c
.8. Scratch is very cool. The visual approach to programming is a great way to learn simple programming constructs. http://code.org/learn lists a number of additional useful resources.
For a learning lab environment, automated configuration management is a must. SaltStack is a configuration management system written in Python. Something like "salt-conda" would make it very easy to install complete anaconda and/or customized miniconda environments on-demand (daily).
There are lots of GUIs for package management tools. I could see how it would be convenient to create an application shortcut for launching an IPython kernel in a terminal and an IPython notebook browser tab (run ipython notebook). See 4a. and 5. and /u/takluyver point 5.
Is there a reason you don't want to encourage / expect / instill an understanding of the commandline?
There are many Python IDE GUIs. Some will even run tests and present a green or a red light. AFAIK, there are no issue tickets requesting said feature at https://code.google.com/p/spyderlib/ .
Browser-based JavaScript platforms and environments do look promising. See 2a. There is a lot of movement there. For working with infinite loops, I like my Vim and Terminal.
What a helpful exercise!!
[EDIT] Markdown
[2] https://github.com/ipython/ipython/wiki/A-gallery-of-interesting-IPython-Notebooks
[3] https://stackoverflow.com/questions/18291232/shortcut-to-running-mac-terminal-commands
[4] https://code.google.com/p/google-appengine-mac-launcher/ (Apache 2.0)
Canopy and Anaconda are Python package distributions. They review and bundle sets of package versions that work well together.
IPython is an interactive Python REPL with <tab> completion and <object>? (docs) <object>?? (source) introspection, among many other cool features.
IPython notebook is a web-based GUI version of IPython which supports displaying things like plot graphics, videos, and HTML inline within an IPython notebook.
An IPython notebook file (.ipynb) is a JSON file which contains both source code input and rendered output that is generated when an input 'cell' is run. (<Shift-Enter>, <Ctrl-Enter>, point and click menu).
https://support.enthought.com/forums
http://docs.enthought.com/canopy/
Canopy is the next generation of the Enthought Python Distribution (EPD), adding an advanced text editor, integrated IPython console, graphical package manager and online documentation to Enthought’s proven Python distribution. The Canopy analysis environment streamlines data analysis, visualization, algorithm design and application development for scientists, engineers and analysts.
http://docs.continuum.io/anaconda/
Anaconda is a free collection of powerful packages for Python that enables large-scale data management, analysis, and visualization for Business Intelligence, Scientific Analysis, Engineering, Machine Learning, and more.
http://conda.pydata.org/miniconda.html
These Miniconda installers contain the conda package manager and Python. Once Miniconda is installed, you can use the conda command to install any other packages and create environments, etc.
If all you need or want is IPython, the 20MB Miniconda download installs a Python interpreter and conda. Once you have created a conda environment, you can then install just IPython (and IPython notebook) with conda install ipython-notebook.
conda and enpkg serve similar package mangement purposes.
It looks like when you run sudo enpkg, enpkg is not in your $PATH variable.
echo $PATH
sudo bash -c "echo $PATH"
which enpkg
sudo which enpkg
# careful here
sudo $(which enpkg) <command>
Not everyone has or wants to use root privileges to run software downloaded from the internet. It is (and should be) possible to manage Python packages with either conda or enpkg without sudo (root privileges). If you run conda or enpkg as root, the installed files will be owned by root.
I'm expecting something cool like an open source Mathematica.
Mathematica does things that no single Python package does. It is possible to do things with one or more Python packages - like producing software with automated tests - that cannot be done with Mathematica.
These are the packages included with each distribution:
SymPy is included with both Anaconda and Canopy. SymPy provides some features like Mathematica:
As far as doing cool stuff with IPython notebook:
By the way [...] Wakari
The Wakari free plan offers 512MB of RAM and 10GB of disk space. The 30 day free trial is for the Pro plan with more resources and SSH access.
AFAIK, there's not yet an internally hostable version of Wakari. You could create something similar with a VPS-type hosting system like OpenStack (e.g with the Docker hypervisor), GateOne HTML5 SSH terminal emulator, and the Anaconda package set; but then you'd need to manage configuration and updates for one or more servers as well. Anaconda Server would help minimize the amount of duplicate package downloads necessary to maintain such an infrastructure.
For the average bear, a local install of Canopy or Anaconda will support IPython, IPython qtconsole, and IPython notebook just fine.
If you want to need to install build dependencies for regular Python packages in a virtualenv (work with OS packages and setuptools (pip) packages rather than enpkg and conda packages), I wrote this awhile ago https://gist.github.com/westurner/3265445; it may still work.
Within a conda environment, you can utilize pip install as well as conda install. I have never tried with Canopy. For a Python import statement to succeed, the package must be found within the directories listed in sys.path:
which python
python -m site # python -c 'import sys; print("\n".join(sys.path))'
http://andreacensi.github.io/contracts/
PyContracts is a Python package that allows to declare constraints on function parameters and return values. It supports a basic type system, variables binding, arithmetic constraints, and has several specialized contracts (notably for Numpy arrays).
(@decorators, Python 3 annotations, docstrings)
I know some people go into HR or consulting but I'm not sure specifically what a consultant does other than attempt to improve efficiency and hirings. What other jobs are available for a I/O graduate? What are the job differences for someone who received a degree in I/O vs a degree in Human Resources?
https://en.wikipedia.org/wiki/Applied_psychology#Industrial_and_organizational_psychology
https://en.wikipedia.org/wiki/Industrial_and_organizational_psychology#Topics
https://en.wikipedia.org/wiki/Industrial_and_organizational_psychology#Types
https://en.wikipedia.org/wiki/Human_resource_management#Practice
https://en.wikipedia.org/wiki/Chief_human_resources_officer#Responsibilities
How does (Shannon) Entropy fit into this? http://en.wikipedia.org/wiki/Entropy_(information_theory)
https://en.wikipedia.org/wiki/Paracetamol (Acetaminophen, APAP)
http://www.nlm.nih.gov/medlineplus/druginfo/meds/a681004.html
[Posted 01/14/2014] ISSUE: FDA is recommending health care professionals discontinue prescribing and dispensing prescription combination drug products that contain more than 325 milligrams (mg) of acetaminophen per tablet, capsule or other dosage unit. There are no available data to show that taking more than 325 mg of acetaminophen per dosage unit provides additional benefit that outweighs the added risks for liver injury. Further, limiting the amount of acetaminophen per dosage unit will reduce the risk of severe liver injury from inadvertent acetaminophen overdose, which can lead to liver failure, liver transplant, and death.
Cases of severe liver injury with acetaminophen have occurred in patients who:
- took more than the prescribed dose of an acetaminophen-containing product in a 24-hour period
- took more than one acetaminophen-containing product at the same time; or
- drank alcohol while taking acetaminophen products.
https://en.wikipedia.org/wiki/Paracetamol_toxicity "is the most common cause of acute liver failure [in the United States and the United Kingdom]"
Is it possible to yield graphene from CO2?
https://en.wikipedia.org/wiki/Graphene#Potential_applications:
WebOb does not offer API documentation for its exception classes, and I had to look at the source. It would be nice if WebOb included API documentation for these.
https://github.com/Pylons/pyramid/blob/master/pyramid/httpexceptions.py
http://docs.pylonsproject.org/projects/pyramid/en/latest/api/httpexceptions.html
http://docs.python.org/2/howto/unicode#reading-and-writing-unicode-data
http://docs.python.org/3/howto/unicode#reading-and-writing-unicode-data
import codecs
with codecs.open(fname, 'r', encoding='utf-8') as f:
lines = f.read().splitlines()
A breakdown of polyunsaturated fats specifying Omega 6 and Omega 3 would be outstanding:
EDIT:
Here's the direct link to the comments page (which is open until Jun 02, 2014):
http://www.regulations.gov/#!documentDetail;D=FDA-2012-N-1210-0002
- POLYUNSATURATED FAT
[...] c. Declaration of Individual Polyunsaturated Fatty Acids—The declaration of individual polyunsaturated fatty acids on the Nutrition Facts label is not permitted.
[...] Because of the lack of well-established evidence for a role of n-3 or n-6 polyunsaturated fatty acids in chronic disease risk and the lack of a quantitative intake recommendation, and consistent with the factors discussed in section I.C., we tentatively conclude that the declarations of n-3 and n-6 polyunsaturated fatty acids are not necessary to assist consumers to maintain healthy dietary practices. Accordingly, we are not proposing to provide for the individual declaration of either n-3 or n-6 polyunsaturated fatty acids on the Nutrition Facts label. Similarly, because of the lack of well-established evidence for a role of EPA and DHA in chronic disease risk and the lack of a quantitative intake recommendation, consistent with the factors discussed in section I.C., we tentatively conclude that the declarations of EPA and DHA are not necessary to assist consumers to maintain healthy dietary practices. Accordingly, we are not proposing to provide for the mandatory or voluntary declaration of EPA or DHA on the Nutrition Facts label. We request comment about whether there is an appropriate alternative analysis to the application of the factors in section I.C. regarding the individual declaration of n-3 or n-6 polyunsaturated fatty acids, as well as EPA or DHA.
I think voluntarily specifying n-3/n-6 should be permitted.
https://en.wikipedia.org/wiki/Data_science
By the way, would it be advisable to use wsgi instead of cgi?
CGI must spawn a new process for each request: startup initialization, imports, configuration, database connection. ( http://en.wikipedia.org/wiki/Strace )
Thinking about using Python's 3 http server to run the scripts, but would like to know what would be the advantages of running frameworks like Flask, Web.py, Bottle.
I would like to keep it as simple as possible, and even try to run AirPlay as a background process in the Pi, if possible.
https://github.com/ryatkins/videoAirPi
https://github.com/PascalW/Airplayer :
Airplayer is no longer under active development. XBMC users can use the built-in Airplay support which is available since XBMC 11 (Eden).
If you have quizzes and exams, they're probably derived from the assigned textbook. Nonetheless, here are some resources which may be helpful:
Theory / Concepts
http://www.reddit.com/r/compsci/comments/1e3mht/is_rdbmss_and_sql_still_part_of_the_standard/#c9xz34s (and #c9x5nsm)
.
.
An exercise
(how I learned)
Learn Turtle RDF syntax by example:
Describe instances of things relevant to the chosen subject matter (in a Turtle text file: instances.ttl)
"text"@en literals<URI> are (labels in multiple languages, descriptions)Distill an OWL/RDFS ontology from instances.ttl (ontology.owl.ttl)
rdfs:Classrdf:Property
rdfs:Domainrdfs:RangeCheck the Turtle syntax
rapper -i turtle -o turtle instances.ttl)Load each TTL file in Protege. Explore. "Save as" and compare. (Are #comments preserved?)
Inference, Reasoning, Entailment
...
There are tools for working with BibTeX in http://schema.org/ScholarlyArticle s.
What are some best practices for working with citations as RDF and BibTex?
MediaWiki's Javascript support for references and footnotes is pretty cool; but it's not necessarily structured data.
We can encode structured citation metadata within HTML as e.g. RDFa and JSON-LD.
How and where do we store metadata for PDFs?
There are mechanisms for PDF metadata. Most require tool support in the form of a dialog for entering text into the fields. In most cases, PDFs do not include enough metadata to, for example, extract a suitable citation.
PDF, like HTML, is derived from SGML. Links and executable scripts can be encoded within PDF. It is even possible to execute system commands from within a PDF; given unsafe or outdated PDF reader configuration.
As a Portable Document Format, PDFs can be emailed, hosted, and stored in structured repositories, such as Journals. Usually, there's a field in a separate system which an author must copy, paste, and reformat an abstract into.
With RDFa, we can add markup to denote metdata; for example, a <p> tag, with something like <p property="schema:description">.
How do we deliver a PDF and Datasets as a bundled package (with stable URIs and URLs)?
We can create a .ZIP (or similar) archive of multiple files, add a manifest file with metadata, and call it a package. Metadata stored inside compressed content necessarily uses relative resource identifiers, and must be uncompressed.
https://en.wikipedia.org/wiki/File_sharing
https://en.wikipedia.org/wiki/Namespace
"What is a Dataset?"
Is a PDF a Dataset, or is a PDF a document which can link to or include a stylized table of a Dataset?
A table of data within a PDF is:
https://en.wikipedia.org/wiki/Separation_of_presentation_and_content
Data Analysis can (and should) be automated through the use of theory, tools, and procedures. [1, 5, 6, 7, 8]
Does that make statistical and data analysis learning a moot point? Absolutely not. [2, 3, 4]
Is the "'black magic' part" a source of bias? [9]
What does it mean to be "triple blind"?
"Can Data Analysis be Automated?" http://www.reddit.com/r/statistics/comments/1h7oat/can_data_analysis_be_automated/
"What level of mathematics knowledge would I need to have in order to be able to understand the 'why's underpinning statistics?" http://www.reddit.com/r/statistics/comments/1ra5fj/what_level_of_mathematics_knowledge_would_i_need/cdlb8y6
"I'm looking for a good statistics review or instructional site for AP Statistics." http://www.reddit.com/r/statistics/comments/1yi9fr/im_looking_for_a_good_statistics_review_or/
"What should I be minoring in as an undergrad majoring in Statistics?" http://www.reddit.com/r/statistics/comments/1yhih9/what_should_i_be_minoring_in_as_an_undergrad/
As a procedure for "folding" and "projecting" data into a manifold from which the visual cortex can identify patterns, data visualization is a useful tool.
Tools:
"You have 30 minutes to teach business folk about data science - go" http://www.reddit.com/r/datascience/comments/1xxsvh/you_have_30_minutes_to_teach_business_folk_about/cffzl9b
"RFC: Blinding, Bias, Null Hypotheses, Reproducibility and Statistical Analysis" http://www.reddit.com/r/statistics/comments/1rt6yl/rfc_blinding_bias_null_hypotheses_reproducibility/
- Rule 1: For Every Result, Keep Track of How It Was Produced
- Rule 2: Avoid Manual Data Manipulation Steps
- Rule 3: Archive the Exact Versions of All External Programs Used
- Rule 4: Version Control All Custom Scripts
- Rule 5: Record All Intermediate Results, When Possible in Standardized Formats
- Rule 6: For Analyses That Include Randomness, Note Underlying Random Seeds
- Rule 7: Always Store Raw Data behind Plots
- Rule 8: Generate Hierarchical Analysis Output, Allowing Layers of Increasing Detail to Be Inspected
- Rule 9: Connect Textual Statements to Underlying Results
- Rule 10: Provide Public Access to Scripts, Runs, and Results
Sandve GK, Nekrutenko A, Taylor J, Hovig E (2013) Ten Simple Rules for Reproducible Computational Research. PLoS Comput Biol 9(10): e1003285. doi:10.1371/journal.pcbi.1003285
https://github.com/hgrecco/pint/blob/master/AUTHORS
Just a fan. Two advantages:
str.format string formatting (plaintext, Pretty, LaTeX, HTML) https://pint.readthedocs.org/en/latest/tutorial.html#string-formattingThanks StackExchange community, for the Creative Commons 3.0 Attribution ShareAlike license: http://creativecommons.org/licenses/by-sa/3.0/ :0)
http://blog.stackoverflow.com/2014/01/stack-exchange-cc-data-now-hosted-by-the-internet-archive/
I guess the offline dumps are updated sporadically and the online dumps are updated weekly: http://data.stackexchange.com
... Seed the data which you feel is reputable.
https://en.wikipedia.org/wiki/Bittorrent#Web_seeding
[EDIT]
The scientific community doesn't have a github mentality, though.
https://en.wikipedia.org/wiki/Forge_(software)
https://en.wikipedia.org/wiki/List_of_collaborative_software
...
https://en.wikipedia.org/wiki/Open-source_software_security#The_debate
https://en.wikipedia.org/wiki/Open_access_publishing
https://en.wikipedia.org/wiki/File:Graham%27s_Hierarchy_of_Disagreement.svg
...
"Ten Simple Rules for Reproducible Computational Research"
http://www.ploscompbiol.org/article/info%3Adoi%2F10.1371%2Fjournal.pcbi.1003285
- Rule 1: For Every Result, Keep Track of How It Was Produced
- Rule 2: Avoid Manual Data Manipulation Steps
- Rule 3: Archive the Exact Versions of All External Programs Used
- Rule 4: Version Control All Custom Scripts
- Rule 5: Record All Intermediate Results, When Possible in Standardized Formats
- Rule 6: For Analyses That Include Randomness, Note Underlying Random Seeds
- Rule 7: Always Store Raw Data behind Plots
- Rule 8: Generate Hierarchical Analysis Output, Allowing Layers of Increasing Detail to Be Inspected
- Rule 9: Connect Textual Statements to Underlying Results
- Rule 10: Provide Public Access to Scripts, Runs, and Results
https://en.wikipedia.org/wiki/Traceability#Software_development
https://en.wikipedia.org/wiki/Continuous_integration#Principles
- Maintain a code repository
- Automate the build
- Make the build self-testing
- Everyone commits to the baseline every day
- Every commit (to baseline) should be built
- Keep the build fast
- Test in a clone of the production environment
- Make it easy to get the latest deliverables
- Everyone can see the results of the latest build
- Automate deployment
...
https://en.wikipedia.org/wiki/Meta-analysis
https://en.wikipedia.org/wiki/Criterion
http://www.prisma-statement.org/statement.htm
...
"Code review for science: What we learned"
http://mozillascience.org/code-review-for-science-what-we-learned/
Yeah. Well. When scientists are fully funded by public society with guarantee of livelihood, then your view will make a little more sense. Despite your comment about public funds, you clearly don't understand scientific research at all.
So hire a publicist.
And I don't mean to imply it's acceptable to discount all your opinions just because you're not a scientist, but I just want you to know that it is plain as day you don't know anything about scientific research JUST based on you having the opinion you do. That's just how far disconnected your opinion is. Those of us working in science know the reality is much harsher and your opinion makes absolutely zero sense.
First, that's ad-hominem.
Second, here's "Graham's Hierarchy of Disagreement"
https://pbs.twimg.com/media/Bfupf8nCQAATp7r.jpg
Third, there must be conflicting definitions about what "science" means. To the knowledgeable taxpayers of the United States, "science" means producing work which specifies sufficient study controls so as to demonstrate significant, un-confounded, reproducible outcomes.
The reality is if someone doesn't take the attitude of protecting their research results UNTIL they have published significant results, they will get "scooped" - that term doesn't exist in science for no reason. I've been scooped on papers by both Indian and Chinese research groups. And you know what's worse? Their papers were bullshit. They scooped the general idea of research I was working on, copied my results (that they found out through shady channels, like guest researchers), and completely fabricated the data / experimentation sections. And even when they do the experiments the results are often doctored.
The reality of it is if you're not already isolating extraneous sources of noise, you're not producing reproducible science anyway.
Was there a URI or an immutable repository that either of you could guessticulate towards?
But guess who that hurts? Them? Haha. They got published. They'll get grants in the future for the work I did, and I will NOT get those grants, and no one will repeat their experiments because the field is too niche, or they'll assume they're just doing something different. That's how it is, that's reality for most researchers.
Is it not worth verifying, validating, and reproducing?
I've learned from my mistakes and what happens is you always work about 2-3 steps ahead of your publications. You never publish findings as soon as you get them, and you keep a fairly tight lid on your results until something is past review. Why? Because of dishonest researchers, and they exist because the funding and credit system in science is BROKEN.
"You keep a fairly tight lid on your results" because you don't want to bias similar experiments with premature analyses.
So don't tell this guy he has to give his ideas away for free so that every two-bit moron from China can steal the results or he's being selfish. That's total crap.
So don't tell this taxpayer she has to invest in ego.
Edit to continue: To get back to the topic of this entire thread - researchers should share as much information as is possible without undermining their own future credit for discoveries. If you think that's not good for science, then you somehow get the academic system to stop rewarding people for making discoveries. If you only want to reward those who make discoveries, you're going to force people to hold out on critical information to making discoveries until they can get around to doing it themselves. The system as it stands is HAPPY to let someone publish one paper with an awesome idea that leads to hundreds of discoveries... and that counts as one publication. Sure, it's an important publication right? But no single publication is worth 100 small publications, even if it effectively opened the stopgap for all of them. So the system encourages people to hoard their good ideas and trickle them out like bread crumbs, so they can survive in a ruthless system. If your idea gets stolen in academia, your livelihood is stolen.
I think there's an implicit point here about grant funding as a positive feedback for valid science. That's not possible without review.
No-one wants to pay for "it's totally secret so it works".
In some fields it's so competitive that for the amount of work you do, you get paid basically nothing. In physics for example, I know there is an unbelievable number of people who hardly break-even paying rent and food, working as post-docs in academia. If you aren't independently wealthy or have a spouse who can help with the bills, you probably can't afford to work in physics research. This is my own observation, it may not be entirely true for the whole field, but the fact that I see it at all is very telling of how little funding is given to physics research.
Unfortunately that's true for many fields. The Occupational Outlook Handbook lists fields with median pay.
As a scientist I see two paths in academia - release a huge paper with a great idea, get some recognition for it but many people will likely not appreciate the impact of the paper or downplay it, and then use the idea to expand on your work into tens or hundreds of other papers. You will get money for maybe 5, maybe even 10 years, based on that publication if you're really lucky and the impact is NOT downplayed. But if you don't make some more big advances by then the spotlight will have faded and you'll be back to no funding and no scientific advantage over anyone else. The competitive nature of science means you'll probably get pushed out unless you can again come up with a big idea.
You can work for taxpayer money, probably through a University or a Lab.
Or you can hoard your idea for a while, make many smaller releases by exploiting your idea to the fullest extent you can before the cat gets out of the bag. You build yourself up for years with solid publications and you can likely get tenure or at least a more solid research position, you look far more productive instead of a "one hit wonder."
Or you can pitch to investors who aren't obligated to invest in bad research.
TL;DR Let me summarize the problem with an analogy. Say you crash land on an island with limited resources, just you and one other person, and there is enough food for one person to live 6 months. Every month you're alive, it's more likely you'll be rescued (although for this analogy to hold you'd be rescued only to crash land on the next island and repeat this scenario). You both know the situation, but to get access to the food you need a skill that you spent years developing on your own, the other person doesn't have this skill. The question for you is: would you teach them that skill??
Say you crash land on an island with limited resources. One book says it's edible; one book doesn't. One guy's worried about whether his face is pasted into the jacket.
This may be a question for a different avenue: how is that not confirmation bias? (e.g. "common sense" from Cox's theorem; and t) Is this a framework for probability logic?
If you decide to create a new github issue, it would be helpful to include: Python version(s), IPython version(s), a complete traceback, and reference "#2495 , #4849" in the description.
Python 3 supports Unicode, but not all libraries are ported yet.
https://github.com/ipython/ipython/issues/new
re: Python 2 mimetypes.py and Unicode MIME type Windows registry keys:
http://bugs.python.org/issue9291
Also fixed in Python 3.
http://en.wikipedia.org/wiki/Cox%27s_theorem
Maybe "Correlation may indicate plausible correlation"?
... There's an assumption of complete and perfect information that is not valid.
https://en.wikipedia.org/wiki/Statistics#Specialized_disciplines
https://en.wikipedia.org/wiki/List_of_fields_of_application_of_statistics
( https://en.wikipedia.org/wiki/Computational_statistics )
For the business courses I would take classes along the lines of Econometrics and Six Sigma.
+1
http://www.kevinsheppard.com/wiki/Python_for_Econometrics
https://en.wikipedia.org/wiki/Six_Sigma#DMAIC
https://en.wikipedia.org/wiki/Validated_learning
http://www.ploscompbiol.org/article/info%3Adoi%2F10.1371%2Fjournal.pcbi.1003285
https://en.wikipedia.org/wiki/Statistics
https://en.wikipedia.org/wiki/Probability_theory
https://en.wikipedia.org/wiki/Outline_of_statistics
https://en.wikipedia.org/wiki/Notation_in_probability_and_statistics
https://en.wikipedia.org/wiki/List_of_mathematical_symbols
http://apcentral.collegeboard.com/apc/public/courses/teachers_corner/2151.html
https://www.khanacademy.org/math/probability
re: https://en.wikipedia.org/wiki/Toxoplasmosis#Epidemiology
The parasite infects most genera of warm-blooded animals, including humans, but the primary host is the felid (cat) family [emphasis added]. Animals are infected by eating infected meat, by ingestion of feces of a cat that has itself recently been infected, and by transmission from mother to fetus. Cats are the primary source of infection to human hosts, although contact with raw meat, especially lamb, is a more significant source of human infections in some countries. Fecal contamination of hands is a significant risk factor.
Here's another:
A: Patient suffered abuse (physical, verbal, psychological)
B: Patient experienced head injury (TBI, CTE)
C: Patient avoids contraindicated medication
D: Patient has PTSD and depression
E: Patient played sports
I suppose the data here is sufficient.
Here's one:
A: Patient takes heart medication
B: Patient has heart disease
How does correlation imply causation in this counter example?
Are you asking for counter examples from the natural sciences?
https://en.wikipedia.org/wiki/Big_data
https://en.wikipedia.org/wiki/Wikipedia:Database_download
https://developers.google.com/freebase/data
http://wiki.dbpedia.org/Downloads
https://aws.amazon.com/datasets
search: 'large datasets'
https://www.quora.com/Data/Where-can-I-find-large-datasets-open-to-the-public
https://stackoverflow.com/questions/2674421/free-large-datasets-to-experiment-with-hadoop
Ah, a \n between suggested completions. Yup not sure how to do that.
Both diesel exhaust and shale oils are carcinogenic to humans (2012).
nor am I trying to parse/complete argv-styled parameters
So you are trying to create an interactive REPL with completion which does not accept arguments from the commandline? (a "command line parser")
If your requirements are such that you must reinvent the wheel and/or maintain state:
If you also want to accept normal unix-y shell parameters (so you can pipe and redirect command output), a cmd loop which prints a subset of argparse.ArgumentParser.format_help may be helpful:
http://documentup.com/skwp/git-workflows-book Chapter 4 is also great.
I'd like to know about your workflow.
Do you use version control (git?) in your projects or is it overkill most of the time?
Git, hg (because it's mostly immutable), gists
"Ten Simple Rules for Reproducible Computational Research" http://www.ploscompbiol.org/article/info%3Adoi%2F10.1371%2Fjournal.pcbi.1003285
Rule 4: Version Control All Custom Scripts
That may be the most expressive way to describe FAQ questions and answers with just the schema.org ontology.
I'm not aware of any guidance regarding how many types could/should be specified for an Organization with one or more LocalBusiness es.
For microdata syntax there's http://schema.org/additionalType .
For RDFa (as the additionalType docs specify), rather than repeating typeof, you can specify a space-delimited list: http://www.w3.org/TR/xhtml-rdfa-primer/#repeating-properties
Similarly to
property,typeofalso accepts a list of values.
From http://schema.org/docs/full.html :
Thing > Action > InteractAction > CommunicateAction
Thing > CreativeWork
A Question/Answer format may be a good candidate for http://www.w3.org/wiki/WebSchemas/SchemaDotOrgProposals .
It sounds like you're looking for the following types?
Would it be relevant or helpful to describe what sort of dialogue / cognitive expression a FAQ page is?
For your use case, would it be useful to have an inductableFrom predicate?
Protégé https://en.wikipedia.org/wiki/Prot%C3%A9g%C3%A9_(software)
https://en.wikipedia.org/wiki/Redland_RDF_Application_Framework
rapper -i rdfxml -o turtle opencyc-latest.owl | less (| vim - w/ n3.vim)
I see myself scraping data, using social media API's and importing CSVs from world bank etc.
I also would want to do OS scripting etc. Would appreciate any feedback.
re: https://en.wikipedia.org/wiki/Meta-analysis
TIL about "The PRISMA Statement": http://ww.prisma-statement.org/statement.htm
https://en.wikipedia.org/wiki/Data_science
Theory
Math
Analysis
Science
Tools
Techniques
Standard, Automated Workflows
Data Visualization
Further Resources
The idea of quantifying or qualifying team competence in a system as 'competence debt' seems alluring.
Over the years I have worked on a number of replacement projects. Looking back I realize that the real motive for many of these replacements was a severe competence debt in the old system. People would claim that the old system was impossible to maintain when the real problem was that they did not understand how it worked. Yes, technical debt made things worse since the confusing code and lack of automated tests made it frustrating to understand the system. The impulse to rewrite typically comes when too few of the original developers are left and the business is unable to find new developers that are able or willing to learn.
Absolutely.
With no data to support my position, I find it far more likely that a team with intentions to reverse and improve an existing system will produce a more efficient system with less risk.
Unfortunately, replacing a system just because the competence debt in the old one is too high is seldom a good idea. [...] The cost of replacing is often an order of magnitude higher than expected. Ironically, the process of replacing a system often forces developers to study the old system, thereby reducing competence debt in it…
While in some cases it may seem to be cheaper to retrofit an existing system because of sunk costs, I think such a perspective fails to account for risk.
Which of these costs are due to "Technical Debt" and which are due to "Competence Debt"?
The whole project lacks meaning for the users since the new system will not give them any visible improvements. [...] Increased maintainability is seldom at the top of users wish lists.
Which users are qualified to estimate confidentiality, integrity, and availability metrics in terms of risk?
"Looks great from the street"
If I can widen the synchronous support to include Python 2.X (by finding a replacement for ssl that supports NPN), I'd rather have than than asyncio support.
I guess bewteen ./Modules/_ssl.c, ./Lib/ssl.py, pypi:ssl, and pypi:backports.ssl_match_hostname, there's no support for TLS https://en.wikipedia.org/wiki/Next_Protocol_Negotiation in Python 2.
https://en.wikipedia.org/wiki/HTTP_2.0
Thanks!
Asynchronous Python and HTTP 2.0 Server Push
Without committing to an asynchronous model (such as asyncio), it may be difficult to specify a callback interface that just NOPs when callback is None.
Here's one example of asyncio with HTTP: https://github.com/fafhrd91/aiohttp/blob/master/aiohttp/client.py
It'd probably be helpful to get a head start in Computer Science by taking https://en.wikipedia.org/wiki/AP_Computer_Science . I took the AB exam which is not offered anymore and wasn't prepared; though it was helpful later.
Python Versions
While it's possible to do from __future__ import print_function in Python 2, if the code contains calls to print followed by a space (like print "text") it is Python 2.
Compatibility Layers
Books and Resources
This is my first language, I have a Microbiology research background.
Welcome!
If you're not looking to write and wade through LaTeX, Sphinx and ReStructuredText may be helpful.
https://en.wikipedia.org/wiki/ReStructuredText is a lightweight markup syntax that is built into HTML, LaTeX, PDF, ePub, mobi, etc. with tools like Sphinx and rst2pdf.
https://en.wikipedia.org/wiki/Sphinx_(documentation_generator)
Creating a PhD thesis is typically done using LaTeX. This works really well for producing a PDF, but a giant PDF file is not a great way to put documents on the web. There are solutions that exist to turn latex source files into HTML, but in my experience, they tend to produce poor HTML output.
Vim support:
:set nofoldenable):voom rest for an outline)HTML Themes:
Something with a tab-completing REPL loop that supports IPython's "rich display system" (._repr_html_, ._repr_svg_, ._repr_png_, ._repr_latex_, ._repr_json_) for e.g. matplotlib, seaborn, mpld3? (For GUI, web, and publication?)
[EDIT] /r/ipython
So pefix 'private' variables with __ so they are name mangled and nothing can touch them evar; and define a @property without a setter. It's a reference counted language. You may find smart pointers more amenable.
Yes C++ can look nice. But the difference is that there are few if any conventions within the language that force this to be the case. If you only work in your own code, great, congratulations, none of this matters to you.
But for the vast majority of us who code in the real world, having common conventions enforced at the language level, rather than at the level of the individual or the institution, results in a major boon to readability, comprehensibility and ultimately productivity and sanity.
C++ doesn't even have anything like PEP-8. Instead each company or institution has it's own 'style guide' which we all know is never enforced, rarely comprehensive and never consistent with other standards.
.. And the style guides all strongly suggest indicating block chunking with consistent indentation.
How not learning reflection is rationalized as an excuse for being discourteously lazy enough to not produce indented readable code is beyond me. The same goes for multi-line lambdas: it's a function: it should have a __name__ and a __doc__ string, if nothing else so that profiling and static analysis tools have more than a line number to reference.
A commented reference to https://pypi.python.org/pypi/backports.ssl_match_hostname may also be helpful.
For webapps, http://yeoman.io is great (yo, grunt, bower).
I haven't had the chance to work with future. nine seems to work. https://github.com/nandoflorestan/nine/blob/master/nine/__init__.py
https://en.wikipedia.org/wiki/Forge_(software)
https://en.wikipedia.org/wiki/Comparison_of_open-source_software_hosting_facilities#Features
User stories as tickets/issues works just about anywhere. More specialized tools have support for grouping and charting groups of user stories (e.g. "epics"). If a burn down chart isn't essential, tags work fine. Wiki pages work great for release plans.
If you are committed to automated testing, issue/ticket integration with https://en.wikipedia.org/wiki/Continuous_integration#Principles can save some time. (https://en.wikipedia.org/wiki/Requirements_traceability)
Are these the people who are crusading against 'pot heads'?
Caffeine is a vasoconstrictor ... Moderation.
I've read about good results with restoring plasticity in the adult visual cortex with fluoxetine.
How many managers and leads do you need with https://en.wikipedia.org/wiki/Scrum_(software_development)#Roles?
Arguably, the Scrum Master should be "removing impediments to the ability of the team to deliver the product goals and deliverables".
User Stories -> Tests -> Build (which is the whole team's responsibility)
Passing tests [as read from a CI dashboard ].
If a manager can't write or stub out at least BDD tests, they have no business managing the team.
[EDIT] http://www.reddit.com/r/Python/comments/1drv59/getting_started_with_automated_testing/c9tfxgd
I’ve heard many people say that JSON-LD is primarily about the Semantic Web, but I disagree, it’s not about that at all. JSON-LD was created for Web Developers that are working with data that is important to other people and must interoperate across the Web. The Semantic Web was near the bottom of my list of “things to care about” when working on JSON-LD, and anyone that tells you otherwise is wrong. :P
TL;DR: The desire for better Web APIs is what motivated the creation of JSON-LD, not the Semantic Web. If you want to make the Semantic Web a reality, stop making the case for it and spend your time doing something more useful, like actually making machines smarter or helping people publish data in a way that’s useful to them.
Here! http://manu.sporny.org/2014/json-ld-origins-2/
...
TIL:
The specification is already deployed in production by companies like Google, the BBC, HealthData.gov, Yandex, Yahoo!, and Microsoft.
I haven't complained yet. I am not responding to baiting attempts at trolling and ad hominem. To suggest the superiority of Java (and now, Javascript) and inadequacy of Python, based on a hidden, contrived example of inappropriately reimplemented relational algebra algorithms is blatantly killing the vibe of an /r/Python advocacy post.
The resources I have linked provide some context for understanding where Python is in relation to high performance computing. Again, vbench may be helpful for drawing reproducible benchmarks of defined software implementations over time. Rather than wasting time here, I would suggest considering contributing resources toward optimizing specific algorithmic implementations in Python (or learning to utilize the many excellent open source Python libraries which already solve for relational algebra, in C).
If you actually read my link you would notice that I actually tried the builtin symmetric_difference()
The linked stackoverflow answer which utilized set.symmetric_difference has a different output signature than the other listed implementations. The builtin symmetric_difference does not maintain ordering (because of set).
https://wiki.python.org/moin/TimeComplexity#set
Pandas (implemented with CPython, NumPy, and Cython) is much faster than symmetric_difference; especially with so many records. The support for HDF5 (a popular HPC storage format) and PyTables further extends the performance gap for this particular use case.
[EDIT] Blaze BLZ format is also very fast.
Javascript is a dynamic scripting language but is significantly faster than Python according to various benchmarks when using v8.
New goalposts! I agree; every language has strengths and weaknesses. The maturity of the science, mathematics, and computer science libraries and communities in Python is a strong selling point.
A JIT implementation should be the default Python implementation, [...]
NumPyPy and CFFI are coming along quite nicely.
Thank you for sharing your experience with implementing relational algebra in a scripting language and expecting it to be as fast as native routines in a database (such as C, or Java).
http://pandas.pydata.org/pandas-docs/dev/comparison_with_sql.html
http://nbviewer.ipython.org/github/koldunovn/nk_public_notebooks/blob/master/Apache_log.ipynb
TLDR "Python is fast enough for many things" ... "Nuh uh, because Java. Here are some numbers"
You could post your implementations. Chances are, Cython (e.g. pandas) would be faster than Java or Python.
The 3900ms (times n) question may be: How long did it take to write it?
Thanks!
ReviewBoard, Gerrit, and GitHub are all great for code review.
Sandman looks perfect, thanks!
http://www.jeffknupp.com/blog/2013/08/21/sandman-is-the-top-trending-python-repo-on-github/
http://www.jeffknupp.com/blog/2013/12/20/your-database-just-got-its-own-website/
I had looked at Celery but it seemed a bit unintuitive about what it is and what it can do in this application.
Celery supports scheduled tasks, retries, and concurrency. It's fairly simple:
For monitoring task progress, there's flower (a web-based GUI built with tornado and websockets) and celery events (a curses based CLI).
http://en.wikipedia.org/wiki/Continuous_integration#Software
It's possible to install Bash almost anywhere, but I find it easier to write cross-platform scripts in Python (e.g. with os.path.sep, pathlib, or path.py). I think the Shining Panda and Selenium plugins for Jenkins CI are cross platform.
https://pypi.python.org/pypi/pathlib
The nose and py.test test runners both support test output as XUnit XML (natively or through a plugin that also must be installed on build machines) which Jenkins can collect and chart as build artifacts.
Relational (SQL) Databases
http://www.reddit.com/r/compsci/comments/1e3mht/is_rdbmss_and_sql_still_part_of_the_standard/c9x5nsm
https://en.wikipedia.org/wiki/Join_(SQL)
https://en.wikipedia.org/wiki/Object-relational_mapping
NoSQL Databases
https://en.wikipedia.org/wiki/NoSQL#Taxonomy
https://en.wikipedia.org/wiki/Relational_algebra#Joins_and_join-like_operators
Python
http://www.reddit.com/r/Python/comments/1eboql/python_website_tuts_that_dont_use_django/c9yxl8w
https://docs.djangoproject.com/en/1.5/intro/tutorial01/#creating-models
https://django-social-auth.readthedocs.org/en/latest/intro.html
http://docs.sqlalchemy.org/en/rel_0_9/orm/tutorial.html
PHP
http://symfony.com/doc/current/book/doctrine.html
[EDIT] https://en.wikipedia.org/wiki/Comparison_of_web_application_frameworks
You're right that the exchange doesn't create wealth, it's simply the realisation of wealth that both parties must have created to be involved in the exchange.
Look at it this way: in order for me to buy something worth $X from you, I must have earned it, and you must have created the something that was worth $X. Or, you must have purchased something worth $X from someone who created it. Or, they must have purchased something worth $X from someone who created it.... You get the idea, at some point someone created something worth $X.
Say I found a $1 bill on the street and decide to purchase a useless piece of plastic which you had found. Beyond the (now, quantifiable) utility, what value added is there in that transaction.
What has been created, in that transaction? Is that 'wealth' or (temporary) utility?
Either by digging that something out of the ground (to pick one way of "creating" a resource), or by doing something with something that was dug out of the ground.
That's a fairly naive way of looking at it; more accurate is that each party in the chain adds value. Even if that value is simply making the item available near the next customer, it's still value added, and hence wealth created.
I feel like conservation of energy and the laws of thermodynamics just don't apply.
http://en.wikipedia.org/wiki/Conservation_of_energy
http://en.wikipedia.org/wiki/Laws_of_thermodynamics
"Cool chair."
Both parties benefit from the utility of the exchange, but that doesn't create more wealth. This exchange model assumes 'lossless' liquidity.
Ergo, the (resource) limits to growth.
http://www.continuum.io/blog/conda_packaging addresses a few of your points (including wheel)
Travis-CI and Tox support would be cool. Obviously it's possible to just shell out to conda and check return codes.
With pip 2.0 and latest conda, packaging latency (is this the latest package?) is not as much of a concern.
In terms of upvote/downvote, banned subreddits, etc., we are talking generally about auto-deletion and post-prevention I imagine? What rules would you like to see in place to make sure the bot doesn't get spammy? This is one of the main areas for which I am seeking feedback.
It sounds like the heuristics for identifying a StackOverflow URL are fairly definitive.
That's not a hexadecimal code.
/r/autowikibot has a few features for things like upvote/downvote, banned subreddits, etc.
A few (additional?) features that may be useful:
shorturl/shortlink support
"deep-linking" to specific answers
Software using Semantic Versioning MUST declare a public API. This API could be declared in the code itself or exist strictly in documentation. However it is done, it should be precise and comprehensive.
The "should" should be in ALL CAPS, and the MUST is questionable given the relative vagueness of this line.
That does seem out of scope.
Once a versioned package has been released, the contents of that version MUST NOT be modified. Any modifications MUST be released as a new version.
While modifying an old version is generally a Very Bad Idea, it is overly prescriptive for a version number standard to absolutely forbid it. This also implicates list items 6-8.
Bad/failed/scratched builds should be incrementally later. Why assign the same version string to two separate things? "Let's just reuse this UUID and hope it's not cached anywhere?"
It would be great / helpful to add the tools listed here which support semver.org to an #implementations section (such as https://github.com/mojombo/semver.org/issues/57)
Which instances of MUST are you suggesting could be changed to SHOULD while preserving the nature of the spec? IMHO SHOULD would suggest that semver.org version comparison implementations would be expected to handle edge cases which are not in spec.
Backus-Naur could also be helpful.
Something about natural keys and the consistency part of CAP theorem may also be helpful.
http://en.wikipedia.org/wiki/CAP_theorem
http://en.wikipedia.org/wiki/Natural_key
Working with appengine data store makes this readily apparent (and somewhat of an open problem)
https://developers.google.com/appengine/docs/python/ndb/entities#numeric_keys
With one (SQL) database instance, natural keys and/or a multi-column UNIQUE index, it's still necessary to catch and handle the database exception.
http://docs.couchdb.org/en/latest/replication/conflicts.html
... http://en.wikipedia.org/wiki/Paxos_(computer_science)#Production_use_of_Paxos
The Art of UNIX Programming by Eric S. Raymond http://www.catb.org/esr/writings/taoup/html/
http://dataset.readthedocs.org/en/latest/ is a really easy way to work with SQLAlchemy (which is Open Source and supports SQLite, which is also Public Domain Open Source), JSON, and CSV.
Some are open, e.g. netCDF or mzXML, and some are proprietary to a specific instrument vendor, i.e. the specs for the format are not publically available so you can't open them without that vendor's software (which is part of what I'm working out). Even though quite a few people probably use the open netCDF format, none of their data is publically available (and thus "open").
https://en.wikipedia.org/wiki/Open_standard#Specific_definitions_of_an_open_standard
For example, I'm writing software to analyze chromatograms
open data
Those are servers which serve WSGI applications over HTTP. Tornado is also a framework.
http://www.reddit.com/r/Python/comments/1eboql/python_website_tuts_that_dont_use_django/#c9yxl8w
http://en.wikipedia.org/wiki/Web_Server_Gateway_Interface
https://github.com/seedifferently/the-great-web-framework-shootout
Questions for a cost-benefit analysis:
What are you most productive in?
Do you need to train a team?
What sort of learning curve is there? Documentation?
How does the framework encourage development of secure, scalable systems?
How well does the framework supported automated testing, in terms of support for transactional datastore operations, initial data fixtures, and JavaScript?
Why WSGI?
The WSGI interface makes it easier to test and plug together frameworks and middleware components (utilities).
It is possible to minimize switching cost and technical debt by developing components coupled through a WSGI interface; components are theoretically interchangeable.
http://www.reddit.com/r/Python/comments/1drv59/getting_started_with_automated_testing/c9tfxgd
http://rpy.sourceforge.net/rpy2/doc-2.3/html/index.html
The high-level interface in rpy2 is designed to facilitate the use of R by Python programmers. R objects are exposed as instances of Python-implemented classes, with R functions as bound methods to those objects in a number of cases.
http://ipython.org/ipython-doc/dev/config/extensions/rmagic.html
That's hard to believe.
http://en.wikipedia.org/wiki/Computational_neuroscience
https://wiki.python.org/moin/PythonForArtificialIntelligence
http://www.scipy.org/topical-software.html#artificial-intelligence-machine-learning
http://www.pymvpa.org/modref.html
http://martinos.org/mne/stable/python_reference.html
https://github.com/mne-tools/mne-python
https://github.com/neuropy/neuropy
http://nilearn.github.io/index.html
http://nipy.org/nipy/stable/documentation.html#documentation-main
Thanks!
Also helpful:
"Ten Simple Rules for Reproducible Computational Research (PLOS)"
http://www.ploscompbiol.org/article/info%3Adoi%2F10.1371%2Fjournal.pcbi.1003285
Works great as a visual feedback loop. Much easier than editing multi line code than in a REPL loop.
As far as automated testing for a whole notebook of cells, there's https://github.com/taavi/ipython_nose
https://github.com/ipython/ipython/wiki/A-gallery-of-interesting-IPython-Notebooks
You can use html5lib parse and BeautifulSoup parser within lxml. See lxml.de/elementsoup.html & lxml.de/html5parser.html
Nice! I overload man to launch ftplugin/man.vim, which adds syntax highlighting:
$ type man
man is a function
man ()
{
alias man_="/usr/bin/man";
if [ $# -eq 0 ]; then
/usr/bin/man;
else
vim --noplugin -c "runtime ftplugin/man.vim" -c "Man $*" -c 'silent! only' -c 'nmap q :q<CR>' -c 'set nomodifiable' -c 'set colorcolumn=0';
fi
}
Thanks!
$ man readline | grep 'VI Mode' -A 100 #~
http://en.wikipedia.org/wiki/Comparison_of_open-source_configuration_management_software
Scons is great. You might take a look at Baker, docopt, and clint on pypi.
http://paver.github.io/paver/pavement.html tasks work similarly.
"python cli docstrings pypi decorator"
Street lamps and parking meters with WiFi APs; and gigabit Redstone mesh wireless routers. TIL about competition and Neilsen’s Law of Internet Bandwidth.
That may be one metric for measuring CS proficiency. Comparatively, I don't know how we should measure the ROI of investing in [math/STEM] education.
http://en.wikipedia.org/wiki/Outline_of_software_engineering#Processes_and_methodologies
http://en.wikipedia.org/wiki/Outline_of_software_engineering#Life_cycle_phases
http://en.wikipedia.org/wiki/Software_development_methodology#Approaches
http://en.wikipedia.org/wiki/Lean_Startup#Minimum_viable_product
http://en.wikipedia.org/wiki/User_story#User_stories_and_use_cases
So, what sort of projections do you think would be appropriate for a null hypothesis?
Do you have anything more than subjective discouragement to contribute here? Maybe some objective data?
But...The whole point of all this is to have classes in high school isn't it?
The point is to help people with an aptitude for CS to learn CS.
The problem with the status quo is that (some people/states, through curriculum policies) still consider CS as irrelevant to [all of the fields which trigonometry is antecedent to].
What are you purposing exactly, just give some kids some books and online courses with no teacher, or am I misreading your desires?
That sounds more ideal than "I will pay you to pursue continuing education."
Learning to code is important [...]
I agree. Learning to speak "code" affords very many career opportunities. It's hard to automate.
You want to teach one specialized skill over others, there are not enough resources or time in the day to do them all.
Do I want to play the zero-sum allocation game? Where are we wasting time and resources? All careers are important. CS is vital to our energy, transportation, and utility systems.
I think you overvalue the need for everyone to need to know CS/code, I don't feel you've presented me with any logical reason as to why it's needed for people not working in the field.
I think you underestimate our level of technology dependence.
Can you present me with a reason why person outside of CS/SE/IT needs to know this stuff, any more than any other specialized field (ie. mechanic, plumber, architect, etc)?
Should CS be mandatory? Not necessarily.
Should CS be recognized as STEM credit for highschool graduation? Absolutely.
I disagree that CS is a subset of STEM. CS significantly intersects with STEM. That intersection forms a subset which is a subset of both CS and STEM.
The "Mathematics for Computer Science" textbook I referenced above has a fairly comprehensive chapter on sets with a subchapter on subsets.
I think I agree with you, except it's more of an intersection with sufficient overlap as to consider CS to be "part of STEM" as a whole.
My mistake. Were you saying that the intersection between CS and STEM fields forms a subset containing members of both CS and STEM fields?
A shortage of CS people who would value teaching over money combined with the number of high schools across the country that would have to have slots filled (with adept people),
So, a shortage of CS teachers and of funding? Fortunately, it is entirely possible to learn CS without classroom-based instruction.
all for a specialized set of skills not everyone needs and does not need to complete their daily tasks/jobs.
What percentage of the current common core curriculum does everyone need to complete their daily tasks?
The math of this doesn't work out for me.
What math are you referring to?
You keep linking opinion pieces that match your views as facts/sources in your responses.
Which of these links do you view as opinion pieces?
I'm trying to make a case based more towards the reality (as I see it of course) of what the majority of people want/need as far as education goes. Your argument is based on a need that I don't believe exists, we don't all need to know CS like we all don't need to know how a car is put together to drive it.
A majority of people don't see e.g. trigonometry as what they want/need. Nonetheless, these are the current standards for K-12 education in the United States: http://www.corestandards.org/the-standards
These are the ACM standards for college-level CS education: http://www.acm.org//education/curricula/ComputerScience2008.pdf
As we move toward a knowledge-based economy (there are lots of new jobs in the tech sector), learning to code is becoming increasingly important. Why would I ever need to know how to change a tire? Why would anyone ever need to know how the AI and robotics on the line work? Why would anyone ever need to understand how to maintain legacy systems upon which we are all reliant?
Point #10 from the Computing in the Core Facts and Resources page linked above contains links to resources for (1) a federal Computer Science Education Act and (2) getting involved by "strengthening computer science education at the state and local levels".
I searched for "BLS tech sector" and found a number of projections in regards to growth and new jobs that require, at a minimum, an understanding of core CS concepts. From home, school, or a library, anyone can learn to code (in one hour).
"Mathematics for Computer Science" [PDF] Chapter 4.1.2: Mathematical Data Types: Comparing and Combining Sets (Free Creative-Commons #OER)
I don't get your argument, it's like you expect more teachers to exist in this field than do.
My argument, I suppose, is that treating CS education as a "play on the computer course" is not and never was appropriate. CS is a vital part of a future curriculum.
Well, is there a shortage of teachers or a shortage of funding?
This (Creative Commons) #OER is free: http://www.greenteapress.com/thinkapjava/
It's like you expect college caliber courses to be mandatory in schools across America, even if the demand isn't enough to support such a thing.
https://www.class-central.com/subject/cs lists hundreds of free college level courses with zero prerequisites. There are highschools which accept transfer credit for college-level courses which then count as credit hours; but I'm not aware of any compulsory highschool-level programs which specifically reward college-level independent CS study as what it is: STEM learning.
I have no specific data on what sectors of our economy will be in need of CS majors. The BLS link above lists (all positive) growth rates for various CS-related careers.
I think you have some glasses with special lenses that are clouding your judgement.
Rose-colored lenses would be great. Eyestrain is real. Ever heard of the 20-20-20 rule?
It's high school, you get the basics of everything. What is a comparable field to what you're asking for in high school, you have basic math, sciences, language, etc. not how to become an architect, engineer, or surgeon. It makes perfectly logical sense to get basic computing classes in HS as it's what suits the majority.
So, in practice, typing and office apps are required and "writing code" is an elective.
For advanced math, graphing calculators are strongly recommended. Graphing calculators don't translate to "a boardroom" or an academic review system like Open Access which demands procedural, algorithmic reproducibility. Enter "code".
http://www.computinginthecore.org/facts-resources and http://code.org/about make great cases for CS as a vital part of a future curriculum.
And it seems like you have a gross misunderstanding of what computer science is. I think you mean software engineering.
https://en.wikipedia.org/wiki/Computer_science#Applied_computer_science
I fail to see how differentiation is appropriate here. Is there a need to make such a distinction? In my opinion, such an artificial boundary between theory and application is harmful and counter-productive to translating between research into development. While specialization and distinction are both very important, my personal interests are in systemic holism, theory, and dynamics as they apply to cybernetics.
Regardless, CS is a part of STEM. The linked article is specifically about CS. The linked report is indeed about a broader category of STEM majors (which includes CS majors); and would be helpful for any development of strategy for CS curriculum.
I'm not going to do your research for you. Present the facts to me in an argument instead of handing me your reference.
I wasn't aware that I was obligated to perform any sort of research for you.
The aforementioned report lists five recommendations for achieving a goal of producing one million additional STEM graduates. I don't find it appropriate to paraphrase the five recommendations listed in the report in this thread.
And what is the point in regards to my original argument?
As I understand your original argument, you were suggesting that CS is not part of 'STEM'.
CS is part of STEM category.
A Million CS students will not fill in the electrical engineering gap, nor any of the other countless STEM positions.
I have not suggested that that would be the case. CS majors may well develop AI which subsumes large portions of electrical and nano-molecular engineering, which no-one would later understand.
These reports were for all STEM jobs, not just CS.
Once again, CS is a part of STEM. CS graduates are indeed a vital part of developing a STEM workforce to support national infrastructure.
CS is but one small subset of STEM and a majority of the work most CS students go on to it not STEM related at all.
Topicality? I feel that CS is core to and in the category of STEM fields. CS is certainly part of a whole.
Data Science is core to assessing progress in any industry. As a foundational component of Data Science, knowledge of at least intro CS is very helpful.
The fixes presented in those studies are STEM wide and not localized to CS.
Lots of great insight in the five recommendations presented in these reports from the Office of Science and Technology Policy Presidents Council of Advisors on Science and Technology Policy (OSTP PCAST).
http://www.whitehouse.gov/administration/eop/ostp/pcast/docsreports
Doing just CS will probably do nothing and most likely won't help at all to fill in the engineering and science gaps we have.
Engineering and Science depend on tools created by Computer Scientists, Computer Engineers, Software Developers, and Data Scientists to afford critical gains in productivity, efficiency, and accuracy.
You could add that to the Wikipedia page.
the Wikipedia article about education is an ironclad argument!
Read it and get back to me.
Methinks OP shoulda paid more attention in literature class. The critical thinking skills might’ve helped.
What critical thinking argument are you referring to?
/u/arghnoname indicated a personal need and/or an inability to cope with the stress of teaching. /u/kjearns identified supporting resources for market payscales as an argumentative refutation. /u/ALeapAtTheWheel alleged use of current vocabulary and current events as a straw man for how I think it would be "great".
Critically, which part of literature class should I have paid attention to?
My brother took QBasic in elementary school. I got to review his discarded floppy disks. I took VB6 and Java (AP CompSci, it was called) through highschool. I was significantly sleep-deprived, because I was teaching myself LAMP in the evenings when I could have been doing homework for other courses which I considered far less interesting at the time. CS was considered an elective; like something that's not foundational to our national infrastructure. That seems highly illogical and irrational.
The ancillary point being made about salary as a primary motivator for choosing a career seemed somewhat antithetical to my, admittedly vague, suggestion of need for state education level support for CS education [for legacy infrastructure].
By sharing a headline that I felt validated my experience with nerdery in HS, forever ago, I suppose the (implicit) point I was making was that it would behoove us to recognize CS studies as STEM credits for graduation.
I think your first link confirms what you're trying to refute.
I don't think that was the point I was making.
Why would someone want to teach CS in highschool and (1) make substantially less money than other available options and (2) deal with the huge amount of BS that is being a teacher.
Thank you for bringing this to my attention. It may be best for you to ask a teacher what sort of gratification and reward they get from their position.
Any high school teacher qualified enough to teach computer science can make a good deal more money by practicing it.
http://www.bls.gov/ooh/computer-and-information-technology/computer-programmers.htm#tab-7
I took a "computer science" class in high school, which mostly consisted of the kids messing about with computers while the teacher was more or less helpless to do anything.
That's one way to spend our time and money. A more self-directed curriculum with gamification-style reward points may be more likely to encourage students to understand what sort of opportunities are ahead of them.
I don't think high school is the place to teach CS anymore than it is the place to teach civil engineering.
I strongly disagree.
How can teachers develop CS curriculum?
By incentivizing study of Computer Science with credit for graduation, we may be more likely to meet demand for "One Million Additional College Graduates with Degrees in Science, Technology, Engineering, and Mathematics"
What nonpartisan callous disregard for others' suffering.
I don't have http://en.wikipedia.org/wiki/Alexithymia .
Changelog-compatible ticket/issue prefixes are explained here: https://github.com/pydata/pandas/blob/master/CONTRIBUTING.md
I don't know anything about the controls of this survey?
Maybe women not to identify in open source communities so their contributions can be accepted or rejected on a basis of merit?
There are lots of great women-in-IT organizations which do (explicitly and implicitly) exclude men; for some reason.
http://pyladies-kit.readthedocs.org/en/latest/
Maybe they're all reading Karen Horney and knitting warm blankets and stuff?
http://en.wikipedia.org/wiki/Karen_Horney
( http://en.wikipedia.org/wiki/Coping_(psychology) )
Maybe they're not aware of how pervasive open source software is in our modern economy for today's world to share.
http://en.wikipedia.org/wiki/Business_models_for_open-source_software
Cool analysis. Thanks!
If you still have the data on hand, do you have any data for how many [of the current latest versions of] packages specify an off-pypi Download URL?
Ohcount and radon are also great for static analysis metrics.
Thanks! status.python.org by statuspage.io
Specify a pypi-aware caching proxy url as an index url (with -i for the CLI and/or with the index-url option in the pip configuration file)
These pretty much cover it:
~/.pydistutils.cfg)Manually: http://docs.repoze.org/compoze/
This is OT (sorry). I believe we're concerned about different issues.
Deprecated and new features are two separate things. Timedelta64 is a new feature in numpy 1.7. The Ubuntu LTS python-numpy package is version 1.6.1. Avoiding deprecated features does not add new features (e.g. timedelta64) to outdated OS packages (e.g. LTS python-numpy).
because then they would need to [frequently] merge in from upstream in order to avoid divergence and risk.
There are incompatible changes between 1.6 and 1.7. There are probably additional new features in 1.8, hence the new version.
datetime64 and timedelta64 were also added in 1.7 *
Something about
True = False; assert bool(True)
assert(1); assert(None)
might also be helpful.
Being required to use system numpy is requiring a freezed version that may or may not be up to date. For example, numpy latest is 1.8.0 whereas Ubuntu LTS still has numpy 1.6.1. *
my approach: depend on the newest version of something, and write a dependency of
package >= that.version. when adding features later, or an issue arises with a newer version, bump the depended-on version to ≥the newest again, then fix the issues.
+1 for this and automated test coverage.
you do not want multiple numpy installations on your PC.
Conda solves for this.
All of these links answer the question.
Outlines approaches for publishing RDF data (about available semantic webservices).
Matching not-necessarily-correlated functions between various services is an exercise in Ontology Alignment. (seeAlso: semantic integration, semantic matching)
Matching and adapting service interfaces can be accomplished in Python with zope.interface.
Any sort of (fuzzy) ontology alignment is an exercise in mathematical optimization and as such must utilize some sort of cost function (or loss function, as pointed to by wiki/Cost_function).
Which of these links do you consider unrelated to the (sounds like an exam) question presented by 41k3n?
Comparatively, how does gunicorn perform with the same script?
http://www.w3.org/TR/ld-glossary/#x5-star-linked-open-data:
- ☆ Publish data on the Web in any format (e.g., PDF, JPEG) accompanied by an explicit Open License (expression of rights).
- ☆☆ Publish structured data on the Web in a machine-readable format (e.g., XML).
- ☆☆☆ Publish structured data on the Web in a documented, non-proprietary data format (e.g., CSV, KML).
- ☆☆☆☆ Publish structured data on the Web as RDF (eg Turtle, RDFa, JSON-LD, SPARQL)
- ☆☆☆☆☆ In your RDF, have the identifiers be links (URLs) to useful data sources.
and than they can manipulate it to their hearts content.
http://andreacensi.github.io/contracts/
PyContracts is a Python package that allows to declare constraints on function parameters and return values. It supports a basic type system, variables binding, arithmetic constraints, and has several specialized contracts (notably for Numpy arrays).
With ipython [1] and matplotlib installed:
ipython notebook --pylab=inline
# open browser to http://127.0.0.1:8888
Then::
def a_linear_func(c):
return 2*x +1
x_values = range(0,10)
y_values = [a_linear_func(x) for x in x_values]
print(x_values, y_values)
print(zip(x_values, y_values))
import matplotlib.pyplot as plt
plt.plot(x_values, y_values)
More information:
[1] http://ipython.org/ipython-doc/stable/install/install.html#mathjax
Teams
Software Development
Communication: Documentation
Open Source Teams
[1] Revision Control (CVS, SVN) and Distributed Revision Control (Git, Hg, Bzr)
[2] Automated Testing
[3] The Art of Unix Programming: Best Practices for Working with Open-Source Developers
Thank you for your consideration.
I consider documentation to be more generally useful than (also enlightening) offhand blog posts and one-off snippets which, while they do contribute to a general knowledge base, serve more to serve the interests of individuals than to further the interests of science.
Documentation is immensely important to the success of any open source project; perhaps even moreso to the credibility of any scientific argument intended to be reproducible.
To be having a notability/relevancy discussion over whether something is BibTeX-able seems trite (especially when we're discussing nonexistant policy). Nonetheless, I am a guest here. I suppose the most noteworthy content will bubble up.
To the heart of the matter, I feel that this documentation is eminently notable and relevant to any discussion regarding statistics and Python. [It]:
minepy
Source: https://github.com/minepy/minepy
Docs: http://minepy.sourceforge.net/docs/1.0.0/python.html
Citation: D. Reshef, Y. Reshef, H. Finucane, S. Grossman, G. McVean, P. Turnbaugh, E. Lander, M. Mitzenmacher, P. Sabeti. Detecting novel associations in large datasets. Science 334, 6062 (2011)
I am at a loss as to what it is that you are looking for here. In terms of relevancy:
[...] a place to discuss the use of python in statistical analysis and machine learning.
The linked pages document standard, optimized routines for Statistics in Python.
I'm sure it wouldn't be too difficult to reformat sphinx documentation pages as two-column PDFs with an abstract, but then how would we read them on our phones, with our screen-readers, in order to verify the reproducibility of conclusions we derive from biased, non-null-hypotheses? #PDF
Are you looking more for non-executable books, or /r/IPython notebooks?
[EDIT] Is the purpose of this subreddit to share resources educating subscribers on available best-practices for performing statistical analyses in python?
We could not wait for the packaging solution we needed to evolve from the lengthy discussions that are on-going which also have to untangle the history of distutils, setuptools, easy_install, and distribute. What we could do is solve our problem and then look for interoperability and influence opportunities once we had something that worked for our needs.
conda and http://binstar.org rock.
fixing pip
... http://www.reddit.com/r/sysadmin/comments/1s4ec4/please_stop_piping_curl1_to_sh1/cdu41kh?context=3
Yup, liking URLObject a lot.
Doesn't print flush?
Edit: it does not do sys.stdout.flush … seeAlso python -u / PYTHONUNBUFFERED (http://stackoverflow.com/questions/230751/how-to-flush-output-of-python-print/230780#230780)
Curl pipes:
Really, it is that simple.
TIL about curl -fsSL (explainshell.com)
http://scikit-learn.org/stable/about.html#citing-scikit-learn
Scikit-learn: Machine Learning in Python, Pedregosa et al., JMLR 12, pp. 2825-2830, 2011.
Bibtex entry:
@article{scikit-learn, title={Scikit-learn: Machine Learning in {P}ython}, author={Pedregosa, F. and Varoquaux, G. and Gramfort, A. and Michel, V. and Thirion, B. and Grisel, O. and Blondel, M. and Prettenhofer, P. and Weiss, R. and Dubourg, V. and Vanderplas, J. and Passos, A. and Cournapeau, D. and Brucher, M. and Perrot, M. and Duchesnay, E.}, journal={Journal of Machine Learning Research}, volume={12}, pages={2825--2830}, year={2011} }
Source: https://github.com/scikit-learn/scikit-learn
Documentation: http://scikit-learn.org/stable/documentation.html
If you are doing transformations/manipulations/producing intermediate results from scientific data, you should be maintaining a repeatable history of each and every step. This is called 'Data Provenance', and it is necessary for producing 'Reproducible' research.
Pandas makes it very easy to store the entire script of transformations.
From http://www.reddit.com/r/pystats/comments/1s1qbs/ten_simple_rules_for_reproducible_computational/ :
- Rule 1: For Every Result, Keep Track of How It Was Produced
- Rule 2: Avoid Manual Data Manipulation Steps
- Rule 3: Archive the Exact Versions of All External Programs Used
- Rule 4: Version Control All Custom Scripts
- Rule 5: Record All Intermediate Results, When Possible in Standardized Formats
- Rule 6: For Analyses That Include Randomness, Note Underlying Random Seeds
- Rule 7: Always Store Raw Data behind Plots
- Rule 8: Generate Hierarchical Analysis Output, Allowing Layers of Increasing Detail to Be Inspected
- Rule 9: Connect Textual Statements to Underlying Results
- Rule 10: Provide Public Access to Scripts, Runs, and Results
- Rule 1: For Every Result, Keep Track of How It Was Produced
- Rule 2: Avoid Manual Data Manipulation Steps
- Rule 3: Archive the Exact Versions of All External Programs Used
- Rule 4: Version Control All Custom Scripts
- Rule 5: Record All Intermediate Results, When Possible in Standardized Formats
- Rule 6: For Analyses That Include Randomness, Note Underlying Random Seeds
- Rule 7: Always Store Raw Data behind Plots
- Rule 8: Generate Hierarchical Analysis Output, Allowing Layers of Increasing Detail to Be Inspected
- Rule 9: Connect Textual Statements to Underlying Results
- Rule 10: Provide Public Access to Scripts, Runs, and Results
Sandve GK, Nekrutenko A, Taylor J, Hovig E (2013) Ten Simple Rules for Reproducible Computational Research. PLoS Comput Biol 9(10): e1003285. doi:10.1371/journal.pcbi.1003285
Great book! Thanks!
My Opinion
Don't get me wrong
You got yourself wrong.
Why does this feel less like a design critique and more like bitching about an alternate approach in a thinly veiled attempt to promote your favorite framework?
https://en.wikipedia.org/wiki/Anti-pattern#Software_engineering
Is this not the saddest last ditch marketing strategy you've ever seen?
Don't hate. FUD is for people who can't code.
AngularJS
view logic
This is called separation of concerns.
automagically
When the page loads, the JS is executed. Line-by-line. In order to separate concerns, the JS parses the extra DOM attributes.
data binding
https://en.wikipedia.org/wiki/UI_data_binding#JavaScript
debug
Programming by debugger is a bad approach to programming. If a test case doesn't do what would be done manually with a debugger; the test case is incomplete.
https://en.wikipedia.org/wiki/Test-driven_development
Backbone
Backbone [with Marionette] is very cool, too.
JS Framework Review
This is exactly the sort of manipulative, underhanded approach to logical argumentation that would indicate a dishonestly-irrational-to-the-point-of-unsafe approach to software development.
Here's a constructive approach that evaluates the technical merit of various market solutions: http://todomvc.com/
http://pandas.pydata.org/pandas-docs/stable/timeseries.html#converting-to-timestamps (to_datetime) works with many date storage formats.
http://pandas.pydata.org/pandas-docs/stable/merging.html should get you started with merging, joining, and concatenating disparate pandas DataFrames.
With reddit Markdown, you can indent code with four spaces for a monospace font.
To clarify your question, it sounds like you are working on how to write queries (logic views) which serialize data stored in SQL (data models) to JSON (data models) to D3.js scripts (presentation templates with JS logic).
Tastypie or Django REST Framework are probably your best bets if you need to work with Django and authentication/authorization. Both support serializing Model objects as JSON.
Pandas supports a number of data formats, including SQL and JSON:
A view with pandas and JSON might look something like:
# view
from pandas.io import sql
from django.db import connection
table_name = Model._meta.db_table
df = sql.read_frame('select * from <table_name>, connection) # careful with SQL injection
# transform/aggregate(df)
json = df.to_json()
return json
# template
function() { d3(...) };
A view with pandas, Vincent, and Vega JSON might look something like
# view
from pandas.io import sql
from django.db import connection
from vincent import Visualization, Data, Scale, Axis
table_name = Model._meta.db_table
df = sql.read_frame('select * from <table_name>, connection) # careful with SQL injection
# transform/aggregate(df)
data = Data.from_pandas(df)
vis = Visualization()
vis.scales[] = Scale() ; vis.axes[] = Axis()
vis.data['table'] = data
vega_json = vis.to_json()
return vega_json
# template
https://github.com/wrobstory/vincent/blob/master/vincent/vega_template.html
It may be more efficient to do aggregations (rollups, pivots) as Django/SQL aggregations or as operations involving multiple pandas DataFrames and simple SELECT statements ... Pandas works with (multidimensional) tabular data. If you have to do JOINs with Django (as opposed to pandas), DataFrame.from_records and DataFrame.from_items are probably what you're looking for.
- Rule 1: For Every Result, Keep Track of How It Was Produced
- Rule 2: Avoid Manual Data Manipulation Steps
- Rule 3: Archive the Exact Versions of All External Programs Used
- Rule 4: Version Control All Custom Scripts
- Rule 5: Record All Intermediate Results, When Possible in Standardized Formats
- Rule 6: For Analyses That Include Randomness, Note Underlying Random Seeds
- Rule 7: Always Store Raw Data behind Plots
- Rule 8: Generate Hierarchical Analysis Output, Allowing Layers of Increasing Detail to Be Inspected
- Rule 9: Connect Textual Statements to Underlying Results
- Rule 10: Provide Public Access to Scripts, Runs, and Results
Sandve GK, Nekrutenko A, Taylor J, Hovig E (2013) Ten Simple Rules for Reproducible Computational Research. PLoS Comput Biol 9(10): e1003285. doi:10.1371/journal.pcbi.1003285
"There's an art to it."
Looking forward to this functionality!
Other useful ways to create interactive data science / data analysis widgets with IPython:
Unfortunately, PowerPoint does not yet support HTML5; so the easiest way to share matplotlib charts in a PowerPoint would be as SVG (an open standard).
If they're just looking for prettier charts, you might look into:
If they can work with IPython notebooks (and/or they want to know how reproducible an analysis is):
ipython convert --to slides <notebook.ipynb>There are a number of Cloud Services listed with the /r/IPython sidebar.
So, we should provide energy to other countries; therefore everyone could understand how it works.
I feel like there is confusion between financial stake and net good.
https://en.wikipedia.org/wiki/JPEG
https://en.wikipedia.org/wiki/Generation_loss
Interesting problem.
Here's this, with tests: https://gist.github.com/westurner/7671620
I only tested response_curve with one fairly small JPEG image which 'ended' at (96, 101).
Incorrect. You can transfer information using quantum entanglement.
https://en.wikipedia.org/wiki/Quantum_entanglement#Applications
https://en.wikipedia.org/wiki/Quantum_teleportation#Non-technical_summary
http://www.forbes.com/sites/alexknapp/2012/09/06/physicists-quantum-teleport-photons-over-88-miles/ (Nature)
bits and qubits are both gbits (Quantum Physics)
Background
Tools
CSV/SQL
Workflow
reddits
Post frequency may also be useful.
While there are differences in scope (.schema, .query, .fragment) from pathlib.Path, a comparable API for URLs and URIs might be helpful (.parts, [...]).
http://www.reddit.com/r/Python/comments/1r7h1t/python_objects_for_working_with_urls_and_uris/
The .glob and .match syntax for matching paths from PEP 428 seems similar in function to e.g. stdlib fnmatch and various web frameworks' route matching features:
PEP 428: The pathlib module -- object-oriented filesystem paths
Python stdlib fnmatch and glob
Web Framework Route Matching
"Don't change it, it might break"
"Well, we've had hundreds of people using 20% of features, correctly, for years."
Yes, it is a good idea to write tests for legacy (production) code.
If you have no automated [functional, unit, integration] tests and are relying upon wasteful, error-prone manual testing, you probably:
That it's legacy code has no bearing on whether there are bugs, defects, and unchecked boundary conditions.
Zero Automated Tests -> Zero Code Coverage
https://en.wikipedia.org/wiki/Uncertainty#Concepts
https://en.wikipedia.org/wiki/Risk#Risk_versus_uncertainty
https://en.wikipedia.org/wiki/Software_testing#Security_testing
http://www.reddit.com/r/Python/comments/1drv59/getting_started_with_automated_testing/
“Global Variable Considered Harmful” (1973) https://en.wikipedia.org/wiki/Global_variable#cite_note-1
https://en.wikipedia.org/wiki/Information_hiding#Encapsulation
https://en.wikipedia.org/wiki/Encapsulation_(object-oriented_programming)
https://en.wikipedia.org/wiki/Protocol_(object-oriented_programming)
Yeah, I think that's better done with Python code, with idempotent functions (and/or a lock).
https://en.wikipedia.org/wiki/Comparison_of_open-source_configuration_management_software
binary applications / binary packages
Cool outdated opaque binary which I can double-click on.
configuration
Why reinvent the wheel to store static configuration files?
Generate templated configuration on invocation (str.format, string.Template, jinja2) (because someone will accidentally delete it)
YAML
dependency bundling
esky
esky: keep frozen apps fresh
Esky is an auto-update framework for frozen Python applications. It provides a simple API through which apps can find, fetch and install updates, and a bootstrapping mechanism that keeps the app safe in the face of failed or partial updates.
pip wheel
Build Wheel archives for your requirements and dependencies.
https://github.com/wolever/pip2pi
pip2pi builds a PyPI-compatible package repository from pip requirements
https://pypi.python.org/pypi/compoze
This package provides a script for creating setuptools-compatible package indexes using packages downloaded from other indexes.
pytest is more functional than unittest; both of which utilize classes.
While possible to write tests without subclasses of object with __init__ methods or unittest.TestCase.setUp, I find it easier to reuse code. I guess you could namespace things into one non-class per file.
http://www.reddit.com/r/Python/comments/1nzsze/functional_programming_in_python/#ccnuwno
http://www.reddit.com/r/Python/comments/1drv59/getting_started_with_automated_testing/#c9tfxgd
I love Python as a language but, it has some serious issues with distributing actual applications to various (Windows-only) systems.
I feel like you are confusing your understanding of the breadth of options for distributing applications with the capabilities of the core and non-core Python tools for doing so.
As the OS updater for the platform you have specified is not extensible to other applications, it is necessary to manage application updates/upgrades/patches/hotfixes in addition to operating system package updates.
Python 3 compatible methods for distribution:
http://docs.python.org/3/library/msilib.html (bdist_msi)
https://pypi.python.org/pypi/bdist_nsi (bdist_nsi)
https://pypi.python.org/pypi/esky (bdist_esky)
https://pypi.python.org/pypi/wheel (bdist_wheel)
Also relevant, and helpful:
https://en.wikipedia.org/wiki/Open_science
https://en.wikipedia.org/wiki/Open_access
https://en.wikipedia.org/wiki/Open_source
https://en.wikipedia.org/wiki/Open_data
https://en.wikipedia.org/wiki/Reproducibility
https://en.wikipedia.org/wiki/Scientific_workflow_system
You'll need a deeper understanding of CS concepts, some of which you can get through How to Think Like a Computer Scientist.
Write some small but useful Python projects and start learning another language.
https://brilliant.org/competitions/hunger-games/
Hunger Games
A game theory programming tournament
Write an algorithm to fight to the death against other algorithms. Cooperate and compete with other players at different points in the game to survive and win.
The new libevent2 is the best cross-platform IO library because it abstracts this.
What worked against me was that I already had the big picture in mind: pairing this async I/O stuff with the parallel/GIL stuff such that callbacks could actually be invoked on multiple threads simultaneously.
So, this: is shared nothing, works on Windows, doesn't support STM, and toggles the write-protect bit on large heaps and pages?
Nice summary; I'm kinda' relieved to see when others defend IOCP -- it feels like a very lonely existence to try and argue what's seen as the best of breed way of doing something on UNIX.
Thanks for the MegaPipe reference.
[EDIT] A compare/contrast with Tulip + libevent2 might be helpful?
from __future__ import print_function
for row in allrows:
#print the date for each listing
span = row.find('span', {'class':'date'})
datestr = span.text.strip()
link = span.findNextSibling('a')
link_anchor_text = link.text
link_href = link['href']
print(datestr, link_anchor_text, link_href)
https://en.wikipedia.org/wiki/Web_scraping
https://en.wikipedia.org/wiki/Robots.txt_protocol
https://en.wikipedia.org/wiki/Comparison_of_HTML_parsers
https://en.wikipedia.org/wiki/Selenium_%28software%29
http://doc.scrapy.org/ (Twisted + lxml)
http://docs.python-guide.org/en/latest/scenarios/scrape/ (requests + lxml)
What about https://en.wikipedia.org/wiki/File_system_permissions ?
https://en.wikipedia.org/wiki/Privilege_separation
https://en.wikipedia.org/wiki/Principle_of_least_privilege
https://en.wikipedia.org/wiki/Operating_system-level_virtualization
Linux:
https://en.wikipedia.org/wiki/Comparison_of_open-source_configuration_management_software
Moore/Sloan Data Science Initiative
A 5 year, $37.8M initiative for creating new Data Science Environments at UW, NYU and Berkeley. Funded by the Moore and Sloan Foundations.
https://pypi.python.org/pypi/pyramid_appengine (virtualenv + buildout)
Thanks! Is there a way to download this - for example as a PDF or an ePub - without e.g. wget --mirror? 1 2
Also wonderful: "The Psychology of Cyberspace" http://users.rider.edu/~suler/psycyber/psycyber.html
"An Evaluation of the Left-Brain vs. Right-Brain Hypothesis with Resting State Functional Connectivity Magnetic Resonance Imaging" http://www.plosone.org/article/info%253Adoi%252F10.1371%252Fjournal.pone.0071275
The Now is eating ever greater quantities of our attention.
I feel better about myself now.
In the Stream, the focus is on messages not web pages
http://pyes.readthedocs.org/en/latest/guide/reference/river/index.html
Information should be pushed, not pulled
This web doesn’t look like a database or a graph. It’s a web that’s intelligent, dynamic and sometimes chaotic. It’s the digital equivalent of the human brain.
Point to a repository you think should be the gold standard for modern python projects.
structure
http://pyramid.readthedocs.org/en/latest/narr/project.html#the-project-structure
naming scheme
http://docs.pylonsproject.org/en/latest/docs/pyramid.html#supported-add-ons
unit tests
https://github.com/Pylons/pyramid/tree/master/pyramid/tests
https://github.com/Pylons/pyramid/blob/master/tox.ini
documentation, readability
http://docs.pylonsproject.org/en/latest/docs/pyramid.html
http://docs.pylonsproject.org/projects/pyramid/en/1.5-branch/quick_tour.html
maintainability
https://github.com/Pylons/pyramid/releases
>>> x = object()
>>> assert hasattr(x, '__name__') == False
>>> print(object.__doc__)
>>> setattr(x, 'one', True)
Traceback (most recent call last):
File "<ipython-input-10-7337de08fc39>", line 1, in <module>
setattr(x, 'one', True)
AttributeError: 'object' object has no attribute 'one'
What?
>>> class A(object):
... pass
... a = A()
... a.__dict__['one'] = True
... assert a.one == True
http://docs.python.org/release/2.5.2/ref/slots.html
By default, instances of both old and new-style classes have a dictionary for attribute storage. This wastes space for objects having very few instance variables. The space consumption can become acute when creating large numbers of instances.
The default can be overridden by defining
__slots__in a new-style class definition. The__slots__declaration takes a sequence of instance variables and reserves just enough space in each instance to hold a value for each variable. Space is saved because__dict__is not created for each instance.
http://docs.python.org/2.7/library/collections.html#collections.namedtuple
http://stevedore.readthedocs.org/en/latest/index.html
Python makes loading code dynamically easy, allowing you to configure and extend your application by discovering and loading extensions (“plugins”) at runtime. Many applications implement their own library for doing this, using
__import__orimportlib. stevedore avoids creating yet another extension mechanism by building on top of setuptools entry points. The code for managing entry points tends to be repetitive, though, so stevedore provides manager classes for implementing common patterns for using dynamically loaded extensions.
Yes it is called monkeypatching. It sounds dirty and nasty but it is done in one place at the top of the file
.
... I guess when I said 'magical adapter', I meant something for adapting a twisted.internet.interfaces.ITransport to asyncio.transports.Transport; or is it too difficult to work with callbacks and yield froms at the same time?
It sounds like you expected this additional module to unify existing code and re-implement protocols for you? I still fail to see how an additional approach prevents you from continuing to do exactly what you were doing.
... http://code.google.com/p/tulip/wiki/ThirdParty
[EDIT] They are different approaches. Is there a magical adapter? I don't know that that has been written yet. What would solve your problem?
How does that prevent you from accomplishing your objectives?
Everyone has forgotten why monkey patching is bad, just that it is,
Where are the tests for this?
Is there a reason you seem so excited about the new hotness?
Like the internet? Can I tile my wallpaper?
IMHO, I would be concerned about said colleagues becoming attached to an infeasible GUI theme which they might have to waste time re-learning. Much more economical to use an existing set of standard GUI widgets (with Python bindings) which they already understand how to operate... e.g. Qt, Gnome, Tk, wxWidgets, CSS/JS frameworks.
... http://www.agilemodeling.com/essays/barelyGoodEnough.html
You didn't mention which platform you would like to spend your time developing your own GUI for, because of themes.
pypa = Python Packaging Authority
Source: https://github.com/pypa/virtualenv
Documentation: http://www.virtualenv.org/en/latest/ (http://virtualenv.rtfd.org/)
Source: http://hg.python.org/cpython/file/3.3/Lib/venv
Documentation: http://docs.python.org/3/library/venv.html (http://python.readthedocs.org/en/latest/library/venv.html)
Travis support for e.g. https://github.com/klen/pylama (PEP8, PEP257, PyFlakes, Mccabe, Pylint, gjslint) would be really cool.
An XML or JSON reporting format (like JUnit XML) would be really helpful; but (not having looked) it shouldn't be too difficult to write a line-based parser for the existing console output.
I'm sorry I didn't remember to include the issue number as #nn in my commit message!!!
(except the default JSON writer for Python didn't put carriage returns in).
You can add an indent=n to the call to json.dump/json.dumps to add carriage returns (and indentation).
@decorator in a Wiki page as a bitbucket username?\@?Paths for resolution:
@https://en.wikipedia.org/wiki/Concurrent_programming
http://en.wikipedia.org/wiki/Python_(programming_language) + http://code.google.com/p/tulip/
[is there any sort of best practice for dynamically allocating how much memory a python process can use?]
Google Custom search for http://schema.org/Datasets : http://datasets.schema-labs.appspot.com/
Procedurally?
text/html + RDFa application/xhtml+xml + RDFatext/html + Microdataapplication/json+ldtext/turtletext/n3]application/json+ld] |text/html || application/xhtml+xml ]So, an HTML5 with RDFa application could serve text/html with something like:
<body vocab="http://schema.org/">
So, it sounds like you might have:
A http://schema.org/WebPage which contains factual and logical assertions (that could be 'parsed' or 'inferred' into a Named Graph) which contradicts factual and logical assertions in another http://schema.org/WebPage (with a http://schema.org/url property).
There may be an http://schema.org/AssessAction of some type (that may optionally include a http://schema.org/comment).
...
[EDIT] links to redd.it/1o4v5k/ccqr1ew
http://en.wikipedia.org/wiki/Resource_Description_Framework
http://en.wikipedia.org/wiki/Data_validation
http://en.wikipedia.org/wiki/Referential_integrity
http://en.wikipedia.org/wiki/Information_security#Key_concepts
http://cwe.mitre.org/data/definitions/400.html
... named graphs, statement-level reification, time, and RDF truth values (e.g. OpenCog "Truth Values" and "Attention Values")
Datasets
[EDIT] 'Datasets' heading
Many of these Python courses already offer or are starting to offer some sort of certificate or badge to indicate completion:
Sources on http://github.com and http://bitbucket.org could be helpful.
http://okfn.org -- Open Knowledge Foundation
Classes start: 15 Jan 2014
http://en.wikipedia.org/wiki/Linear_algebra
http://en.wikipedia.org/wiki/SciPy
http://en.wikipedia.org/wiki/SymPy
[EDIT] /r/ipython sidebar links to a number of useful libraries for data analysis
+1 for outline editing.
[[WikiWords]] for a wiki syntax. (e.g.vimgrep \[\[\(.*\)\]\]).Would be great if there was some sort of syntax for linking nodes together
YAML might be good...
* ReStructuredText requires 'implicit references' like headings to be unique for #deep-linking
http://blog.sqrrl.com/post/59413865358/mits-accumulo-performance-benchmarks
In this paper MIT reached ~400,000 writes per second per node across an 8 node cluster. This is impressive performance given that MIT cites HBase as supporting ~60,000 writes per second per node and Cassandra as supporting ~35,000 writes per second per node.
[EDIT]
Like cached JSON[-LD] for each region with an open standard for specifying plan features?
It sure would be great if we just required http://schema.org RDFa -- and/or Microdata -- on the providers' own web pages; which could be indexed by any search engine.
An asset management tool with CDN * support may also be helpful for working with pictures and videos in addition to HTML, CSS, and JS files.
Asset compression:
[EDIT] Conceptually, it could be as simple as a JSON file with pathnames and optionally cached file-level metadata; optimally containing dereferenceable URIs (URLs) linking the data with structured attributes; for example certain categories or tags.
The not-/marketplace parts of http://healthcare.gov (static HTML generated from Ruby, Jekyll) do seem to be working just fine: https://github.com/CMSgov/healthcare.gov
DSPL: Dataset Publishing Language
http://schema.org/docs/full.html
http://matplotlib.org/users/whats_new.html#pyqt4-pyside-and-ipython (/r/ipython sidebar)
The most famous example is the one-line lambda limitation, which is often seen as a direct consequence of the whitespace-as-syntax design decision, but the root cause is actually much deeper: The statement/expression boundary. Python makes a very strong distinction between these two, and a lambda can only contain one expression - but even though expressions can (and often do) have side effects, it is not possible to chain them together in a do-block fashion.
__name__ or __doc__ stringsTypical functional programming languages usually just consider everything an expression, and they provide a way to chain them together sequentially, such as progn in many Lisps, or certain Monads in Haskell.
functional programming is just a paradigm that is very suitable for writing concurrent and parallel code.
There is no way to enforce immutability in a consistent, reliable and idiomatic way
strs, unicodes, and tuples are immutable *@property getter without a setter.Yes, you can do functional programming in Python, but if you really go all the way and apply FP patterns everywhere, the resulting code is going to be a completely un-pythonic mess.
Why doesn't everyone like my macros?
Strictly speaking, I'm not sure that a comprehensive understanding of CS is really necessary in order to learn tools for data science.
Perhaps most practically, "How do I leverage available tools for data analysis in order to 'fit' this data?".
Is it useful to have an understanding of the low-level code that powers a machine learning ensemble search? Absolutely.
Is it appropriate for data scientists to be having to optimize the underlying algorithms? Not at all.
That collaborative handoff between investigative science and hard-compsci, I think, is more about communication and team-level trust than about having "the best compsci skills" or even "the fastest big data tools to big data things".
I think this is counter-productive, elitist, and dependency-suggestive. Learn Python however you'd like. If you want a compsci-level understanding of Python, read the C.
Here's the source: http://hg.python.org/cpython
[EDIT] http://docs.python.org/
https://en.wikipedia.org/wiki/Python
perhaps to things like checksum verification.
http://stevedore.readthedocs.org/en/latest/
Python makes loading code dynamically easy, allowing you to configure and extend your application by discovering and loading extensions (“plugins”) at runtime. Many applications implement their own library for doing this, using import or importlib. stevedore avoids creating yet another extension mechanism by building on top of setuptools entry points. The code for managing entry points tends to be repetitive, though, so stevedore provides manager classes for implementing common patterns for using dynamically loaded extensions.
From http://excess.org/urwid/wiki/HowYouCanHelp:
Adopt the web_display module - something modern and websocket-y would be awesome
WSGI + WebSockets might be useful.
!wget example.com[...] looks like the urwid module dependency requires a unix-like OS to run.
Does anyone know any similar visual debuggers for python that can run on windows?
So, pudb install_requires urwid, which utilizes ncurses, which works over telnet and rlogin.
For context.
From https://en.wikipedia.org/wiki/Linked_Data :
- Use URIs to denote things.
- Use HTTP URIs so that these things can be referred to and looked up ("dereferenced") by people and user agents.
- Provide useful information about the thing when its URI is dereferenced, leveraging standards such as RDF, SPARQL.
- Include links to other related things (using their URIs) when publishing data on the Web.
/a)https://en.wikipedia.org/wiki/Python_(programming_language)
https://en.wikipedia.org/wiki/Audio_engineering
https://en.wikipedia.org/wiki/Musical_acoustics
Books:
There can be multiple parent classes. (e.g. mixins, composition, eigenclass model)
While this is helpful, it would be great if it wasn't necessary to search the list twice; or handle ValueError.
L.index(value, [start, [stop]]) -> integer -- return first index of value.
If dict (or OrderedDict, or defaultdict) is more appropriate for the use case:
D.get(k[,d]) -> D[k] if k in D, else d. d defaults to None.
... http://pandas.pydata.org/pandas-docs/stable/missing_data.html
pd.tseries is partially derived from scikits.timeseries.
Also, astropy.time.
However as far as the interfaces go, they are really just a form of documentation, there's no code enforcing an object implementing the contract expressed by the interface in most cases.
The /r/ipython sidebar lists a number of useful libraries and resources for learning Python for science.
From python.org:
Extra appreciation if it is related to geometry, spacial data processing, and finite element analysis. Thanks!
But zca is a pyramid implementation detail. most wont even need to be aware of it.
From here:
Accordingly, Pyramid tends to hide the presence of the ZCA from application developers. You needn’t understand the ZCA to create a Pyramid application; its use is effectively only a framework implementation detail.
However, developers who are already used to writing Zope applications often still wish to use the ZCA while building a Pyramid application; pyramid makes this possible.
But if you need something like a service locator or that's how you prefer to design things [...]
I suppose my question was more about use of design pattern terminology:
between Python and Java.
Pyramid Source:
Tuples are immutable -- http://docs.python.org/2/tutorial/datastructures.html#tuples-and-sequences :
a = tuple(0,1,2)
assert a[0] == 0 and a[1] == 1 and a[2] == 2
assert len(a) == 3
collections.namedtuples work sort of like C structs -- http://docs.python.org/2/library/collections.html#collections.namedtuple :
namedtuples can be subclassed:
from collections import namedtuple
TriangleTuple = namedtuple('TriangleTuple', ('a','b','c'))
t = TriangleTuple(3,4,5)
print(t)
# TriangleTuple(a=3, b=4, c=5)
print(t.a)
# 3
class Triangle(namedtuple('Triangle', ('a','b','c'))):
def str_2(self):
return '\n'.join(
': '.join((str(k),str(v)))
for k,v in self._asdict().iteritems())
t2 = Triangle(3,4,5)
print('%s' % str(t2))
# Triangle(a=3, b=4, c=5)
print(t2.a)
# 3
print('%s' % t2.str_2())
# a: 3
# b: 4
# c: 5
assert t == t2
assert t == tuple(x for x in t2)
"SPARQL support" could mean one of two things: ability to query remote stores over HTTP, and the ability to query local stores (not over HTTP).
So, to clarify ex:hasFeature wiki:SPARQL:
| SPARQL Support | Local Database | Remote Database | Interface / Parser |
|---|---|---|---|
| Full | |||
| Partial |
I suppose another chart could be made for wiki:SPARUL.
I thought sparql.js (from thefigtrees.net) was the only Javascript implementation, and its the only Javascript library I see in that list. I was not aware of any of those other Javascript implementations you mention (rdflib etc. I know) offering SPARQL+HTTP query support.
A SPARQL query like the following might be helpful in a search for Javascript things (e.g. schema:Code) featuring SPARQL support:
PREFIX ex: <http://example.org/ns/>
PREFIX wiki: <http://dbpedia.org/resource/>
PREFIX schema: <http://schema.org/>
SELECT DISTINCT ?s ?p ?o
WHERE {
{
?s ex:hasFeature wiki:SPARQL . }
UNION {
?s schema:mentions wiki:SPARQL . }
UNION {
?s schema:keywords "SPARQL" . }
UNION {
?s schema:programmingLanguage wiki:Javascript .
}
}
LIMIT 100
http://www.cambridgesemantics.com/semantic-university/sparql-by-example
We need a Ruby on Rails / Django for RDF / SPARQL or something.
What are the essential tiered framework features here?
Essentially, mapping HTTP URIs to resource lookups based on parameters like
and rendering the located persisted resource(s) into various serialized representations:
OK, I see how one may want another front end, and may forgo a SPARQL endpoint altogether and opt instead for a custom JSON-LD API using (possibly standardized) RDF consumption libraries to do interesting things, possibly within a server-side app.
I really never think of these things until I have a conversation about it. (Maybe I should start talking to myself
I admit I'm at a loss as to what you mean by this.
Because of the depth and breadth of SPARQL (and SQL), it is difficult to estimate the complexity and running time of user supplied queries. (What is a sensible LIMIT clause?)
I am now. But my point was that, without DBslayer, limitations with SQL servers pretty much demand there be a frontend (server-side app) controlled by the developer.
"I don't carry Dapper Dan, I carry Fop."
WebSocket support might be cool; but still there's no guarantee that user supplied input will be correctly parsed as well-formed SPARQL/SPARUL/SQL/HTML.
This is a classic tradeoff question right?
Absolutely.
IMO the whole server-side architecture came about because SQL was just not designed with the WWW in mind.
I think having server-side code is going to needlessly complicate matters.
My question has to do with the halting problem.
Because, as I understand, Javascript is able to handle the SPARQL architecture, while it cannot handle the SQL architecture (and the SQL architecture cannot handle random clients.)
Are you familiar with DBslayer?
Almost everything else you mention is either not a client-side Javascript library, or does not support SPARQL over HTTP. I mean, supporting RDF serializations is good, but is downloading 300MB worth of RDF files into a Javascript app really a viable solution? I don't think so. I think SPARQL over HTTP is the best solution, and unfortunately its support mirrors SPARQL endpoint availability: slim to none.
http://www.w3.org/wiki/SparqlImplementations
Can you describe what these projects provide, in your words?
Universal data models. It would be hard to summarize the work of all of these authors.
We are seriously lacking an layman's overview of this stuff
What's interesting is that this forum is so amenable to plaintext Markdown discussions containing URIs:
From a design standpoint:
#id and .classes?What are the essential tiered framework features here?
I'm not a Django or Rails user, so again I will just take a stab at this. The whole point of Django / Rails was that a human was needed to interpret what the database data actually meant, right? With RDF this knowledge is explicit in the vocabularies. So all that is needed are Django / Rails models (or whatever it is they use) for common RDF vocabularies, correct?
Two ways to store RDF in SQL
tables of triples with indexes for s, p, o
'flattened' / specific sets of attributes and URI-keyed relations
That means GeoSPARQL and Data Cube vocabulary, and whatever other vocabularies that are meant for human consumption.
OWL and related are really "logical" vocabularies not really meant for human audiovisual consumption, unless your webapp is built to edit RDF ontologies or something.
Was this what you were asking?
A call for informal textual discussion through reddit, in Markdown?
rdf:Property level #name/id deep links would be cool.
We need a Ruby on Rails / Django for RDF / SPARQL or something.
Django
Pyramid
I have successfully used it to make an client-side Javascript webapp that can query any SPARQL endpoint and add any GML or WKT data returned (think GeoSPARQL) into an OpenLayers map.
Cool! Sounds like MapFish/Papyrus; with SPARQL.
As a consumer of RDF data, I think it would be unwise to write your Javascript app around a single RDF serialization
I agree. The last bullet point here is about LDP, which specifies [SHOULD support Turtle (... MAY support JSON-LD)].
There are some attempts at creating RDF data from different data sources (rdflib's csv2rdf, rdb-direct-mapping, GRDDL), but I usually find it easier just to write a simple Python script
We need a Ruby on Rails / Django for RDF / SPARQL or something.
What are the essential tiered framework features here?
What are some of the best practices (tools, techniques, procedures) for working with SPARQL in Javascript?
How should string concatenation issues be handled?
Say I'm building a query for for read/write SPARQL Update / SPARUL:
<<< predic = "great!>;"
<<< object = "<object>"
<<< turtle = "<subj> " + predic + object + ";"
<<< print(turtle)
>>> "<subj> great!>; <object>;"
[Simple string concatenation doesn't escape control characters].
< /> ' " <!-- -->< > ; ' " . #{ } [ ] " ' :In JS, working with JSON-LD may be easier in that everything
is serialized to { nested: { 'key': "value" } } dicts.
Like MarkupSafe,
It's tempting to use some sort of a templating system with,
say, autoescape for Literals, but URL-encoded URIs don't exactly join nicely.
How does JSON-LD integrate with JS framewoks?
Is there a standard for mapping RDF classes to JS UI 'widgets'?
Is there a way to generate templates/bindings from existing models?
Javascript (Browser side, ):
JS: rdfstore-js (docs)
JS: Backbone: http://documentcloud.github.io/backbone/#Model
JS Angular: http://docs.angularjs.org/guide/dev_guide.mvc.understanding_model
...
Server-side:
...
What about PDF forms?
For a production scale web application, where are the 'materialized SPARQL views' most efficiently composed, cached, and templated?
W3C LDP Linked Data Platform applications support a RESTful API collection metaphor, SHOULD support Turtle (.ttl), and may support JSON-LD (.jsonld). Does LDP afford advantages to web application developers as compared with SPARQL/SPARUL?
[EDIT]: JS (Javascript) labels, ellipses, rdfstore.js -> rdfstore-js, Virtuoso SPARQL documentation
I have a project at work that involves gathering as much information as humanly possible
there are many "fact" libraries out there that output readily usable JSON like those used in chef, puppet and ansible.
https://en.wikipedia.org/wiki/Comparison_of_open-source_configuration_management_software
It doesn't have to be JSON -- it could be XML, YAML, CSV or anything readily imported as data.
It could also just be a python library that reads C structs into typed data structures.
lshw
None, I was only kidding around.
Same, thanks, for the helpful link you shared.
It's possible that the logic bit was relatively sequential and I may be wasting my time.
A brief look into your comment history confirms my initial suspicions that you're a search engine disguised as a redditor.
False.
If only I didn't experience time unidirectionally, I could just make use of the system I wish to build to intelligently summarize and prioritize these sources for me, thereby allowing me to build the system in the first place.
Which points should be more emphatic?
Direction for personal research into bottlenecks of logic programming, knowledge representation and expert systems.
My reading brought me to an NLP experiment involving the grouping of words as concepts by crawling Wikipedia and taking context into account. The illustration of the work was similar to a projection from a support vector machine.
After some exposure to Prolog and predicate logic (as well as CSP and SAT solvers) I'm beginning to see some beauty in symbolic logic programming. I believe this is used to some degree in IBM's Watson as well. I'm told that on common architectures the combinatorial explosion outside of toy problems proves overwhelming, and parallelism is paramount.
Which paradigms of parallel and/or distributed computing are candidates for addressing these bottlenecks, both in symbolic A.I. and in sub-symbolic approaches? I have a surface level understanding of map/reduce, GPU processing, the actor model, and specialized chips such as FPGA and ASIC; but not nearly enough context to know which of these if any I should focus my attention on.
A search for [ API explorer ] may be useful.
RESTful #Web_APIs
I've read most of the Pyramid source and while it works, is well tested, and well documented, I don't really think its elegant. I mean I personally even use Pyramid but things could have been done easier and cleaner. (Look at all those factories and interfaces that just screams java)
While interfaces and factories make Test Driven Development much simpler, the only necessary interface for a Pyramid application developer is a callable (a function or a method) that takes a Request as the first parameter and returns a Response:
https://en.wikipedia.org/wiki/Separation_of_concerns#See_also
Disclaimer: If you're saying "oh well if it could be done better, go fix it" well I can't.
Here's an alternate approach using the ast module: https://github.com/public/vim-sort-python-imports
I am looking for suggestions of elegant code, well written and readable code, and code that makes use of best practices. Suggestions?
Excellent tutorial. sphinxjp.themes.revealjs is pretty cool too.
http://www.reddit.com/r/semanticweb/comments/1gbuvp/explain_linked_data_like_im_five/#caiw8bu
God forbid Python developers grow up and actually commit to an interface.
How would subclassing collections.abc or something like zope.interface or pycontracts help when the interface changes between versions? What do you do when the interface changes to accommodate additional features?
semver.org suggests a MAJOR.MINOR.PATCH version scheme. Bump the "MAJOR version when you make incompatible changes" and the "MINOR version when you add functionality in a backwards-compatible manner".
pip-review from pip-tools helps to identify new versions of package dependencies on a regular basis.
The _repr_<type>_ methods of IPython.core.display.Image are what make this possible with different formats.
From http://www.reddit.com/r/Python/comments/1drv59/getting_started_with_automated_testing/c9tfxgd :
Testing Techniques: Patches, Tags, Branches, Merging
Testing Techniques: DVCS: Bisect, Blame
https://en.wikipedia.org/wiki/Massively_distributed_collaboration
http://www.reddit.com/r/Python/comments/1j1idm/self_learning_sites/cbajb83
http://www.reddit.com/r/Python/comments/1eboql/python_website_tuts_that_dont_use_django/c9yxl8w
http://www.reddit.com/r/django/comments/1ktlwy/is_django_capable_of_a_web_ui/cbsh3b5
http://www.reddit.com/r/Python/comments/1b4uy3/pythonbased_health_care_exchange/c93pfhx
Wikipedia:
ASM
Online Courses:
It looks like the OpenDST sources reference the docs for
Which will install /r/ipython notebook, numpy 1 , pandas, statsmodels, scikit-learn, matplotlib for these notebooks, as well as many other outstanding python libraries for /r/datascience.
http://greenteapress.com/thinkapjava/
http://rosettacode.org/wiki/Rosetta_Code may also be a useful reference for your computer science studies.
Criteria
Is python a good tool for visualization?
/r/IPython notebook (top posts)
You might check out the /r/IPython sidebar
Scientific Python Lectures - Lecture 2: Numpy
A Crash Course in Python for Scientists
Python Scientific Lecture Notes
"Improper Neutralization of Special Elements used in an SQL Command ('SQL Injection')"
Otherwise, I'd say you might try Javascript. You can get a lot of mileage out of working with JSON-LD, SPARQL HTTP protocol & Javascript. Also gets you triple store independence, which is a good and bad thing. Good for the flexibility, bad in case you want to use triple store specific features. The downside is the library support is pretty minimal.
There is a reasoner, but I'm not sure how capable/well-maintained it is.
There must be OWL-RL / OWL-DL / OWL-Lite inference test sets somewhere...
These may help provide some context to your relational database studies: http://www.reddit.com/r/compsci/comments/1e3mht/is_rdbmss_and_sql_still_part_of_the_standard/#c9x5nsm
The suggestion is more on how people link to Notebooks as well as author them.
Like a more descriptive blurb / summary?
I'd prefer if the authors of notebooks put in a title, license, and authors field up at the top so it's easier to track down who is responsible for the content.
Sort of like ReStructuredText field lists?
I'd also prefer if people linking on places like reddit fill in whatever information they have about this if it's missing.
The only thing I think nbconvert could do here is add a field pointing to the owner of the gist on GitHub.
if is_gist_url(nb_url):
add_gist_link_below_download_notebook_link()
/r/learnpython may be more receptive to requests than announcements.
[EDIT] http://www.reddit.com/r/django/comments/1ktlwy/z/cbsh3b5
nbviewer runs nbconvert to render an .ipynb source file to an HTML template.
You can download the notebook .ipynb source file by clicking the 'Download Notebook' link.
[EDIT] Or with s/nbviewer.ipython.org/gist.github.com/ if the URL matches \d+.
Do you have a suggestion for how that could be improved?
This is a special case of the subset-sum problem
PyPi: Topic :: System :: Networking
Packets
Network Client/Server
HTTP / WSGI
[EDIT]
Hi- I'm coming from the java world,
and I'm having a bit of a tough time understanding all of the components that go into a production Python web application deployment.
Can anyone break these down to help me understand what each component in the stack does?
A web application or a web service can be composed from various WSGI middleware components (python callables which support the WSGI interface):
It seems that web frameworks, like flask & django, provide hooks to a WSGI application, which handles the conversion of raw HTTP-ish things into objects that your app can handle (request, response, etc).
But sometimes, you can embed the runtime into a web server (mod_wsgi), or you can proxy to a stand-alone WSGI application (gunicorn, uWSGI) - which are python programs that handle HTTP requests that call the framework,and then your application code.
And then there is the asynchronous world of Tornado & Twisted.
I'm not sure how they fit in.
The kind of data I'm storing is more like the kind of information you'd store in a database though; information you'd later want to present to an API consumer or to a template. Web application stuff, for the most part.
fixture is good at this.
These may also be useful:
Changelogs and github compares for Django, Flask, and Pyramid:
You're going to need a whole stack.
I am not a web developer so sorry for the limited terminology.
What I want to make is a small app that other coworkers can reach via their web browser.
Can Django do this on it's own or would I need something on top of it for web ui(like Bootstrap)?
So, like any other Django application, django.contrib.admin is built from templates which include CSS and JS:
There are a number of ways to use the Bootstrap 2 and/or 3 JS and CSS files in a Django project:
For the Django admin application:
For Django applications:
What is the best way to set up a webserver running a few vhosts for one client?
Clarification / Use Case(s)
Background
Webserver Configuration Documentation
Right now I have a root user and a normal user. The normal user owns /var/www.
For static files, cloud hosting platforms (e.g. AppScale, Docker, OpenStack) and configuration management may seem unnecessary today.
/etc/init.d/READMEman update-rc.d/etc/init.d/skeleton to /etc/init.d/appname/etc/init.d/appnamesudo /etc/init.d/appname <start>sudo service appname <restart>service --status-all Lists are pretty basic data types, as these things go. It's like asking "what's a neat thing you've done with strings?"
QT's QStyle and QML support 'skins', which are very similar to CSS.
GTK (Gnome) supports themes:
These may be helpful for developing a modern GUI in your Python project:
Thanks for this!
So there are a number of project templating solutions (pypi search: "project template"):
paster (pypi: "paster template", "PasteScript")templer (pypi: "templer template")mrbob (pypi: "mr bob template")pcreate (pypi: "pcreate")From http://www.reddit.com/r/Python/comments/1jqo4w/looking_for_a_text_template_solution/ :
Both SaltStack and Ansible support Jinja2 templates. There are also a number of recipes for zc.buildout that support Jinja2 templates.
Someday, I should prepare a template with the following:
setup.pytox.iniREADME.rstCHANGELOG.rstCOPYING / LICENSE (lice from /u/jacobian's requirements.txt)And:
docs/conf.py (sphinx-quickstart)gh-pages / github-toolsI also find it helpful to link #[\d]+ in changelog messages to project issues / tickets / stories.
[EDIT] Links
Is there a way to put this big query into some sort of function within the models themselves?
To be clear, I don't typically have a problem reading documentation produced by others with Sphinx. I have a problem with using Sphinx myself.
Automatic documentation is not a primary goal of Sphinx, where prose separate from your source code is encouraged instead.
The rest of the Internet uses Markdown. I only have room in my brain for one plain text markup language.
From here (emphasis added):
If only just 1% of modern Python packages knew how to write good docstrings,
- http://sphinx-doc.org/markup/desc.html#info-field-lists (
param,type,raises,returns,rtype)- http://google-styleguide.googlecode.com/svn/trunk/pyguide.html?showone=Comments#Comments (
Args,Returns,Raises)- https://github.com/numpy/numpy/blob/master/doc/HOWTO_DOCUMENT.rst.txt#sections (
Parameters,Returns,Raises)
What are some ways the typical provider or healthcare org can make use of this?
Pages, papers, and articles can reference common vocabularies for healthcare related terms for things like symptoms and treatments by including structured data within HTML markup (as Microdata and/or RDFa), making it very easy to search for relevant information.
From here:
.
Off the top of my head I imagine we should better annotate our public-facing webpages.
http://schema.rdfs.org/tools.html # Publishing / Form-based online tools
Are the major search engines already making use of these schemas?
Hi! How relevant are the following technologies to your position as a sysadmin for a cancer research organization?
https://help.ubuntu.com/lts/installation-guide/i386/preseed-contents.html#preseed-apt
https://help.ubuntu.com/lts/installation-guide/i386/preseed-contents.html#preseed-mirror
d-i apt-setup/security_host string security.ubuntu.com
d-i mirror/http/mirror select CC.archive.ubuntu.com
So why is it you can't set up a reddit clone with the code as easily as setting up a wiki using wikipedia's code?
https://github.com/reddit/reddit/blob/master/install-reddit.sh
... I'm seeing 933 'forks' of https://github.com/reddit/reddit from here.
askbot is an Open Source Q&A web application built with Django.
It appears that there is an html5lib adapter for gumbo.
RDFlib, pyRDFa, and pyMicrodata also parse HTML5 with html5lib.
You can get close to 100% usage on all cores with something like celery configured to spawn as many worker processes as cores (maybe n_cores - 1 for stability), though the celery task/message queue model does not solve for inter-process communication/synchronization and avoids locking.
How does a queue work?
Is there a long polling worker, which will act? How does this work? I am confused. Or do I need to have a cron job, running, which will keep firing a script to check if there is anything in the queue, for the given time(with the precision of minutes) if yes, then fire a worker.
https://en.wikipedia.org/wiki/Event_loop (*)
Celery can function like cron, but there is no need for celeryd to be called periodically by cron: depending on which message broker is configured, tasks are pushed/routed to Celery workers OR Celery workers pull/poll tasks from named queues.
http://docs.celeryproject.org/en/latest/tutorials/daemonizing.html
The goal is to let anyone describe something (with text, which is what they're used to think with), and then shape it into an actual RDF object (or into a partial-object that let you find a more complete RDF object, and maybe improve on it).
Why are there so few tools for RDF, Ontologies and SPARQL? Is it because they're so complex to build or simply because the semantic web is not mainstream enough? I can't see how they're so much complex than what exist in other fields.
There's no reason for a good SPARQL client not to exist. The best one I found had broken autocompletion...
A linked-data graph is a graph with nodes and edges.
A linked-data basic graph pattern looks something like the following, where s1 and o1 are the URIs (or literals) sought after:
<s1> schema:name <o1>;
<o1> a schema:WebPage;
"Programming the Semantic Web" p.24 demonstrates basic graph pattern matching in Python. SPARQL is described later in the book.
Here's the latest rdflib.plugins.sparql.evaluate.evalBGP
RDF(S) and OWL add logic and semantics to graphs. Triplestores have varying levels of support for evaluating inference rulesets for read/write SPARQL/SPARUL queries like INSERT, DELETE, SELECT, CONSTRUCT.
'Regular' graph datastores are not RDF(S)/OWL/inference aware, which is great for many use cases.
python -c "import sys; print('\n'.join(sys.path))"
pydoc site
strace -e trace=file -- python -c "import difflib" 2>&1 | grep 'difflib'
[EDIT]
python -m site
"So you're telling me there's a chance?"
After that I think you should be able to follow these instructions for installing IPython.
pip install -U ipython
Docs, sources, and tests for functools (@wraps, @partial):
FTR, ln is not defined in math, where the function for natural log is math.log(n).
Thanks! So, for something like math homework, there is assertAlmostEqual. Also __future__.division (PEP 238: Changing the Division Operator [2001]):
from __future__ import division # python 2
import unittest
class TestPracticalFloats(unittest.TestCase):
def test_practical_float(self):
self.assertAlmostEqual(1.000000000001, 1.0, places=7)
if __name__ == "__main__":
unittest.main()
Selecting arbitrary columns from a 2D array:
operator.itemgetter and operator.attrgetter for simple cases.
a = [[10,11,12],[20, 21,22]]
_itemgetter = operator.itemgetter(1,0)
assert list( itertools.imap(_itemgetter, a) ) == [(11,10), (21,20)]
_selector = lambda x: x[1][0]
assert _selector(a) == 20
Here's a (start at a) momentary mean / simple moving average function that yields floats.
From here:
(TIL Python floats are like IEEE-754 binary64 doubles, which have 53 bits of precision and that BigFloat wraps GNU MPFR in order to utilize arbitrary-precision arithmetic, while gmpy2 implements "a new mpfr type based on the [MPFR] library".)
Someone should write an RDF use cases document.
The author seems unaware of the complexities of developing interactive read/write linked data applications.
How do we link one field of a microformat to another field of another record? Do we need another language to express that part of the data model?
How do we build graphs of triples in browser-side javascript and send them back upstream? Should we be naively concatenating strings into HTML, SPARQL/SPARUL queries and RDF syntaxes that require escaping various control characters?
JSON-LD is very useful.
[EDIT] links
RDF Ontologies:
The biology terms from wikidata and wikispecies may also be helpful:
Here's a comparison grid of django packages for authentication: https://www.djangopackages.com/grids/g/authentication/
In terms of your specific use case, a search for "angularjs rest django" might be also be helpful. TastyPie and Django REST Framework are some of the simplest ways to get started. Let's read the source.
Both SaltStack and Ansible support Jinja2 templates. There are also a number of recipes for zc.buildout that support Jinja2 templates.
https://en.wikipedia.org/wiki/Obfuscation_(software)
Proprietary does not imply secure. Secure does not imply proprietary. ( 1, 2, 3 )
https://en.wikipedia.org/wiki/Security_through_obscurity doesn't work. Expect that someone has the source. Who has the source code? Where are the backups?
...
Hopefully no-one will test or review this, evar.
With Python code, it is possible to:
How would you test this? *
I don't know much about Tkinter.
Functional or object-oriented, standard software design patterns are easier to test.
I just feel like sometimes that writing an extremely simple program in OO is inefficient.
It can be easier to test specific parts of object oriented code by mocking objects than to [re-]compose functional chains.
Basically, my question is, why would you create a new class to inherit the features of frame if you're only going edit the parent and the background color? It would only take a line to do that if written in a procedural manner.
In the general case, an argument could be added to the constructor of Frame (with **kwargs) to support further configuration. (~factory method pattern)
... Configuration != instance state
Also relevant:
Is it possible to yield graphene from CO2? ... Graphene is useful for many things, like desalination.
These subjects are the bridges to advanced math.
the question is about whether students should have an intermediate "bridge course" all about practicing proofs, or whether that should be integrated into other classes.
...
Your original response was simply simply a collection of links about why proofs and proof theory are important, and did nothing to address the pedagogical question being asked.
I challenge you to formulate a more relevant answer, really. You reference "course" as though this study will be conducted in a vacuum. As though by taking the referenced course, a student is signing some sort of an exclusivity contract against understanding how they relate to the rest of the world.
Why would someone study proof theory? In order to reason about the world.
Now, what artificial limits to learning would you like to grant me the bounds for?
Could you do me a favor and share some resources regarding the value of studying proof theory? Maybe how it's used, how it's applicable to other mathematical studies.
I am not sure why this is being downvoted.
What is the value of "Intro to Proofs" classes? Is it really worth spending a lot of time studying "proof techniques?"
https://en.wikipedia.org/wiki/Outline_of_mathematics
https://en.wikipedia.org/wiki/Category:Logic
https://en.wikipedia.org/wiki/Category:Mathematical_logic
https://en.wikipedia.org/wiki/Category:Logical_calculi
https://en.wikipedia.org/wiki/Category:Statistical_inference
https://en.wikipedia.org/wiki/Category:Reasoning
https://en.wikipedia.org/wiki/Outline_of_computer_science#Mathematical_foundations
https://en.wikipedia.org/wiki/Category:Syntax_(logic)
https://en.wikipedia.org/wiki/Category:Formal_methods
https://en.wikipedia.org/wiki/Formal_verification
https://en.wikipedia.org/wiki/List_of_mathematical_symbols (LaTeX, MathJax)
http://www.reddit.com/r/semanticweb/comments/1dvakc/schemaorgdataset_standard_schema_for_linked_data/ # Semantic Web Background
There are a number of references (e.g. books) referenced from these wikipedia category pages:
http://en.wikipedia.org/wiki/Category:Machine_learning
http://en.wikipedia.org/wiki/Category:Data_mining
http://en.wikipedia.org/wiki/Category:Data_mining_and_machine_learning_software
I am a physical scientist who uses python as my primary programming language. I have never taken computer science courses, but taught myself by reading things like 'Learning Python' and 'Programming Python' a couple years ago. While I can do everything I want to do in Python with my existing knowledge, I'd like to really elevate my coding skill to more of a CS-quality level. I imagine there are many commands in Python that I don't know, or necessarily need to know, but which might help my coding. Furthermore, I'd like to improve the professionalism of my code as I might like to contribute to some open source projects in the future and don't want my contributions to look n00bish.
Any suggestions for how I might go about this? Are there any good websites perhaps that teach a little bit of obscure python every day that I could subscribe via RSS feed or something? Or is it just something I need "to do"?
password changing support
http://unix.stackexchange.com/questions/tagged/opensuse+ldap+autofs+nfs
https://ops-school.readthedocs.org/en/latest/config_management.html
https://en.wikipedia.org/wiki/Comparison_of_open-source_configuration_management_software
Requests: Your opinions, criticism, questions, or simply the correct search term to lead to the necessary tutorials. Many thanks!
Some sort of verification against http://www.uclassify.com/browse/prfekt would be great.
Awesome! Thanks! If only there were more accurate corpora for sentiment analysis.
Since you mentioned PEP8, have you looked at the Linux Kernel Coding Style document? It's a bit arcane in it's rules, but when you look at why the rules are the way they are, it makes sense. Not saying it's the right way, but it's another point of view with a good description for each decision.
+1 https://www.kernel.org/doc/Documentation/CodingStyle
To reply to your advantages:
Reduction in whitespace noise from version control changesets Not really sure what you mean by this. 3 tabs is 3 tabs regardless of whether they're 4 or 8 spaces in your editor.
True. Merging code between indent styles can create noisy patches and changesets.
https://en.wikipedia.org/wiki/Tab_key#Tabs_in_HTML
Consistency of display between cat, less, IDE, and web-based source browsers. Agreed. Not sure how important it is, but yes, consistency outside of your favorite, customized editor is good.
79 characters display in 79 characters Even then, I break this regularly depending on the line of code I'm working on. I try to adhere to an 80 character limit, but sometimes the code just looks much worse when you try to wrap. I blame Java :P
I blame URIs.
Thanks! TIL about https://en.wikipedia.org/wiki/Indent_style . In Python, where indentation denotes code structure, this debate is very old and usually settled by a reference to PEP8 and style checking tools like flake8, pep8ify, and condent:
Use 4 spaces per indentation level.
There are many reasons for soft tabs (tabs as [4] spaces) as opposed to hard tabs (tabs as \t).
Primary advantages:
Approaches:
validate && vcs commit):set nomodelineFor referencing creative works like books, the (existing) schema.org ontology has properties like isbn, sku and serialNumber. I'm not sure where to reference the DOI identifiers, though. There is ongoing work within the http://www.w3.org/community/schemabibex/ group to extend schema.org with more comprehensive modeling for bibliographic resources. There is some thinking involved, but it's thinking in groups, so
I feel that it requires less thinking to start with RDF (as Turtle/N3).
http://rdf-translator.appspot.com can convert between most combinations of RDFa, Microdata, RDF/XML, N3, NTriples, RDF/JSON, and JSON-LD.
It would be great to add support for this to (something like) sphinxcontrib-bibref, where there is a .. bibliography:: directive and a :cite:'1987:nelson' role.
Microformats map to RDF triples: http://semanticweb.org/wiki/Microformats_in_RDF
A friend recently pointed me towards codeacadmey.com and it's great so far!
http://www.codecademy.com/en/tracks/python
From here :
Also, these may be helpful for web development.
From https://github.com/zopefoundation/zodbpickle/issues/2 :
From http://docs.python.org/2/library/pickle.html#pickle-python-object-serialization :
Warning The pickle module is not intended to be secure against erroneous or maliciously constructed data. Never unpickle data received from an untrusted or unauthenticated source.
Upon unserialization (
.loads,.load), Python Pickles may execute arbitrary code.
pypi:dill github source mirror: https://github.com/uqfoundation/dill
One option is to author documents in a lightweight markup language like Markdown (e.g. Reddit, GitHub) or reStructuredText (e.g. docstrings, Sphinx, Read the Docs) that works well with version control and then generate the formats that you feel most appropriately share the information.
Sphinx reStructuredText Guide [.rst -> HTML, PDF, LaTeX, ePub, ...]rst2wordml [.rst -> .doc]... <-> ...]http://cartouche.readthedocs.org/en/latest/usage.html#overview
pip:cartouche reads help() readable docstrings in Google-style and generates Sphinx-style function markup (:param:, :returns, etc) for HTML/man/ePub; making it much easier to read __doc__ strings with plaintext help(<obj>) and print(obj.__doc__).
Supported
Args:, Returns:, Yields:, Raises:, Note: and Warning:) -- CartoucheArgs, Returns, Raises) -- Google -- http://google-styleguide.googlecode.com/svn/trunk/pyguide.html?showone=Comments#Comments Args, Returns, Yields, Raises) -- KhanAcademy -- https://sites.google.com/a/khanacademy.org/forge/for-developers/styleguide/python#TOC-Docstrings)Not Supported
Parameters, Returns, Raises) -- NumPy -- https://github.com/numpy/numpy/blob/master/doc/HOWTO_DOCUMENT.rst.txt#sectionspip:sphinxcontrib-napoleon supports Google and NumPy style docstrings:
Supported
Args, Returns, Raises) -- Google -- http://google-styleguide.googlecode.com/svn/trunk/pyguide.html?showone=Comments#Comments Args, Returns, Yields, Raises) -- KhanAcademy -- https://sites.google.com/a/khanacademy.org/forge/for-developers/styleguide/python#TOC-Docstrings) Parameters, Returns, Raises) -- NumPy -- https://github.com/numpy/numpy/blob/master/doc/HOWTO_DOCUMENT.rst.txt#sectionsNot Supported
:param, :type, :raises, :returns, :rtype) -- Sphinx -- http://sphinx-doc.org/markup/desc.html#info-field-lists While denormalization can help to work around consistency lag, a denormalized database may or may not be stored upon a consistent DBMS. Eventual consistency is more a property of distributed data stores (the CAP theorem) which do not block until all nodes are synchronized (until all data is replicated).
Are these data structures the kind of thing that would ever be included in a base python build?
pandas.core.frame.DataFrame requires numpy (import numpy as np)While, anecedotally, I agree with the author that the author knows more about database normalization than their long-haired opponent; I disagree with what seems to be a fundamental premise of the argument: that a normalized database "in fifth normal form" is superior to a (naievely) denormalized database.
I disagree that a model is better "because it needs more JOINs" or "because there is less duplication of data." Fifth normal form may be "technically correct", but woefully inadequate for most real-world applications that need to scale.
Dear DBAs: please store your schema and test data in version control.
[EDIT]
From here:
Does [...] maintain referential integrity and/or propagation constraints so as not to leave dangling pointers?
Here's this (visualized with pythontutor):
>>> [] is not []
True
>>> id([]), id([])
(161131916, 161131916)
>>> id([]) is not id([])
True
>>> id([]) is id([])
False
>>> id([]) == id([])
True
>>> a = []
>>> id(a) == id(a)
True
>>> id(a) is id(a)
False
>>> a,b = [], []
>>> a is not b
True
>>> id(a), id(b)
(161170668, 161169996)
>>> id(a) == id(b)
False
>>> list() is not list()
True
[EDIT]
http://pythonconquerstheuniverse.wordpress.com/2012/02/15/mutable-default-arguments/
And that is why you should never, never, NEVER use a list or a dictionary as a default value for an argument to a class method. Unless, of course, you really, really, REALLY know what you’re doing.
http://wiki.opencog.org/w/CogPrime_Overview#Competencies_and_Tasks_on_the_Path_to_Human-Level_AI
Autonomic chunking and reasoning seem to suggest more complexity than artificial neural networks (which do faithfully approximate many systems).
ymmv:
def streamavg_running_segment(itr, avg=None, seqpos=0):
"""
calculate momentary mean (cumsum/n)
optionally from {avg,seqpos}
:param itr: iterable of {int, long, float}
:type itr: iterable
:returns: cummean float generator
:rtype: generator(float)
"""
if not hasattr(itr, 'next'):
itr = iter(itr)
avg = avg or itr.next()
yield seqpos, avg, avg
for i,val in izip(count(seqpos+1), itr):
weight = (1.0 / (i+1) )
newavg = avg - (avg*weight) + (weight*val)
yield i, val, newavg
avg=newavg
why are so many studies being reversed? Is this just "part of the scientific process" in this area? Is this a territorial thing (researchers from one organization disagreeing with a competing organization that previously argued that their way should be a best practice)? Are these types of studies performed only on "suspicious" new best practices, and how much of a selection effect might be going on here?
[EDIT]
we push data structures for processing TO the templates only)
So, only JSON in the template context data?
https://en.wikipedia.org/wiki/Template_engine_(web)#Comparison
[...] security on either [..]
https://en.wikipedia.org/wiki/Separation_of_presentation_and_content
Really cool use of Flask and SQLAlchemy to build a RESTful HTTP HATEOAS facade for a defined set of SQL tables. Thanks! Legacy databases are always fun.
I assume you are using reflection to infer attributes and relations from the database with the extra cost of queries to introspect database schema?
FWIW, many migrations libraries can also generate a set of model mappings as python code from an existing database schema (e.g. as migration script #0)
One best practice from both of these libraries is an access-limited version table containing the current version of the database schema. There are arguments for and against including API version numbers with what are then not RESTful permalink URLs.
With URIs, RDF, and Linked Data:
Some bandwidth providers do strange throttling to make HTTP downloads look faster; making a rolling mean (or a moving average) a bit of a closer fit, in some cases.
where do those tests go?
https://code.google.com/p/soc/wiki/GettingStartedOnTesting#Organization_of_tests has some good guidelines.
[mocking resources] , unit / functional / integration testing
Testing techniques: Mocks : http://www.reddit.com/r/Python/comments/1drv59/getting_started_with_automated_testing/c9tfxgd
do you ever test 3rd party libraries?
To a point:
I believe there are also new CSS styles for http://preview.python.org/documentation/
matplotlib.pylab requires numpy which requires Fortran for some things.
http://docs.scipy.org/doc/numpy/user/install.html#prerequisites :
To build any extension modules for Python, you’ll need a C compiler. Various NumPy modules use FORTRAN 77 libraries, so you’ll also need a FORTRAN 77 compiler installed.
I'm very much interested in packaging a python "package".
The Hitchhiker's Guide to Python: Packaing Your Code should link to these:
The Hitchhiker's Guide to Packaging
[] where does it get the libraries from?
https://github.com/revolunet/PythonBooks
[EDIT] In no particular order:
You could add a setup.py file and a tox.ini with some tests.
The Hitchhiker's Guide to Python: Structuring Your Project explains conventional approaches to namespacing code in Python.
To this directory structure template I would also add:
README.rst (or README.md, instead of just README)requirements.txt listing package dependencies for pip install -rdocs/ directory with a conf.py and an index.rst (for sphinx)[EDIT]
List of projects created with Sphinx (src)
There could be more books:
Python PEP 440: Version Identification and Dependency Specification describes compatibility with Semantic Versioning: http://www.python.org/dev/peps/pep-0440/#semantic-versioning :
The "Major.Minor.Patch" (described in this PEP as "major.minor.micro") aspects of semantic versioning (clauses 1-9 in the 2.0.0-rc-1 specification) are fully compatible with the version scheme defined in this PEP, and abiding by these aspects is encouraged.
Index, Search, Docs
docs.python.org
python.rtfd.org
... some of the sphinx themes on pypi, github, and bitbucket are pretty cool; but pydoc is in standard lib.
Thanks! I notice that many of the Sphinx ReStructuredText markup constructs (roles and directives) are not natively supported by docutils; making things like sphinx.ext.autosummary and sphinx.ext.autodoc also useful.
[EDIT]
If only just 1% of modern Python packages knew how to write good docstrings,
param, type, raises, returns, rtype)Args, Returns, Raises)Parameters, Returns, Raises)Args, Returns, Yields, Raises)The /r/IPython sidebar lists a number of Python data analysis tools.
This thread may also be useful: http://www.reddit.com/r/datascience/comments/1eb7ef/linux_data_analysis_tool_suggestions/c9z2iga
This thread from /r/IPython may also be helpful for data analysis in Python: http://www.reddit.com/r/IPython/comments/1i8bgw/statistical_data_analysis_in_python_scipy2013/
+1. http://hg.python.org/cpython/file/v3.3.2/Lib/random.py#l254
import random
random.shuffle(range(1, int(1e6)+1), random=random.random)
Re: space efficiency
Python eggs are compressed archives.
Soft tabs ensure code always displays exactly the same which is required for the line length requirement. (which is important for working with code over ssh, or lots of code simultaneously locally)
Many Web browsers also have a default tab width of 8 characters; making web-formatted sources containing tabs tiringly deep to read.
It is wholly up to you, but http://stackoverflow.com/questions/120926/why-does-python-pep-8-strongly-recommend-spaces-over-tabs-for-indentation .
From http://www.python.org/dev/peps/pep-0008/#tabs-or-spaces :
Never mix tabs and spaces.
The most popular way of indenting Python is with spaces only. The second-most popular way is with tabs only. Code indented with a mixture of tabs and spaces should be converted to using spaces exclusively. When invoking the Python command line interpreter with the -t option, it issues warnings about code that illegally mixes tabs and spaces. When using -tt these warnings become errors. These options are highly recommended!
For new projects, spaces-only are strongly recommended over tabs. Most editors have features that make this easy to do.
Only import entire modules, never individual symbols from a module. For top-level modules, that means
import foo. For sub-modules, you can do eitherimport foo.barorfrom foo import bar.
With /r/IPython , http://ipython.org/ipython-doc/stable/interactive/tutorial.html#system-shell-commands :
!<cmd>
EDIT:
ipy = get_ipython()
ipy.system?
ipy.system??
ipy.system(u'<cmd>')
Regarding the switch statement
http://stackoverflow.com/questions/374239/why-doesnt-python-have-a-switch-statement
dict lookup (adapter pattern?)IRC is hard: do I owe you support? I want to help people, but frankly, if the discussion is unpleasant for some reason, I'm unlikely to continue. Talking about a construct that I find silly or counterproductive might be something I don't want to do, even if you find it fun.
...
However, I'm merely pointing out that the vast majority of highly knowledgeable people are very dismissive
good point, but only if you misuse decorators.
Import time side effects are an issue with module globals. The problem is specifically demonstrable with decorators that attempt to use globals.
Basically, it's fairly rare that you need to legitimately consult the IRC channel just to ask "which of these faster?"
It's a common beginner mistake to micro-optimize like that. The important thing is to know whether your filter() or listcomp will be linear or quadratic, for example.
http://wiki.python.org/moin/TimeComplexity and http://bigocheatsheet.com/ are great references for complexity analysis.
I think there is an optimum balance between maintainable patterns and mature optimization; and -- for the sake of parallelization -- it is good to get in the pattern of factoring things out into closures/kernel methods (without side effects) that can be applied to iterables.
The difference between filter() and a listcomp is incredibly unlikely to make a difference in the running time of your program.
In Python 2, filter consumes the entire iterable and returns a list, which may affect running time and memory usage. filter in Python 3 is itertools.ifilter in Python 2.
Exception: for third-party code, where the module documentation explicitly says to import individual symbols.
Global-registry-mutating microframework programmers therefore will at some point need to start reading the tea leaves about what might happen if module scope code gets executed more than once like we do in the previous paragraph. When Python programmers assume they can use the module-scope codepath to run arbitrary code (especially code which populates an external registry), and this assumption is challenged by reality, the application developer is often required to undergo a painful, meticulous debugging process to find the root cause of an inevitably obscure symptom. The solution is often to rearrange application import ordering or move an import statement from module-scope into a function body. The rationale for doing so can never be expressed adequately in the checkin message which accompanies the fix and can’t be documented succinctly enough for the benefit of the rest of the development team so that the problem never happens again. It will happen again, especially if you are working on a project with other people who haven’t yet internalized the lessons you learned while you stepped through module-scope code using pdb. This is a really pretty poor situation to find yourself in as an application developer: you probably didn’t even know your or your team signed up for the job, because the documentation offered by decorator-based microframeworks don’t warn you about it.
In the interests of facilitating this ironic discussion about how we collaborate to win:
you might:
python -m compileallsys.pathdis module and/or python-ptraceTIL that, for a one-time fee, ISO 80000-2:2009 will solve this universal language notation problem for you.
There are patterns for Software Development and for Distributed_Architecture/Enterprise_Architecture/Information_Systems. Different places draw different boundaries between the fields. Here's an outline of science # CS and a more comprehensive outline of computer science. I'm not aware of an outline of information systems.
"Software Pattern" owl:differentFrom "Information System Enterprise Infrastructure Architectural Pattern" .
"Systems Infrastructure" owl:differentFrom "Software Design" .
The overlap/intersection is considerable, though, so owl:disjointWith is probably not appropriate.
I think these are closer to what you are referring to:
[EDIT]
Http://Schema.org/Dataset may also be helpful for sharing datasets *
Yeah, and then the retractions are behind a paywall (and unrepeated by popular media) too.
+1 for DVCS. For example, NLTK stores their datasets in the gh-pages branch of a GitHub repository: https://github.com/nltk/nltk_data/tree/gh-pages
CKAN is awesome: http://docs.ckan.org/en/latest/linked-data-and-rdf.html
It would be great if it had SPARQL support.
Pandas -> PyTables -> HDF5
How would I know from the sidebar that https://github.com/kennethreitz/python-guide/blob/master/docs/scenarios/web.rst is relevant to this question?
Thanks!
${HOME}/.config/pyscp/config.json may be a more standard place to store the JSON configuration file.
"Monotonic periodic system from base-10"
So, the link to the (excellent) research produced by these federal grants is: "Verbal IQ of a Four-Year-Old Achieved by an AI system"[PDF].
there may be a tendency to read too deep into this. never mentioned X or Y, the unit circle, peaks...the light analog was an attempt to show the simplicity of the question.
My mistake. I found a model for binary oscillation to be relevant to the features of whole numbers which you seem to be describing. (e.g. like a wheel with two poles)
Again, the question was, has anyone considered the idea that numbers pulsate between even and odd?
I believe they call it even/odd parity; which disambiguates to the wikipedia article regarding Parity in a mathematical context.
I was more curious as to why this led to the posting of seemingly random Wiki articles regarding string theory
Quantization + supersymmetry + light... A connection to supersymmetry was referenced in another thread.
optical vortices, round-off error, and wave-particle duality.
IMHO, a light metaphor is not relevant to integer parity. I was confused. Can you accurately model an optical vortex (with fractional angular momentum) with integers? What is float rounding error?
IMHO, on/off and odd/even is also a false duality.
Cool insight.
http://en.wikipedia.org/wiki/Parity_(mathematics)#Higher_mathematics and http://en.wikipedia.org/wiki/Oscillation seem to describe what you seem to be referring to.
I just have no idea where you're getting the duality from in this context. The concept has literally nothing to do with viewing integers as peaks and troughs...
Trace your finger around the unit circle. The X and Y coordinates oscillate. The Y-maxima is at the peak, and the Y-minima is at the trough. What concept?
And taking about modeling light as an integer seems particularly meaningless, so I don't understand your question.
like repeating light on light off is a pulsation. a consistent "every other."
How would you model light? (According to quantum mechanics, light is both a wave and a particle). As an integer?
Thanks! +1 for the Gang of Four book (Design Patterns: Elements of Reusable Object-Oriented Software).
http://en.wikipedia.org/wiki/Software_design_pattern is also a great place to start.
FTFY: Computer scientist and biologist team up to apply social networking analysis techniques to interpreting Gene-Disease graphs
Schema.org links in with existing networks of linked medical data like BioPortal and http://lov.okfn.org .
Are you scaling a 2D figure or a 3D figure?
From http://en.wikipedia.org/wiki/Holographic_principle :
In a larger and more speculative sense, the theory suggests that the entire universe can be seen as a two-dimensional information structure "painted" on the cosmological horizon, such that the three dimensions we observe are only an effective description at macroscopic scales and at low energies. Cosmological holography has not been made mathematically precise, partly
just all positive integers
Like a sine wave with -1 in the trough and +1 at the peak? Like a unit circle with radius 2?
Make sure the app does not have filesystem permissions to e.g. write over itself
If you point DNS at your home IP: configure your firewall correctly and make sure your ISP supports personal web servers. Some residential ISPs do not allow inbound port 80.
Compare your SLA and security controls with a (cloud-) hosted service and/or a (cloud) hosting service with multiple backbone connections. Chances are that there is a business that can do it for less (or free), if you want to share the server.
http://www.reddit.com/r/Python/comments/1eboql/python_website_tuts_that_dont_use_django/
I have heard that AppScale abstracts out much of the system configuration work by standardizing on a common set of architectural components and a standard application container (app.yaml)
This answer describes loading netCDF with netCDF4-python into pandas Series and DataFrames; and drawing charts with matplotlib. Scikit-learn and statsmodels may also be useful.
Mappings between Schema.org, DCAT, ADMS, and VoID:
Mappings between Schema.org, Data.gov Common Core Metadata, CKAN, RDFa, dcat:, foaf:, dcterms:
http://project-open-data.github.io/metadata-resources/#common_core_required_fields_equivalents
Thanks!
These are also excellent: http://bradfrost.github.io/this-is-responsive/resources.html
PCAST: Engage to Excel: Producing One Million Additional College Graduates With Degrees in Science, Technology, Engineering, And Mathematics [PDF], February 2012, p. 5:
II. Strategies: The First Two Years
How to fill the need?
In the United States, fewer than 40% of the students who enter college with the intention of majoring in a STEM field complete a STEM degree. Most of the students who leave STEM fields switch to non-STEM majors after taking introductory science, math, and engineering courses.14
Many of the students who leave STEM majors are capable of the work, making the retention of students who express initial interest in STEM subjects an excellent group from which to draw some of the additional one million STEM graduates. Research on the exodus from STEM disciplines shows that many students who transfer out of STEM majors perform well, but they describe the teaching methods and atmosphere in introductory STEM classes as ineffective and uninspiring.15,16
Meteorology*# and Python
From https://pypi.python.org/pypi?%3Aaction=list_classifiers :
Topic :: Scientific/Engineering :: Atmospheric Science
From http://pypi.python.org/ :
Topic :: Scientific/EngineeringTopic :: Scientific/Engineering :: Atmospheric ScienceTopic :: Scientific/Engineering :: Atmospheric Science][(https://pypi.python.org/pypi?:action=browse&show=all&c=385&c=511)You can also search PyPi with e.g. google.com/#q=site:pypi.python.org+meteorology
http://docs.continuum.io/anaconda/ has quite a few http://docs.continuum.io/anaconda/packages.html (including numpy and scipy)
With anaconda, you can install other packages with:
https://python-packaging-user-guide.readthedocs.org/en/latest/ explains packaging and installing packages with pip (and conda pip install).
In regards to this list of Competencies and Tasks on the Path to Human-Level AI, what are you suggesting as criteria for sentience and sapience?
From here :
From http://dbpedia.org/page/Word-sense_disambiguation :
is foaf:primaryTopic of
is dbpedia-owl:wikiPageDisambiguates of
is dbpedia-owl:wikiPageRedirects of
owl:sameAs
dcterms:subject
Reading the source, tests, and documentation.
IDLE and Dive Into Python, [more php, mysql, rails], /r/django, /r/IPython, /r/plone, /r/zope, NLTK, /r/scipy, pandas, /r/pyramid.
If I was to learn Python now, I would probably start with :
And keep notes as IPython notebooks and/or ReStructuredText for Sphinx for later reference.
These are also great:
http://docs.python-guide.org/en/latest/
You could diff the set (graph) of installed packages with the standard set installed by default?
Applied Python Projects: https://github.com/thekarangoel/Projects
Is this about correlation or causation?
In regards to efficacious treatment of schizophrenia, what is the relation between the endocannabinoid system and Neuregulin 1 ?
Good call. There's also lxc-unshare, though I'm not sure how much if any difference there is from unshare.
https://en.wikipedia.org/wiki/Information_retrieval#Model_types
https://en.wikipedia.org/wiki/Search_engine_indexing#Index_data_structures
https://en.wikipedia.org/wiki/Compound_term_processing
https://en.wikipedia.org/wiki/Record_linkage#Probabilistic_record_linkage
http://text-processing.com/demo/stem/
http://www.reddit.com/r/Python/comments/1gzxhy/search_modules_for_python/#capgtd9
That's why I said "choose which mountpoints you can see in the server process" (see also man unshare)
I feel like I'm more likely to implement https://en.wikipedia.org/wiki/Cgroups#Namespace_isolation correctly with standard containers like OpenVZ and LXC.
I agree. Nothing personal. I took the time to pick these out for everyonees. This was the latest post of the first thread containing "python".
When a reader greps for URIs in this thread, what do they find?
Can you think of a more brief way to share the relevant resources in order to impart requisite sources for background knowledge, security information, and language-specific implementations regarding the handling of file paths, which are file:/// URIs, which are not URLs; and may contain JS and/or HTML escape characters and/or filesystem traversals?
Are you sure? Which of these did you find irrelevant to this discussion?
The whole point of UNIX is that there are no other paths than (virtual) filesystem paths.
https://en.wikipedia.org/wiki/URI_scheme#Official_IANA-registered_schemes
Pattern matching doesn't exist in the UNIX kernel
Yeah, that falls in line with the "kitchen sink" objection against the PEP. Though bringing up the "unix kernel" seems a bit irrelevant: a path is not a purely kernel-level only abstraction, and the point of a cross-platform library is to handle more than just unix.
http://rdflib.readthedocs.org/en/latest/utilities.html#sparql-paths
./file/Paths ("fully qualified file name")
posixpath)URI: Uniform Resource Identifier / URN: Uniform Resource Name / URL: Uniform Resource Locator
Awesome! How does mypy compare to / work with PyContracts (typechecking constraints as PEP 3107: Function Annotations, docstrings, decorators) ?
From PEP 3143: Standard daemon process library:
Writing a program to become a well-behaved Unix daemon is somewhat complex and tricky to get right, yet the steps are largely similar for any daemon regardless of what else the program may need to do.
This PEP introduces a package to the Python standard library that provides a simple interface to the task of becoming a daemon process.
The PEP 3143 reference implementation is python-daemon.
PEP 3143 is currently deferred but includes a list of other daemon implementations.
http://en.wikipedia.org/wiki/Open_access_(publishing)
http://en.wikipedia.org/wiki/Open_data#Open_data_in_science
http://en.wikipedia.org/wiki/Public_Library_of_Science
https://en.wikipedia.org/wiki/Comparison_of_open-source_software_hosting_facilities
https://git.wiki.kernel.org/index.php/Interfaces,_frontends,_and_tools
http://read-the-docs.readthedocs.org/en/latest/
https://github.com/jrjohansson/scientific-python-lectures
ipython/nbconvert supports "ReStructuredText, Markdown, HTML, Python, LaTeX, and Sphinx (and thereby PDF, ePub, Man, etc)"
http://en.wikipedia.org/wiki/Linked_data
http://www.w3.org/TR/prov-primer/
How does this periodic table for self-assembling nanoparticles differ from http://www.nano-ontology.org/ (BioPortal) [NanoParticle Ontology for Cancer Nanotechnology Research]?
http://en.wikipedia.org/wiki/Category:Applied_mathematics
http://en.wikipedia.org/wiki/Category:Applied_and_interdisciplinary_physics
http://nbviewer.ipython.org/urls/raw.github.com/jrjohansson/scientific-python-lectures/master/Lecture-5-Sympy.ipynb by J.R. Johansson (wakari /r/IPython notebook)
Python Scientific Lecture Notes: Sympy: Symbolic Mathematics in Python by F. Pedregosa (PDF, ZIP: HTML and example files)
Computational Physics: with Python by M. Newman
http://www.pbs.org/wgbh/nova/physics/fabric-of-cosmos.html (wikipedia, canistreamit)
What are the The Limits to Growth? What is needed?
How are current growth rates quantified? What is the most fitting model derived from extrapolation?
Maybe like carrying water on a bicycle driving up the side of a limit?
How does this compare to / work with Linked Data approaches like D2RQ and Linked Media Framework (http://marmotta.incubator.apache.org/)?
When merging three datasets with three different columns named 'price', 'Price', and http://schema.org/PriceSpecification, how should such a determination be repeatably documented?
From Wikipedia, about Statistics:
http://en.wikipedia.org/wiki/Outline_of_statistics
http://en.wikipedia.org/wiki/Outline_of_probability
http://en.wikipedia.org/wiki/List_of_fields_of_application_of_statistics
http://en.wikipedia.org/wiki/Outline_of_regression_analysis
http://en.wikipedia.org/wiki/Category:Statistical_models
http://en.wikipedia.org/wiki/Analysis_of_variance
http://en.wikipedia.org/wiki/Notation_in_probability_and_statistics
http://en.wikipedia.org/wiki/Glossary_of_probability_and_statistics
http://www.reddit.com/r/IPython/comments/1dl8wc/seeking_advice_for_introducing_ipython_in_high/
These MOOC playlists have video lectures :
Curriculum Search: Lectures, Assignments, Papers, Videos
Not yet (?) video lectures, but these may help with your Calculus studies and/or check figures:
http://docs.cython.org/src/userguide/pypy.html
[EDIT]
This page lists major differences and ways to deal with them in order to write Cython code that works in both CPython and PyPy.
Cool algorithm topology! It would be great if a wiki with stable permalinks to these algorithms (e.g. Complexity Zoo) implemented Semantic MediaWiki or similar, so we could search, sort, and generate graph visualizations of the defined algorithms and their rdf:Propertys.
These may also be useful to you:
https://en.wikipedia.org/wiki/List_of_algorithms
https://complexityzoo.uwaterloo.ca/Zoo_Glossary
RDF / Linked Data Ontology
https://en.wikipedia.org/wiki/Simple_Knowledge_Organization_System#SKOS_Core
http://answers.semanticweb.com/questions/18125/creating-an-owl-file-from-a-tree-hierarchy/18126
http://www.reddit.com/r/semanticweb/comments/1ff5kc/where_can_i_find_useful_ontologies
https://www.wikidata.org/wiki/Wikidata:List_of_properties/Summary_table#Generic
Graph Visualization
http://www.graphviz.org/doc/info/attrs.html#d:URL
http://networkx.github.io/documentation/latest/reference/drawing.html
http://networkx.github.io/documentation/latest/examples/
https://github.com/mbostock/d3/wiki/Gallery#force-layout
http://answers.semanticweb.com/questions/1071/visualisation-toolkits-for-rdf
Think Complexity by Allen B. Downey (in /r/Python)
http://api.jquery.com/header-selector/
https://github.com/ipython/ipython/blob/master/IPython/external/js/README
https://github.com/ipython/ipython/wiki/Roadmap:-IPython # Release 1.0 / (H,1) && (M,1) ... bootstrap, codemirror, require.js
NetworkX
From http://www.networkdynamics.org/static/zen/html/api/thirdparty.html#module-zen.nx :
The edge weight will be lost, as there is no separate edge weight attribute in NetworkX graphs.
From http://networkx.github.io/documentation/latest/tutorial/tutorial.html#edge-attributes :
The special attribute ‘weight’ should be numeric and holds values used by algorithms requiring weighted edges.
CogPrime also has weighted edges.
Style Points
it's just like we don't show users tables and tables of normalized relational data when we use SQL
Spreadsheets.
With Create.JS, VIE.js and Stanbol look really cool.
People do not need to consume RDF graphs. People need nice web-sites.
I suppose there is an optimal point between content and presentation; or between science and art, which is necessarily biased. I don't know.
Are art and design founded on logic and reason?
Thank you! There are plenty of jQuery table of contents plugins that could be added to IPython notebook (viewer), but I don't know how stable the #fragment-identifier links would be. the most worthwhile approach would probablybbe auto-slugifying text content of the header tags as #url-fragment-identifiers... Just starting at #0 or #1 would hardly be permalinks if/when additional headers/sections are added.
workon is defined by virtualenvwrapper.sh, which can be sourced in from .bashrc or .profile.
$ type workon
Here's a similar function called we.
http://en.wikipedia.org/wiki/Sentience
http://en.wikipedia.org/wiki/Suffering#Religion
http://en.wikipedia.org/wiki/Sapience#Sapience
http://en.wikipedia.org/wiki/Accountability
http://en.wikipedia.org/wiki/Externality
http://en.wikipedia.org/wiki/Enlightened_self-interest
A final point that might seem off at a tangent that I feel needs to be made is that none of the linked data we consume can ever really be said to be consumed directly anyway; we relate to HTTP via web caches, we search data in our triplestores using indexing technologies
We can consume RDF graphs over HTTP REST (LDP) and/or SPARQL, which can query multiple federated triple stores.
human-interfaces
... Do you think that localized natural language sentences are more approachable from a UXD perspective?
These relevant standards for Linked Data may help with your use case:
There are a few ways /r/IPython can support a doctesting workflow:
As a @test decorator in an IPython Notebook and/or %doctest_mode in an IPython REPL and/or as an inline Sphinx ReStructuredText Directive with syntax highlighting.
Merge with Distribute -- Setuptools Documentation
https://en.wikipedia.org/wiki/Category:Computer_science
https://en.wikipedia.org/wiki/Category:Computing-related_lists
https://en.wikipedia.org/wiki/Outline_of_computer_science
http://www.class-central.com/stream/cs
https://en.wikipedia.org/wiki/Outline_of_computer_engineering
https://en.wikipedia.org/wiki/Outline_of_computer_science#Computer_architecture
http://www.reddit.com/r/compsci/comments/1hh1en/online_beginner_course_in_computer_architecture/
Paths and Graphs
https://en.wikipedia.org/wiki/Path_(graph_theory)
https://en.wikipedia.org/wiki/URI
https://tools.ietf.org/html/rfc3986
http://www.reddit.com/r/compsci/comments/19xq7f/recommendations_for_graph_algorithm_books/#c8xw5fj
http://www.w3.org/TR/skos-primer/#secrel
Math
Practically
http://www.reddit.com/r/Python/comments/1eboql/python_website_tuts_that_dont_use_django/#c9yxl8w
You can search previous, current, and future MOOC courses with Class Central: http://www.class-central.com/search?q=computer%20architecture
How does CVD compare to https://en.wikipedia.org/wiki/Graphene#Redox ?
Graphene oxide can be reversibly reduced and oxidized using electrical stimulus. Controlled reduction and oxidation in two-terminal devices containing multilayer graphene oxide films are shown to result in switching between partially reduced graphene oxide and graphene, a process that modifies the electronic and optical properties. Oxidation and reduction are also shown to be related to resistive switching
If you need to do this, put the UTF-8 declaration at the beginning so that python will read your file properly.
PEP 263: Defining Python Source Code Encodings
# -*- coding: utf-8 -*-
The encodings you need to know about:
When you properly internationalize your codebase, all your human-readable text should come from translation files. You may see code like 'tr("What is your name?")', which will look up the appropriate translation of "What is your name?". Note: It's not unicode you pass to tr() because the user won't see it -- they'll see the translation.
gettext.install adds gettext.gettext as _()Is there a more specific wikipedia article / dbpedia URL than http://en.wikipedia.org/wiki/Grey_relational_analysis ?
Would http://en.wikipedia.org/wiki/Category:Fuzzy_logic be appropriate?
I wish I could #link to your excellent References section. Many of these links would be great for the sidebar.
http://www.reddit.com/r/learnpython/wiki/index is a great place to start.
Additional references:
Strings
Input: External modules tablib and/or pandas (pandas.read_table()) help to abstract and formalize string processing / data munging logic.
Output: str.format and/or string.Template (especially in re: CWE-77 (78,88,89,90))
Top 25
from __future__ import division
try:
import IPython
# IPython()
except ImportError as exc:
# rlwrap
One last thing, is it possible to add an index to an [/r/IPython] notebook? That would be great.
http://ipython.org/ipython-doc/dev/development/ipython_directive.html
https://github.com/ipython/nbconvert#nbconvert-conversion-utilities-for-the-ipython-notebook-format
http://sphinx-doc.org/markup/index.html
Here's a list of Free and Commercial CDN Service Providers.
It is possible to sign changesets with both hg and git. Both rely on network transport security and a Web of Trust.
http://en.wikipedia.org/wiki/Test_automation
There is a W3C WebDriver API specification: http://www.w3.org/TR/webdriver/
http://livereload.readthedocs.org/en/latest/ integrates Python and LiveReload.com
Ghost.py, PhantomJS, and CasperJS all have different approaches.
Cool visualization! Is there any way to get year on a third axis? There are a lot of data visualization tools listed in Is Python a good tool for data visualization?.
When you dereference a URL, an HTTP GET retrieves (pulls) an HTML (or JSON, or [...]) document that is then rendered in the browser. A copy of the HTML page is created and loaded into the browser, which renders the document. Which part of the network transport are you attempting to obviate here?
I am still baffled by unicodedata and stringprep.
How do you feel about passlib.utils.saslprep and stringprep in re: A security hole via unicode usernames?
Interesting article. (Thanks for the preprint links.)
This does seem comprehensive. TIL about utilizing http://jeanphix.me/Ghost.py/#capture for generating HTML5 visualizations, for print.
Is there a way to work with conda packages in configuration management tools like Puppet, Chef, Salt, and Ansible?
[EDIT] src links
Buildout also installs from a local download-cache that can be worked into a package index with an index.html containing URLs with #checksums. I hadn't heard that wheel has this capability. bdist_wheel does look super easy.
PDF over SMTP. There may be a number of print-ready tools already packaged with media-production GNU/Linux distros like Ubuntu Studio , Dream Studio , and/or dyne:bolic, I'm not sure.
schema.org HTML microdata support helps search engines index product metadata directly from the product listing HTML. It might be cool to add an attribute for http://schema.org support to this e-Commerce criteria/feature matrix from django grids..
There are varying levels of support for integration with ERP systems.
PEPs and links to DevOps resources for working with Python Packaging and push/pull deployment: How are python apps deployed to production especially those that are developed in a virtualenv? What are the best practices?
It looks like mirrors b and d are offline and each mirror has a different update latency.
Is there an HTML version? It would be great to be able to link to specific sections of this article about Linked Data with a URL #fragment. (Great article!)
Thank you so much! These are also very helpful:
the metadata format will change to a JSON-based format
PEP 426: Metadata for Python Software Packages 2.0
[EDIT]
http://hg.python.org/peps/file/default/pep-0426/pymeta-schema.json
JSON metadata (pymeta.json, pymeta-dependencies.json) is also generated from setup.py.
PEP 440: Version Identification and Dependency Specification
There was the Setuptools-Distribute merge announcement
There is a graphic in the distribute docs. Pip should validate SSL certs by now.
Compoze is one way to maintain a local package index.
index.html)I am not sure whether these support wheel (PEP 427: The Wheel Binary Package Format 1.0).
There's a great chapter on Python Packaging in The Architecture of Open Source Applications
As a path graph with URLs like http://example.com/path/to/spreadsheet.ext/sheet%20name/A1:B1 ?
http://docs.continuum.io/conda/intro.html manages a stable set of packages
https://pypi.python.org/mirrors
[EDIT]
http://www.pypi-mirrors.org is a good list of mirrors and their statuses.
[EDIT]
What about Anaconda Accelerate w/ NumbaPro for Python-to-GPU compiling?
I am a web developer who works with information systems.
"Here are alot of Python jobs"
There are alot of Java jobs too.
It is much easier to help when someone has shared links to which resources they have not yet found their answer from.
https://developers.google.com/gdata/
https://code.google.com/p/gdata-python-client/
https://pypi.python.org/pypi/gdata/
https://code.google.com/p/googlecl/ *
https://developers.google.com/gdata/articles/python_client_lib
Did any of these help?
The sympy docs (e.g. http://docs.sympy.org/0.7.2/modules/core.html ) are written in Sphinx with some sort of a "Run code block in SymPy Live" function that looks alot like /r/IPython notebook.
Here's a lecture / tutorial in IPython notebook viewer (nbviewer.ipython.org).
From http://redd.it/1dl8wc * , you might check out:
It would be neat to be able to extract a dependency graph from the (unnamed-) variables in a spreadsheet.
That, I will remember.
Which github page?
re: downvoter: Do you not understand how supercomputing resource extrapolations conducted with ensemble learning are relevant to automating data analysis and avoiding bias?
The Python installation tool utilized to install different versions of Anaconda and component packages is called conda. pythonbrew in combination with virtualenvwrapper is also great.
When iterating through a dict or a defaultdict, the key order is determined by https://en.wikipedia.org/wiki/Open_addressing and a hashing seed determined by PYTHONHASHSEED. python -R randomizes PYTHONHASHSEED at startup. There are cases when (especially for (doc-) testing and distributed programs) it makes sense to manually set the value of PYHTHONHASHSEED.
_dict = dict(one='one', two='two')
_dict = defaultdict(one='one', two='two')
[key for key in _dict] ## `__iter__`, `Mapping`, `MutableMapping`
[(k,v) for (k,v) in _dict.items()] ## `ItemsView`
[(k,v) for (k,v) in _dict.iteritems()] ## _dict.items() in Python 3
[(k,v) for (k,v) in _dict.keys()] ## KeysView
[(k,v) for (k,v) in _dict.iterkeys()] ## _dict.keys() in Python 3
[(k,v) for (k,v) in _dict.values()] ## `ValuesView`
[(k,v) for (k,v) in _dict.itervalues()] ## _dict.values() in Python 3
To implement a structure with a similar interface, there are:
collections.Mappingcollections.MutableMappingcollections.ItemsViewcollections.KeysViewcollections.ValuesView](http://docs.python.org/2/library/collections.html#collections.ValuesView]From http://docs.python.org/dev/using/cmdline.html#cmdoption-R :
See http://www.ocert.org/advisories/ocert-2011-003.html for details.
Also UserDict and DictMixin and Collections Abstract Base Classes
And python -R and PYTHONHASHSEED
As of v2.7, namedtuple._asdict returns an OrderedDict.
http://www.python.org/dev/peps/pep-0008/#prescriptive-naming-conventions
http://google-styleguide.googlecode.com/svn/trunk/pyguide.html#Naming
http://github.com/numpy/numpy/blob/master/doc/HOWTO_DOCUMENT.rst.txt#overview
[EDIT] These are some best practices for Python variable naming and documentation.
Is it possible to yield graphene from carbon dioxide emissions?
http://en.wikipedia.org/wiki/List_of_countries_by_carbon_dioxide_emissions
http://en.wikipedia.org/wiki/List_of_U.S._states_by_carbon_dioxide_emissions
It would be great if this (and/or the OP) were listed in the Python standard library itertools recipes. These links are to the rendered and source versions of the docs for the itertools module in Python 2 and 3.
Programmers, in languages like C, are prone to error regarding not cleaning up their resources. You might check out the Rust language.
http://static.rust-lang.org/doc/tutorial.html#destructors
http://static.rust-lang.org/doc/rust.html#unsafe-functions
TLDR fast paths are frequently sub-optimal from a security perspective.
Are you familiar with the concept of code coverage?
Which part of the sidebar do you feel is relevant to this question?
From https://github.com/spotify/luigi/blob/master/README.md#target :
Broadly speaking, the Target class corresponds to a file on a disk. Or a file on HDFS. Or some kind of a checkpoint, like an entry in a database. Actually, the only method that Targets have to implement is the exists method which returns True if and only if the Target exists.
README.md mentions writing to Cassandra. It must be possible to write to a database or something like fs or filelike. It would be neat to integrate with spark (docs) and/or shark.
Java Courses
http://ureddit.com/category/23442/computer-science
http://www.class-central.com/search?q=java
Online Tests
search("java online {test, quiz, exercise}")
No worries. You might search for github issues containing ARMA and/or ARIMA. If there's not one already and you can share a set a reference data, you could create a new issue for the statsmodels project team.
So click Edit and send a pull request.
** Tip #1: most folks with windows opt for a virtual installation of linux because it's easier to work with python from the commandline.
It looks like the directory containing the Python executable is not included in your PATH. Here's a relevant answer from stackoverflow
/r/learnpython is great (http://www.reddit.com/r/learnpython/wiki/index).
** Tip #2: you can forgo all the installation use a cloud hosted version of python instead
https://www.wakari.io is a hosted/cloud version of /r/IPython with the components from Anaconda already installed.
Here's a gallery of interesting IPython notebooks and also, this: https://github.com/jrjohansson/scientific-python-lectures#lectures-on-scientific-computing-with-python
The links in the comments for these questions may also be helpful:
Help: Tips on starting up a coders club at the local library
Seeking advice for introducing IPython in high school setting.
Installing Python, IPython, [...]
For the web, I find it easier to get the data into JSON and then apply whichever Javascript visualization libraries to the (escaped) JSON data.
Saving for print is just so easy with Matplotlib where figsize and dpi can be specified directly. Matplotlib also ties in with Sphinx for ReStructuredText documentation.
Pandas has native support for matplotlib (DataFrame.plot(), DataFrame.boxplot(), Series.plot(), pandas.tools.plotting)
There is a new HTML5 Canvas backend for matplotlib: http://matplotlib.org/users/whats_new.html#html5-canvas-backend (https://code.google.com/p/mplh5canvas/)
It would be great if there was an IPython extension.
https://github.com/mher/chartkick.py creates charts with Google Charts and Highcharts.
EasyViz has an API similar to Matplotlib and bindings to "Gnuplot, Matplotlib, Grace, Veusz, Pmw.Blt.Graph, PyX, Matlab, VTK, VisIt, OpenDX".
Transparent references between objects without the need for reference swizzling.
Does ZODB maintain referential integrity and/or propagation constraints so as not to leave dangling pointers?
http://en.wikipedia.org/wiki/Relational_database#Index
Repoze.catalog is derived from zope.app.catalog and also depends on zope.index.
Lispy HTML! This may be a helpful approach to Adding microdata for the schema.org types.
From webhelpers, webhelpers.html.builder utilizes MarkupSafe to do something similar.
https://en.wikipedia.org/wiki/Category:Natural_language_processing
https://en.wikipedia.org/wiki/Sentiment_analysis
... Two separate things: text sentiment mining and "have the computer understand"
Easy / Practical / Helping Others / Creating Meaning
The Architecture of Open Source Applications books are tremendous resources for learning about successful approaches to open source development.
... Read, Code, Test, Write Tests, Write Documentation
RFC 3454: Preparation of Internationalized Strings ("stringprep") defines a standard for profiles for canonicalization/disambiguation/comparison.
Python has included stringprep since 2.3: http://docs.python.org/2/library/stringprep.html
String prep in Python: http://docs.python.org/2/library/stringprep.html
These are great! It looks like they're on tutorial set version 4.0:
http://en.wikipedia.org/wiki/Punycode should just be ALL CAPS.
https://en.wikipedia.org/wiki/Command-line_interface
https://en.wikipedia.org/wiki/Command-line_argument_parsing#Python
https://en.wikipedia.org/wiki/Python_(programming_language)
Automated testing is much easier when there is a main function.
Minimally, in Unix style:
def main():
'''Prints "Hello World!"'''
print("Hello world!")
return 0
if __name__ == '__main__':
import sys
sys.exit(main())
From the list of PyPi Trove Classifiers:
Environment :: Console
An XML sitemap may help search engines index your site. There are a number of WordPress plugins for generating a sitemap and/or a robots.txt.
http://google.com/webmasters/tools/ can help to optimize a site for Google and other search engines.
Site performance may also have an impact. http://developer.yahoo.com/yslow/ can help to optimize page load times.
Cambridge Semantics' free Semantic University is a great resource for learning about Linked Data.
The "What is Linked Data" video
[applies] whimsical, hand-drawn pieces of paper and hand gestures to introduce the subject of Linked Data for non-technical people.
Good call. There are so many great open source software hosting services; github may be a representative sample.
you can indent four spaces for monospace. http://www.reddit.com/wiki/commenting
... I suppose that the appropriate levels of coupling and cohesion#Coupling_versus_Cohesion) are debatable.
In Java, standard practice is to namespace (deeply) below a reversed FQDN.
I suppose the same could be done with Python (which has setup tools entrypoints and stevedore)
Like rdfs:Class and rdf:Property, where each rdf:Property has an rdfs:domain and an rdfs:range
http://en.wikipedia.org/wiki/Eigenclass_model#Ontological_structure_of_.CF.B5
Fixture issue #36 and Fixture issue #43 added support for serializing a list to a ListProperty.
Whether a OneToMany field has more lock contention than a ManyToMany table is implementation dependent.
In the spirit of Linked Data, here are WorldCat links to (what I believe are) the latest versions of the referenced book titles:
Type for representing (Unicode) textual data. This is
unicode()in Python 2 andstrin Python 3.
Here are the docs on writing IPython extensions.
This is not how it works with PHP. With PHP, the webserver is configured to execute the PHP interpreter when a URL ending with .php or .phps is requested. FastCGI can be a bit different. "It just works" is not accurate: it works because the web server is preconfigured to spawn processes based on URL path extension suffixes. mod_python is not a recommended deployment pattern.
Due to the fact that [...]
What does WSGI have to do with HUP-ing an app server when a file modification time changes?
app.yaml is really simple. Phusion Passenger is as simple as mod_python ever was. There are references describing the advantages and disadvantages of various Apache process models.
http://www.reddit.com/r/Python/comments/1fl8c5/self_hosted_python_web_hosting_platforms/
http://www.reddit.com/r/Python/comments/1bx3vj/how_are_python_apps_deployed_to_production/c9b5tea
http://learnpythonthehardway.org/book/ex46.html
http://docs.python-guide.org/en/latest/writing/structure.html
For comparative examples of a simple app with various web frameworks, I usually refer to https://github.com/seedifferently/the-great-web-framework-shootout and https://github.com/tastejs/todomvc
Pyramid has migrated from PasteScript (paster create) with 1.0 to pcreate with latest ... There are lots of ZopeSkel, Paster, Templer, and Pyramid create templates hosted by PyPi.
http://scipy-lectures.github.io/intro/language/reusing_code.html
Assuming this is being downvoted because it is perceived to be unrelated to "What single-dispatch generic functions mean for you"; Mixins and abstract base classes frequently obviate the need for single-dispatch generic functions. Rather than having code conditional on isinstance, clases with Mixins are expected to have the appropriate behaviors before they are called.
Additionally, Mixins can add complexity both to the Python MRO and static analysis.
Inference: adding support for single-dispatch generic functions will probably lead to an increase in attempts to re-implement something similar to UserDict and collections.abc; which is both counter-productive and unnecessary.
I do apologize if this appears to be hijacking this thread: my intent is to share the resources I am aware of in order to increase shared comprehension around these approaches to dynamic programming.
All the time. Comparable with feature patches. Advantage: no merge revisions. Disadvantage: Less granular bisection.
seeAlso:
Great article, btw
This is a strange interpretation of http://en.wikipedia.org/wiki/Duck_typing#In_Python
A function has a domain and a range.
I didn't ask for this! I choose not to add this unnecessarily confusing complexity to my code OR application. Who wants to edit the style guide!?
It even says in the PEP 20 - THE ZEN OF PYTHON
Explicit is better than implicit.
Simple is better than complex.
...
Namespaces are one honking great idea -- let's do more of those!
How does this work with http://andreacensi.github.io/contracts/ and/or http://www.python.org/dev/peps/pep-3107/ ?
An example of where single-dispatch and/or interfaces and adapters could be utilized; with different syntax and/or performance characteristics.
[EDIT] Also an example of subclassing a collections.namedtuple with an ._asdict.
Awesome.
Schema.org (schema) has two RDFS Classes that may be useful here: schema.org/SoftwareApplication and schema.org/Code.
It would be great if schema.org had properties for IRC: e.g. schema:IRChan and a schema:IRCWebClient.
There's DOAP [schema] (examples: Turtle/N3, JSON-LD)
A doap:mailing-list could have a URI starting with irc://, ircs://, irc6://.
There could be an example:IRChan and example:IRCWebClientURL with a
example:IRChan a rdfs:Property;
rdfs:label "IRC Channel"@en;
rdfs:comment "An IRC Channel"@en;
rdfs:domain [ a owl:Class; owl:unionOf (doap:Project schema:SoftwareApplication) ];
rdfs:range schema:Thing ;
#rdfs:range rdfs:Resource ;
It's easy enough to include some Turtle Triples in a <pre> tag, but some sort of a project metadata Microdata generator with a structured property for "IRChan" and "IRCWebClientURL" would be really cool.
Awesome! So simple!
fs and/or pandas HDF5 PyTables support would probably be overkill here.
Incorporating TDD and Agile
Fault Coverage -> Code Coverage
Lean Manufacturing -> Lean Software Development
Agile Testing (Category:Agile_software_development *)
Testing Django applications
Most web applications -- Django included -- can be tested with Ghost.py.
Testing and Django (PyCon 2012) is really helpful.
Tastypie RESTful testing support is fairly comprehensive.
Django Debug Toolbar is always helpful.
qnew creates a new patch (hg help qnew) with Mercurial Queues (hg mq) ... which are also supported by the TortoiseHg GUI
So this is faster than zope.interface.adapter.AdapterRegistry? *
There is this ideal separation between presentation and content -- or between data and design -- that seems to allow designers to do what they do best.
Not because someone has fooled them into thinking that there is a right brain left brain schism between graphic designers, web designers, web developers, web engineers, programmers; but maybe because math is universal, and design tastes are changing.
For example, Django's template documentation distinguishes between designers and programmers.
I've had the opportunity to work with a number of packages of variously portable graphic design suites.
If you are trying to share data in an impactful way in the web world, I would point you to things like:
If you would like people to share your data, do it without all the extra markup.
If you want people to look at your data, make it look good.
... You might check out CSS3 Gradients.
One of the most helpful resources for learning basic and scientific Python ever created.
https://pypi.python.org/pypi/scikits-image utilizes SciPy (and thus NumPy) for digital image processing.
You can lookup, suggest, and rate ontology namespace mappings with http://prefix.cc/
ghost.py has many of the features of pyphantomjs. Both require PyQt4 and/or PySide; and WebKit.
IPython notebook is built with Tornado and supports a few different security features.
These auth(z) and REST Security cheat sheets might be useful.
From http://dataliberate.com/2012/06/oclc-worldcat-linked-data-release-significant-in-many-ways/ (OP):
- [For RDF/XML specify http://www.worldcat.org/oclc/41266045.rdf]
- For JSON specify http://www.worldcat.org/oclc/41266045.jsonld
- For turtle specify http://www.worldcat.org/oclc/41266045.ttl
- For triples specify http://www.worldcat.org/oclc/41266045.nt
EDIT: Monospace ASCII quotes
curl -L -H "Accept: application/rdf+xml" http://www.worldcat.org/oclc/41266045curl -L -H "Accept: application/ld+json" http://www.worldcat.org/oclc/41266045curl -L -H "Accept: text/turtle" http://www.worldcat.org/oclc/41266045curl -L -H "Accept: text/plain" http://www.worldcat.org/oclc/41266045
you have to choose between python 3 and Windows support.
Anaconda for Python 3.3 includes PySide for GUI development. (here)
https://en.wikipedia.org/wiki/Qt_(framework) is a cross platform framework with support for Mac, Windows, Linux, and now Android.
Python 3 is not obsolete. Are you reporting a specific bug regarding a specific procedure? You may be more likely to find a solution if you share the inputs and outputs that are not going as you would like.
Here are some suggestions for reporting bugs, in general: https://help.ubuntu.com/community/ReportingBugs
Here are some resources on porting to Python 3, in general:
From http://wiki.python.org/moin/Python2orPython3 :
For creating GUI applications Python 3 already comes with Tkinter, and has been > supported by PyQt4 almost from the day Python 3 was released; PySide added Python 3 support in 2011. GTK+ GUIs can be created with PyGObject which supports Python 3 and is the successor to PyGtk.
import datetime, operator
_now = lambda: operator.attrgetter('year','month','day')(datetime.datetime.now())
assert datetime.date(*_now()) == datetime.date.today()
http://docs.python.org/2/library/datetime.html#datetime.date.fromordinal :
import datetime
def _today(self=None):
"""
:returns: current datetime, rounded to 0000
:rtype: datetime.datetime
"""
d=datetime.datetime.now()
return d.fromordinal(d.toordinal())
From https://code.google.com/p/pyiso8601/ # iso8601.py (pypi):
>>> import iso8601
>>> iso8601.parse_date("2007-06-20T12:34:40+03:00")
datetime.datetime(2007, 6, 20, 12, 34, 40, tzinfo=<FixedOffset '+03:00'>)
>>> iso8601.parse_date("2007-06-20T12:34:40Z")
datetime.datetime(2007, 6, 20, 12, 34, 40, tzinfo=<iso8601.iso8601.Utc object at 0x100ebf0>)
pyiso8601 naievely assumes that the timezone is UTC:
In [1]: %doctest_mode
>>> import datetime, iso8601
>>> d = datetime.datetime.now()
>>> d2 = iso8601.parse_date(d.isoformat())
>>> d, d2
(datetime.datetime(2013, 6, 3, 16, 25, 49, 621070),
datetime.datetime(2013, 6, 3, 16, 25, 49, 621070, tzinfo=<iso8601.iso8601.Utc object at 0x9295f0c>))
>>> assert d == d2
Traceback (most recent call last):
File "<ipython-input-23-2abfcc7ac10d>", line 1, in <module>
assert d == d2
TypeError: can't compare offset-naive and offset-aware datetimes #'
>>> d.tzinfo, d.tzname()
(None, None)
>>> d2.tzinfo, d2.tzname()
(<iso8601.iso8601.Utc object at 0x9295f0c>, 'UTC')
awesome. thanks!
This should probably be in the docs for IPython.core.display and/or somewhere in the narrative documentation?
EDIT: such as here
jinja2.escape and jinja2.Markup are both included in jinja2, which is an install_requires for IPython notebook.
The standard library function to copy over __name__ and __doc__ is functools.wraps:
http://docs.python.org/2/library/functools.html#functools.wraps
http://docs.python.org/3/library/functools.html#functools.wraps
http://wiki.python.org/moin/DependencyInjectionPattern hasn't been updated in quite awhile.
Cool!
Tin Can API (github) is one current standard for learning activities.
Integration with edX through code.edx.org (github) could be neat, too.
Great idea. Is there a / do you make a stand that would make this easier on the hands? What URL can the app POST to?
https://httpd.apache.org/docs/current/mod/mod_log_config.html
Is it possible that a logged value might contain something like "; ex:also <http://example.org/safety>?
It can be easier to view RDF graphs like OWL ontologies as Turtle. To transform an .owl file to a .ttl with raptor (deb:raptor2-utils, yum:raptor2):
rapper http://schema.org/docs/schemaorg.owl -o turtle
rapper http://mappings.dbpedia.org/server/ontology/dbpedia.owl -o turtle
wget http://schema.rdfs.org/all.ttl
OWL and SPARQL
For OWL ontologies:
<ontology/url> a owl:Ontology;
So the SPARQL query for an owl:Ontology looks like:
SELECT DISTINCT ?s WHERE { ?s a owl:Ontology } LIMIT 10
DBpedia
In terms of mapping to dbpedia:
dbpedia:Ontology_(information_science)dbpedia:Category:Ontology_(information_science)Wikipedia links:
OpenCyc links:
http://www.w3.org/wiki/Lists_of_ontologies could be more comprehensive.
W3C wiki links:
Schema.org:
Adapted from this answer
Schema.org is an ontology derived from a number of existing ontologies like "FOAF, Good Relations and OpenCyc".
Schema.org types extend http://schema.org/Thing . For example, http://schema.org/WebPage extends http://schema.org/CreativeWork extends http://schema.org/Thing ; meaning that http://schema.org/WebPage has properties from schema:Thing (name, url, description, ...) , schema:CreativeWork (author, award, comment, ...), and schema:WebPage.
Schema.org Type Hierarchy on one HTML page
http://schema.rdfs.org links to the http://schema.org ontologies as RDF/XML, N-triples, Turtle, OWL, JSON and CSV.
from http://schema.rdfs.org/all.ttl (turtle RDF syntax):
<http://schema.rdfs.org/all> a owl:Ontology;
dct:title "The schema.org terms in RDFS+OWL"@en;
dct:description "This is a conversion of the terms defined at schema.org to RDFS and OWL."@en;
foaf:page <http://schema.rdfs.org/>;
rdfs:seeAlso <http://schema.org/>;
rdfs:seeAlso <http://github.com/mhausenblas/schema-org-rdf>;
dct:hasFormat <http://schema.rdfs.org/all.ttl>;
dct:hasFormat <http://schema.rdfs.org/all.rdf>;
dct:hasFormat <http://schema.rdfs.org/all.nt>;
dct:hasFormat <http://schema.rdfs.org/all.json>;
dct:hasFormat [
dct:hasPart <http://schema.rdfs.org/all-classes.csv>;
dct:hasPart <http://schema.rdfs.org/all-properties.csv>;
];
dct:source <http://schema.org/>;
dct:license <http://schema.org/docs/terms.html>;
dct:valid "2013-05-31"^^xsd:date;
A suggested namespace prefix for http://schema.org is schema:
A http://schema.org/WebPage as turtle RDF syntax
<http://semanticweb.com> a schema:WebPage;
schema:name "semanticweb.com"@en;
schema:url <http://semanticweb.com>;
http://schema.org/Person may be [mostly] appropriate for your use case. (about schema.org)
http://www.w3.org/wiki/Lists_of_ontologies could be more comprehensive.
From https://en.wikipedia.org/wiki/DAML%2BOIL :
[DAML+OIL] was superseded by Web Ontology Language (OWL)
FTFY: "You Will Need" -> "I have heard of" / "I like"
Cool tree graph. Is there a way to export mindmaps to RDF, maybe with DOAP or just http://schema.org/SoftwareApplication ?
compoze generates package indices.
[EDIT] Is there a one-shot way to generate a package index from the output of something like pip freeze or similar?
https://en.wikipedia.org/wiki/List_of_collaborative_software#Open_source_software
Open standards and formats like SVG
Is python a good tool for data visualisation?
http://wiki.inkscape.org/wiki/index.php/Python_modules_for_extensions
http://www.reddit.com/r/IPython/comments/1f8rsr/playing_with_svg_graphics_in_ipython/
https://en.wikipedia.org/wiki/Distributed_revision_control#Open_systems
www.w3.org/TR/ldp/ "W3C Linked Data Platform 1.0"@en
Yes; there are some ways to achieve (what I guess are) similar objectives with the linked resources.
[EDIT] But where do I specify the column headers, units, and datatypes?
One way to share structured data in HTML5 is with Microdata.
With Javascript, there are structured formats like JSON-LD and JSON-stat that can be rendered as HTML tables and paged through.
vincent.ipynb IPython extensions for d3js and vega.jsvincent examples/vincent_ipython_nb.ipynbd3.svgpandas.core.frame.DataFrame:to_htmlpandas.core.format (SeriesFormatter, TableFormatter, DataFrameFormatter, HTMLFormatter)pandas.tools.plottingipython extensions docsipython sympyprinting extensionipython.core.displayschema.org: Thing > CreativeWork > SoftwareApplication [ -> MobileApplication , WebApplication ]
While I can visualize an adjacency list of packages and version dependencies, it would be great to reference or visually see a graph of *_requires in the docs.
There are a lot of ways to build a dependency graph from PEP 426 Metadata for Python Software Packages 2.0 and PEP 440 Version Identification and Dependency Specification (JSON) metadata
You could write a simple web application to return the PNG and/or some HTML over HTTP (over SSH). I'm not sure about rate limiting on the Pi. Django is great; bottle.py is really easy. http://www.reddit.com/r/Python/comments/1eboql/python_website_tuts_that_dont_use_django/c9yxl8w
anyconfig will load multiple JSON, YAML, INI and XML files into MergeableDict(s) with __getitem__.
pyramid.config (docs) is also great.
There's SPARQL, already-parsed data from sites like quandl and data from the new Data.gov CKAN catalog (CKAN API docs)
Data can be included in a <script> tag. (wrapped in a <![CDATA[ ... ]]> tag)
http://www.w3.org/TR/html5/syntax.html#cdata-sections
Data could also be munged into tables from HTML Microdata stored alongside the DOM
Related question: http://www.reddit.com/r/html5/comments/y68zf/is_it_possible_to_create_an_completely_offline/
from six.moves import configparserPEP 426 is the current standard for declaring package metadata; including dependencies.
Python packages declare package metadata in setup.py files. (example setup.py)
setup(
name="Project-A",
install_requires=['pyramid',],
tests_require=['flake8', 'ipdb'],
extras_require = {
'PDF': [],
'reST': ["docutils>=0.3"],
}
)
There are a number of tools for exploring Python package metadata.
I disagree. ggplot2 is cool; and I think that matplotlib is one great way to visualize data using Python.
Do you have any suggestions or alternatives?
I remember reading about http://en.wikipedia.org/wiki/Slingshot_(water_vapor_distillation_system) (no relation) and thinking "how can I donate to this?"
From http://www.reddit.com/r/water/comments/1ewoc2/how_to_compare_different_water_governance_systems/ :
http://www.globalwaterforum.org/2013/05/24/how-should-we-compare/
All the time. From https://help.ubuntu.com/community/CompositeManager/ConfiguringCompiz :
Make active window translucent/opaque (built-in)
Alt + mouse wheel up/down
Make active window translucent/opaque (with the opacity plugin)
Ctrl + Shift + Scroll, or right-click the window's title bar and select Opacity (seems to be absent in current compiz cvs.)
owl:sameAs Considered Harmful to Provenance helped me understand the need to be careful linking things with owl:sameAs.
From PEP 20 - The Zen of Python:
Beautiful is better than ugly.
Explicit is better than implicit.
Simple is better than complex.
Complex is better than complicated.
Flat is better than nested.
Sparse is better than dense.
Readability counts.
Special cases aren't special enough to break the rules.
Although practicality beats purity.
Errors should never pass silently.
Unless explicitly silenced.
In the face of ambiguity, refuse the temptation to guess.
There should be one-- and preferably only one --obvious way to do it.
Although that way may not be obvious at first unless you're Dutch.
Now is better than never.
Although never is often better than *right* now.
If the implementation is hard to explain, it's a bad idea.
If the implementation is easy to explain, it may be a good idea.
Namespaces are one honking great idea -- let's do more of those!
See also:
import this
I searched for "python language wallpaper" and found quite a few.
Pythonistas appreciate good design, which is why we (IMHO) defer templates to designers: http://en.wikipedia.org/wiki/Separation_of_presentation_and_content
RPython and asm.js are both low-level restricted subsets of language specifications that enable more optimal compilation to machine instructions. How are they different?
Is asm.js a similar approach to a similar problem?
Same. If these wiki pages contained structured data, we could easily create a feature comparison matrix. SPARQL, Linked Data, and Microdata_(HTML) could make that a bit easier to do.
Are there differences or similarities between Science, Information Science and Machine Learning?
the golden standard [...]
Most DVCS systems (like git) have been built by people satisfied with the features of standard files and filesystems. DVCS support cross-platform portability by implementing checksums, history, branching and merging mostly independent of the operating system or filesystem.
Lots of people utilize git for development. Some people and some hosting services also utilize git for deployment. Git and Hg have no notion of package dependencies or setup.py. Neither Git nor Hg do rm ./*.pyc before pulling or updating.
Where are the zip files, the eggs, and the wheels?
Is that before packaging or after packaging?
http://www.pyinstaller.org/ doesn't even require an interpreter to be installed.
If you need GUI integration, it would also be great to generate a folder full of packages and an index.html file -- with checksums -- that can be served and installed locally or remotely.
Served locally:
mkdir -p www/local_packages && cd www
python -m SimpleHTTPServer 8888 .
easy_install is part of distribute and setuptools, which are not included with distutils in the standard library:
easy_install --index-url=http://localhost:8888/local_packages
easy_install --find-links=http://localhost:8888/local_packages
If you change your code but have no compiling stage, how do you make sure you didn't break anything?
Testing and static analysis (flake8).
http://www.reddit.com/r/Python/comments/1drv59/getting_started_with_automated_testing/c9tfxgd
That's just like, your opinion, man. Pardon the [topic-] relevant resources; OP asked a question and we helped the community.
Python has also had zip files with manifests (packages) for a number of years. I think it's the [not always necessary; eg. PyPy] compilation step that adds complexity in exchange for performance optimizations.
And all of these things are external and optional.
zope.interface is external, optional, and the docs are great.
The Exception base class is included in the standard library. It is (a) not designed for message passing; (b) underutilized.
Another problem with these libraries is that they introduce a lot of code to enable non-idiomatic conventions. You end up losing much of the succinctness that people love so much about python.
Documentation
param, type, raises, returns, rtype)Args, Returns, Raises)Less lines of code is less chance for error.
For me, writing succinct code is more about reducing the chance for programmer fault. It goes without saying that there is much value to leveraged and maintenance costs to be reduced by utilizing already-implemented patterns; hence frameworks.
Scala is really cool in this respect.
OP was about Pythonic succintness. Templates and generics are cool.
Python has isinstance, but hasattr is much preferred: http://www.canonical.org/~kragen/isinstance/
However, when you've crossed the paging threshold for your mental working space, you need constraints to remind you of how things work. Things that Python programmers often dismiss, like static argument types, interfaces, etc, help keep these constraints in place to keep you from inventing strange new error conditions.
Assuming the destination has installed [the same version of] java, that's pretty neat.
Every place is different with regards to managing software configuration and dependencies.
You can accomplish something similar (with zero XML) using distutils and a setup.py:
python setup.py bdist
python setup.py bdist doesn't include "everything ever needed" unless those libraries are placed in a ./lib directory within the package under test. Understand that bundling something like OpenSSL -- which is upgraded fairly frequently -- might not be a good decision, depending on the production context.
To build a source distribution (a zip or tar archive containing no bytecode), the command is:
python setup.py sdist
If you prefer to use system packaging there are also:
python setup.py bdist_rpm
python setup.py bdist_wininst
python setup.py bdist_msi
https://pypi.python.org/pypi/stdeb enables:
python setup.py sdist_dsc
python setup.py bdist_deb
wheel adds a bdist_wheel command that can group platform-specific and platform-agnostic packages into a signed zip file:
python setup.py bdist_wheel
buildout (http://github.com/buildout/buildout) is more similar to mvn than pip.
pip freeze will list which packages and versions are contained within the configured sys.path:
pip freeze [-l] | tee requirements.txt
Examples of setup.py and tox.ini files:
[EDIT]
If you separate your data from your code, you could update your image once and spawn that?
http://virtualenvwrapper.readthedocs.org/en/latest/command_ref.html#add2virtualenv
type add2virtualenv
type toggleglobalsitepackages
I'm sure there's a wonderful packaging solution
I sure hope one is at least being created as we speak.
[EDIT]
http://pythonhosted.org/distlib/tutorial.html#using-the-wheel-api
You make some great points. This is a mostly a continuation from this thread with a few more links.
- Python is arguably more widespread [...]
Pre-packaged distributions like Continuum Anaconda and Enthought Canopy make managing cross-platform installations on Linux, OSX, and Windows very easy.
- The special functions (
__add__etc) makes it easy to make beautiful container classes
- Reading a textfile is easy, not painful
- Easy to browse the documentation and use a new API.
- The speed is not a problem [...]
Speed of bug development, or speed of execution?
[Vendor Support]
- Use IPython & show them autocomplete & embedded images
/r/IPython notebook may be a good starting point for existing programmers. As would
def main():
'''Prints "Hello World!"'''
print("Hello world!")
return 0
if __name__ == '__main__':
import sys
sys.exit(main())
- Use requests to connect to a service using HTTPS, ignoring any HTTPS errors
- Returning multiple values. This example maybe useful
This returns a list() created by a list comprehension. It could also return a generator expression by replacing the enclosing square brackets [] with parentheses ().
- Function & class decorators
- Django admin
- Indentation
- No IDEs for Python
It is possible to learn and program in Python without a tools dependency.
- Python is slower than Java
- Python is open-source, and open-source is not supported
- Open-source is not secure
- Interpreted means that they can "View Source" and see my source (Yes I heard this one)
- It's not object-oriented
- It's not object-oriented enough (no private/protected)
Read-only properties can be accomplished by annotating a getter function with @property and not defining a setter.
@Wed May 22 22:36:57 2013 UTC
http://www.reddit.com/message/messages/v2k95 :
you have been banned from posting to /r/Omaha: Omaha.
Policy
From http://reddit.com/r/omaha/about/sidebar :
"Avoid posting duplicate topics on similar events and/or articles."
What about that statement indicates that the result of a respectful duplicate dispute resolution process would result in being banned from the /r/Omaha subreddit?
Topicality
Please consider your language in our communications.
In regards to internet marketing, from https://en.wikipedia.org/wiki/Web_traffic :
The majority of website traffic is driven by the search engines.
re: ad-hominem
I have subsequently been banned from posting to /r/Omaha .
What sort of behavioral and social transparency and accountability are involved in making the decision to ban or un-ban an individual over a single infraction 'solved' by removing the errant duplicate post?
This hardly seems welcoming.
This is a post about a local charitable fundraising effort that is a cause marketing campaign in which internet marketing is being utilized to help people and animals around the metro area.
Good Anchor text and Clean URLs may help get charitable resources to these important causes.
I would consider my definition of trolling sufficient. I do not consider this to be trolling.
You mentioned your understanding of the reddit search functionality. I linked to the reddit search functionality in order to clarify our discussion.
http://www.reddit.com/r/Omaha/comments/1euxgi/omahagives24org_today_522_give_to_a_cause_you/ca3zzdc links to http://redd.it/1et85p , except the URL is unobfuscated, so I am likely to click on it.
http://www.reddit.com/wiki/reddiquette
Use an "Innocent until proven guilty" mentality.
When you search for "omahagives24.org" on reddit, what headline do you find?
I agree.
Could you link to the policies you are referencing?
The previous submission, linked as "See also:", is wonderful. https://www.google.com/search?q=writing+headlines
Are you downvoting links to https://omahagives24.org ?
Could you link to the submission you are referring to?
From http://www.reddit.com/wiki/reddiquette :
Search for duplicates before posting. Redundancy posts add nothing new to previous conversations. That said, sometimes bad timing, a bad title, or just plain bad luck can cause an interesting story to fail to get noticed. Feel free to post something again if you feel that the earlier posting didn't get the attention it deserved and you think you can do better.
Could you add "OmahaGives24.org" and "TODAY" to the title?
Could you add "omahagives24.org" and "TODAY" to the title?
04:00 PM 05/22/13
$973,318.56 [from] 10,845 gifts
04:10 PM 5/22/13
$2,062,153.37 [from] 11,422 gifts
04:45 5/22/13
$2,101,664.04 [from] 11,973 gifts
http://en.wikipedia.org/wiki/Areas_of_mathematics
http://en.wikipedia.org/wiki/Outline_of_software_engineering#Mathematics_topics
http://en.wikipedia.org/wiki/Category:Information_theory
http://en.wikipedia.org/wiki/Category:Probability_theory
http://en.wikipedia.org/wiki/Category:Number_theory
http://en.wikipedia.org/wiki/Category:Combinatorics
http://en.wikipedia.org/wiki/Matroid#Matroids_from_graph_theory
If you're interested in http://en.wikipedia.org/wiki/Category:Graph_theory , http://www.reddit.com/r/compsci/comments/19xq7f/recommendations_for_graph_algorithm_books/ contains some useful resources.
Similar question: http://www.reddit.com/r/compsci/comments/1dprye/as_a_computer_science_major_would_it_be_more/
It sounds like you are trying to do something like doctests, except more like ipythonnotebooktests.
As an alternative to interleaving IPython notebook code into one python file, you might consider:
Hackish, but what are the values of __import__('sys').args and __file__ when running from within IPython notebook?
[EDIT]
http://en.wikipedia.org/wiki/JSON-LD
To conform to the JSON-LD spec:
Contexts can either be directly embedded into the document or be referenced.
Normative language would be helpful here, so that it is not necessary to special case schema.org.
That could look something like:
"@context": "http://schema.rdfs.org/all.jsonld"
d3 == d3.js == 'Data-Driven Documents'
There is also an autoreload module for /r/IPython :
%autoreload?
%aimport?
The autoreload module does not auto magically make functions idempotent or version the API like /v1/ and /v2/ or /api/201305151700/, though.
Are there differences between these approaches?
I guess I could tag and summarize things with links to a shared, collective lexicon
You can pass a list of columns to
[][*] to select columns in that order. If a column is not contained in the DataFrame, an exception will be raised. Multiple columns can also be set in this manner:
df[['B', 'A']] = df[['A', 'B']]
[*] Where [] is http://docs.python.org/2/library/operator.html#operator.getitem
Open Source Data Analysis tools written in Python, Java, R, Fortran, C, Cython, C++, HTML and Javascript
Similar Comments about
Web frameworks abstract design patterns, architectural patterns and algorithms that web designers and web developers can implement in a standard, maintainable way in order to minimze anti-patterns and technical debt.
Wikipedia links/tags
Learning Computer Science, Web Design and Web Development Online
Python, HTML, CSS, Javascript, and HTTP for Web Development
Related Questions
You could create a folder of symlinks and use add2virtualenv from virtualenvwrapper and/or a .pth configuration file.
From http://docs.python.org/2/library/site.html :
A path configuration file is a file whose name has the form
name.pthand exists in one of the four directories mentioned above; its contents are additional items (one per line) to be added tosys.path. Non-existing items are never added tosys.path, and no check is made that the item refers to a directory rather than a file. No item is added tosys.pathmore than once. Blank lines and lines beginning with # are skipped. Lines starting with import (followed by space or tab) are executed.
In addition to add2virtualenv, there's also a toggleglobalsitepackages command.
type add2virtualenv
type toggleglobalsitepackages
From http://www.cccblog.org/2012/05/23/revisiting-where-the-jobs-are/ :
Computer and mathematical occupations are projected to add 778,300 new jobs between 2010 and 2020, after having added 229,600 new jobs from 2006 to 2010. This represents 22.0 percent growth from 2010 to 2020
(via http://googleresearch.blogspot.com/2013/03/scaling-computer-science-education.html)
I would imagine that computer science would be useful for all of the technologies listed in this http://en.wikipedia.org/wiki/List_of_emerging_technologies
Sorry to hear that. Here's to looking forward to competition in the Omaha Metro broadband market.
After 7 hours of service, was the issue that:
Instead of A1, B2, C3, you could assign a prime to each object and take the product of each list of related objects. Some numbers could be complex; others rational.
These are the speeds for your cable connection?
Do you have any business relation to Cox, beyond subscribing to their services?
From http://www.python.org/dev/peps/pep-0008/#descriptive-naming-styles :
In addition, the following special forms using leading or trailing underscores are recognized (these can generally be combined with any case convention):
_single_leading_underscore: weak "internal use" indicator. E.g.from M import *does not import objects whose name starts with an underscore.
single_trailing_underscore_: used by convention to avoid conflicts with Python keyword, e.g.
Tkinter.Toplevel(master, class_='ClassName')
__double_leading_underscore: when naming a class attribute, invokes name mangling (inside classFooBar,__boobecomes_FooBar__boo; see below).
__double_leading_and_trailing_underscore__: "magic" objects or attributes that live in user-controlled namespaces. E.g. init, import or file. Never invent such names; only use them as documented
http://en.wikipedia.org/wiki/Computational_linguistics
http://en.wikipedia.org/wiki/N-gram
http://en.wikipedia.org/wiki/Tf-idf#See_also
http://en.wikipedia.org/wiki/Analysis_of_variance
http://en.wikipedia.org/wiki/List_of_probability_distributions
http://en.wikipedia.org/wiki/Central_limit_theorem
http://www.class-central.com/search?q=statistics
http://docs.scipy.org/doc/scipy/reference/stats.html
In Python, class variables beginning with two underscores are name mangled:
Conventionally, an instance variable prefixed with a single underscore is an instance variable that should not be modified externally.
Read-only properties can be accomplished by annotating a getter function with @property and not defining a setter.
Similar questions and answers:
http://www.python.org/dev/peps/pep-0008/#descriptive-naming-styles
An example of DOAP: Description of a Project in Turtle RDF Syntax in Reddit code syntax :
<> a doap:Project ;
doap:homepage <https://code.google.com/p/lmf/> ;
doap:programming-language "Java"@en ;
.
I will stop adding value by adding links to relevant content. Are you more concerned about:
Take this Wikipedia-link, it is a link to a disambiguation page with six concepts called "SPIN", none of which have anything to do with the topic at hand. Why would you post this?
There is not a page for SPIN, as in http://spinrdf.org, on Wikipedia. This is the most specific wikipedia reference to the linked spec. Someone should really get on that.
Here you posted 29(!) links, and the OP does not even know what you are talking about.
https://www.google.com/search?q=define%3A"web+friendly+format"
In this topic you posted 12 links--everything from a Wikipedia link to the concept of "semantics" to links to random lines of SQL-code, while you can't/don't even answer my question what all that has to do with semantic web technology.
Is there a better set of criteria for determining what qualifies as semantic http://en.wikipedia.org/wiki/Semantics_(computer_science)#Variations ? Are you able to add anchor text to a link containing a parentheses?
I apologize if you feel that ElasticSearch, built on Solr -- like Marmotta -- is not a / could not be used as / does not have features of a Semantic Web technology.
This topic includes 62(!) links of you, and I do not understand what you are proposing (something about using Schema.org properties for marking up datasets?)
OWL Ontologies from http://www.se-on.org/ :
What I want is a place to store "x has y relationship with z", such that I can later make n-depth queries against it. Further, I want to do it in the most "standard" or "correct" way possible.
You may get a more helpful answer from someone pushing microformats.
EDIT: schema.org also supports microformats
how I searched for information regarding your question
https://github.com/galah-group/galah "An automated grading system geared towards processing computer programming assignments."
http://devstack.org/ "A documented shell script to build complete OpenStack development environments."
How does vCard in RDF work with SPARQCode QR Codes?
http://en.wikipedia.org/wiki/vCard
From http://www.w3.org/TR/vcard-rdf/#Overview [20130502] :
vCard is a specification developed by the IETF for the description of people and organisations. Recently, vCard has been significantly updated to Version 4 as documented in [RFC6350]. Typically, vCard objects are encoded in it's own defined text-based syntax or XML renderings.
The objective of this document is to provide an equivalent representation of vCard utilizing the Semantic Web representations of RDF/OWL. The goal is to allow compatible representations between RFC6350 and this vCard Ontololgy.
Previous vCard ontologies, such as the W3C Member Submission on Representing vCard Objects in RDF [VCARD-MEMBER] covered vCard version 3.0 as defined in RFC2426 [RFC2426]. RFC2426 has been obsoleted by RFC6350 and it is recommeded that this vCard Ontology be utlised for any vCard semantic representations. RFC6350 has introduced many additional changes such as new structures and properties (for example, Kind, Gender, Language, Anniversary, Calendering attributes), additional parameters, and removed features (for example, some Address types, inline vCards, Label). See Appendix A of [RFC6350] for complete details.
StacklessPython may help with running Python in embedded environments.
http://en.wikipedia.org/wiki/Spam_(electronic) "is the [reprehensible] use of electronic messaging systems to send unsolicited bulk messages, especially advertising, indiscriminately."
Do you have an HLA library for that?
don't spam false or misleading links?
To be honest, I'm not real familiar with NumbaPro's CUDA implementation , but if you were to use { can't, shouldn't, won't, wouldn't, must not } -- as in RFC 2119 -- in reference to Python and CUDA, what would be your recommendation and why?
Sure, your hand-optimized C is faster by the CPU clock, but have you read http://www.cert.org/books/secure-coding/ ? Compilers can generally optimize and prevent double frees better than I can, on a good day.
Are you implying that in this forum the context for discussion must broaden or narrow as depth increases?
Why is wikipedia so special?
If I were to draw a conclusion for this particular use case, would you take my word for it?
The linked resource helps with adding metadata to a list of links as http://en.wikipedia.org/wiki/Microdata_(HTML)
Standard
Implementations
This was the most appropriate set of web friendly formats for sharing scientific research I could compend.
Are there more?
I suppose if this were an academic endeavor one could add unique and descriptive anchor text to each of these links; but practically, as I read through comments and hover over links IOT discern their URIs, I am looking for viable ways to add valued references related to my personal experiences.
In this context, I'm not sure that it's necessary that we each draw the same, repeatable conclusions. If you are suggesting that a better way to share perspective with links to documentation would be to summarize and link between these dereferencable URI resources, I would agree with you.
[EDIT]
[Go](http://dbpedia.org/page/Go_(programming_language)) dbpedia-owl:influencedBy [Python](http://dbpedia.org/resource/Python_(programming_language)) .
[Rust](http://dbpedia.org/page/Rust_(programming_language)) dbpedia-owl:influencedBy [Haskell]( http://dbpedia.org/resource/Haskell_(programming_language)) .
http://en.wikipedia.org/wiki/Python_(programming_language) has features of a http://en.wikipedia.org/wiki/Multi-paradigm_programming_language :
Python supports multiple programming paradigms, including object-oriented, imperative and functional programming styles. It features a dynamic type system and automatic memory management and has a large and comprehensive standard library.
From http://en.wikipedia.org/wiki/Python_(programming_language)#Features_and_philosophy :
Python is a multi-paradigm programming language: object-oriented programming and structured programming are fully supported, and there are a number of language features which support functional programming and aspect-oriented programming (including by metaprogramming and by magic methods). Many other paradigms are supported using extensions, including design by contract and logic programming.
Python uses dynamic typing and a combination of reference counting and a cycle-detecting garbage collector for memory management. An important feature of Python is dynamic name resolution (late binding), which binds method and variable names during program execution.
The design of Python offers only limited support for functional programming in the Lisp tradition. The language has map(), reduce() and filter() functions, comprehensions for lists, dictionaries, and sets, as well as generator expressions. The standard library has two modules (itertools and functools) that implement functional tools borrowed from Haskell and Standard ML.
http://en.wikipedia.org/wiki/Reference_counting#Advantages_and_disadvantages
http://en.wikipedia.org/wiki/Late_binding#Late_binding_in_dynamically-typed_languages
http://en.wikipedia.org/wiki/Global_Interpreter_Lock#Benefits_and_drawbacks
Why these were so heavily downvoted is beyond me. Would this prevent http://cwe.mitre.org/data/definitions/416.html -like errors?
A few of the Python game libraries listed at http://wiki.python.org/moin/PythonGameLibraries support http://en.m.wikipedia.org/wiki/OpenGL , but really, http://en.wikipedia.org/wiki/Javascript http://en.wikipedia.org/wiki/HTML5 engines like https://github.com/turbulenz/turbulenz_engine have more support for http://en.wikipedia.org/wiki/WebGL
What part of GUI development did you find lacking?
Python (and other VM-based dynamically typed languages) cannot run meaningfully on GPGPUs.
Should probably read "RFC: Semantic ElasticSearch Rivers"
http://en.wikipedia.org/wiki/Semantics_(computer_science)#Variations
Sorry about the http://en.wikipedia.org/wiki/Noise
Are there standards for this?
Testing Process Development:
1. edit, edit, commit
2. edit, commit
3. todo, edit, commit
4. todo, edit, test, commit
5. todo, test, edit, test, commit
6. todo, test, edit, test, commit, tag
7. todo, branch, test, edit, test, commit, { tag, push, send patch }
8. todo, qnew, test, edit, test, commit, finish, { tag, push, send patch }
Testing Techniques: /r/IPython REPL
?
%edit?
%edit -p
%ed -p
%logstart?
%logstart log_input_to_here.py
%logstart -o log_input_and_output_to_here.py
%run nosetests
!nosetests --help
!nosetests --ipdb
%doctest_mode?
%nose # ipython_nose
Testing Science: Learning
Testing Software
Python Testing
Testing Techniques: Logging
Testing Tools: Nose
Testing Tools: py.test
Testing Tools: GUI
Testing Tools: Tox
Testing Techniques: Mocks
Testing Tools: BDD
Testing Techniques: Continuous Integration and Delivery
Testing Techniques: Patches, Tags, Branches, Merging
Testing Techniques: DVCS: Bisect, Blame
Debugging
Debugging: Console, CLI, Terminal, REPL, /r/IPython
import pdb; pdb.set_trace()
set_trace)Debugging: Web
Debugging: GUI
Advanced Debugging
Instrumentation
Testing Databases: Fixtures
Testing Databases: Schema Migrations
Testing Web Frameworks
Testing Web Apps
https://github.com/RDFLib/rdflib-sqlalchemy/blob/master/rdflib_sqlalchemy/SQLAlchemy.py#L909
[EDIT]
ElasticSearch does analysis, http://en.wikipedia.org/wiki/Search_engine_indexing and http://en.wikipedia.org/wiki/Faceted_search .
Admins can create mappings with indices through an HTTP POST API http://www.elasticsearch.org/guide/reference/api/admin-indices-put-mapping/ .
ElasticSearch indexes are Versioned, Searchable, and Timestamp aware
One could index specific properties of chunks of RDF (as JSON-LD with Schema.org http://en.wikipedia.org/wiki/Ontology_(information_science) URIs , and then apply ElasticSearch facets for things like histograms and term statistics.
TIL about pizza with seaweed, red pepper, magnesium, potassium, folates and vitamin A. Good call.
python2 -m SimpleHTTPServer [port#]python3 -m http.server [--cgi] [port#]An if __name__=="__main__": in http://hg.python.org/cpython/file/2.7/Lib/ast.py might be cool.
I would agree that http://en.wikipedia.org/wiki/I,_Robot suggests the insufficiency of a few simple rules. In my opinion, as dielectic devices, the book and the film-adaptations also necessitate understanding of own human conceptions of Hume's Moral Philosophy and http://en.wikipedia.org/wiki/Enlightened_self-interest .
:::turtle
_article sioc:topic <https://en.wikipedia.org/wiki/Semantic_web>
_article sioc:topic <https://en.wikipedia.org/wiki/Linked_data>
_article sioc:topic <https://en.wikipedia.org/wiki/Academic_publishing>
... Bump, Like, +1
This is an awesome reference for Big-O complexity classes; thanks! I wasn't able to find an ontology for describing algorithmic complexity, but it would be great if there were structured attributes (e.g. in Wikipedia infoboxes or in library docstrings) for the data in these complex tables.
[EDIT] If you are looking for which version of a particular package is included in the Debian Wheezy package repositories, there is an RDF API that will return a package description in Turtle or RDF:
For example:
[EDIT] Some of these have prerequisite descriptions that you could read through:
[EDIT]
/r/Python Resources
Edutech Standards
https://en.wikipedia.org/wiki/Tin_Can_API
http://en.wikipedia.org/wiki/Schema.org
http://en.wikipedia.org/wiki/Learning_Resource_Metadata_Initiative
/r/IPython Resources
Hosting IPython shells
%version_informationOrganizations
http://ipython.org/ipython-doc/stable/install/install.html#installing-the-development-version
Or, assuming that you have already installed the required dependencies, just:
pip install -e git+https://github.com/ipython/ipython#egg=IPython
From http://ipython.org/ipython-doc/stable/interactive/tutorial.html#introducing-ipython :
If you’ve never used Python before, you might want to look at the official tutorial or an alternative, Dive into Python.
IPython
Anaconda
From http://docs.continuum.io/anaconda/ :
Anaconda is a free collection of powerful packages for Python that enables large-scale data management, analysis, and visualization for Business Intelligence, Scientific Analysis, Engineering, Machine Learning, and more.
I haven't had a chance to implement this, but it looks pretty cool: https://github.com/cloudmatrix/esky
"Who would ever need a 1 MB hard drive?"
From https://github.com/sympy/sympy/blob/sympy-0.7.2/sympy/interactive/session.py#L5 :
from __future__ import division
from sympy import *
x, y, z, t = symbols('x y z t')
k, m, n = symbols('k m n', integer=True)
f, g, h = symbols('f g h', cls=Function)
IPython Notebook Configuration
IPython and IPython notebook are designed to execute arbitrary Python code. This includes os.system and subprocess. IPython notebook grants unrestricted access to the host system as the user running the process: anything that can be run from a shell can be done from an IPython notebook.
ipython notebook --help-all | less
Message authentication
ipython notebook --secure
ipython notebook --ident=<UUID>
HTTPS/SSL
a. Configure IPython notebook with SSL
ipython notebook --certfile
b. Put IPython notebook behind a reverse proxy with SSL support
Notebook Password
http://ipython.org/ipython-doc/rel-0.13.1/interactive/htmlnotebook.html#security
MathJax Local Installation
http://ipython.org/ipython-doc/dev/install/install.html#mathjax :
from IPython.external.mathjax import install_mathjax
install_mathjax()
Process Supervision
GNU screen is awesome, but it doesn't do process supervision : if a process running in screen (or sysvinit) halts or hangs it will not be restarted automatically.
Here are a number of http://en.wikipedia.org/wiki/Process_supervision utilities that will manage background processes and pipe stdout and stderr to log files:
If I could reformulate your question with similar terms, it sounds like you are searching for an efficient method for repeating 'river' events to clients over WebSockets in real-time. I'm sure you're aware of the complexity and overhead required to match, route, and forward patterns on every insert, update, and delete.
I don't know much about Postgres or PL/Python.
Every application is different. Obviously the client-side ORM events in SQLAlchemy only work for statements executed with ORM mapped classes (e.g. declarative base). If you decide to store database logic in triggers across a database cluster, synchronizing and debugging on-disk functions and in-database trigger functions can get messy.
With MapReduce (e.g. BigTable, CouchDB, MongoDB, Disco), map functions that emit values to be indexed and/or aggregated by reduce functions are similar to insert-time trigger functions (on_insert, on_update, on_delete), except there is a more well-defined order of execution. MapReduce maps nicely to synchronous and parallel/asynchronous implementations of map (e.g. itertools.imap, eventlet.imap, gevent.imap), which makes scaling and testing simpler.
Vertex Messaging may be closer to what you are looking for.
The http://wiki.python.org/moin/TimeComplexity of the chosen solution is a primary determinant of 'cost' and competitive advantage.
Python is a multi-paradigm language introduced in 1991. In terms of variable scoping as compared to Java, Python class attributes that begin with __ are mangled. Many of us are adults here.
Java is an OOP language introduced in 1995. With a lot of marketing and a claim of complete platform portability.
Scala is really cool too.
{ Why would I need a different syntax to recognize the value of designing applications with appropriate levels of abstraction; like interfaces, and queuing state persistence into transactions? }
Zope 2 implements wasteful OOP patterns that promised ultimate flexibility but, unfortunately, delivered needless complexity.
What is Zope 2 doing now? Modularizing code cliques into packaged eggs with dependency trees to decrease the length of the feedback loop between coding and testing (making things faster by simplification).
There are many applications large and small -- enterprisey and elegant -- that are developed, hosted, and scaled in Java and Python.
From http://schema.rdfs.org/ :
From http://blog.schema.org/ :
From http://schema.rdfs.org/tools.html :
Awesome. Does it have graphs of tasks and services?
A content management system web portal displays types of content (content types) in portlets.
The Java standards for portlets are JSR-168 and JSR-268.
Plone has portlets
There are many Django CMS systems (e.g. ArmstrongCMS has wells, django-stories has stories)
Caches backed by RAM and SSDs can be implemented for both client and server.
A. Client/Frontend: AJAX ((Parallel) Asynchronous Javascript), HTTP pipelining
B. Server/Backend: REST URL naming, HTTP Caching, HTTP Load Balancing
** What part of this resource named with a URL actually changes on invocation? **
C. Lower-level Caching
"There are only two hard problems in Computer Science: cache invalidation and naming things." -- Phil Karlton
Many of the features (e.g. revision control) described in JSR-170 [1] dramatically increase the complexity of building a "massively parallel CMS" .
Asynchronous Python implementations of CMIS [2][3][4] clients and servers would be great.
AFAIK, Kotti is faster than Plone. There are many efficient extensions for Plone.
If by massively parallel you mean "faster search", ElasticSearch scales and is REST-based.
cpvirtualenv (source) (dest)
type cpvirtualenv
http://virtualenvwrapper.readthedocs.org/en/latest/command_ref.html#cpvirtualenv
TriG is an extension of Turtle ([TURTLE-TR]), extended to support representing a complete RDF Dataset.
TriG (.trig) = Turtle (.ttl) + Named Graphs
what would you improve about packaging and deployment?
It can. After running test suite(s), a build script (e.g. tox and/or buildout) can produce 'build artifacts' which can be
A configuration management script/system can be then be updated to pull the latest version from a package archive/repository. In some environments, it is safer to pin specific versions than to always pull the latest version. A manual package signing step can help with this.
Fabric is useful for automating scp/rsync push deployments and application configuration (e.g. rm *.pyc). There is a context manager for sudo in fabric.
http://guide.python-distribute.org/specification.html#development-releases
PEP 386: Changing the version comparison module in Distutils (2010)
PEP 440: Version Identification and Dependency Specification (2012) [DRAFT]
PEP 426: Metadata for Python Software Packages 2.0 (2012) [DRAFT]
compoze "provides a set of tools for managing private / project-specific package indexes."
pip install -e git+https://github.com/surfly/gevent.git#egg=gevent
http://www.pip-installer.org/en/latest/usage.html#pip-install (example #5)
Interestingly, the systems supporting http://edx.org are written in Python and in the process of open sourcing.
Is Python a good language for distributed, grid, big data computing?
Python is useful for
[1] http://en.wikipedia.org/wiki/Comparison_of_open_source_configuration_management_software
[2] http://libcloud.apache.org/docs/
[4] http://pyvideo.org/search?q= { distributed, high+performance, numpy, scipy, pandas, blaze, big data }
It sounds like you want community review and faceted, sortable search; with cost algorithms.
It would be great if I could go to [1] and/or [2] and/or [3] and/or [4] and determine a schema and/or a criteria for choosing a good plan.
I believe [6][7][8] describe current efforts towards putting in place health state marketplaces.
In terms of creating standards for sharing market offerings, the microformat and ontology standards in [9][10][11][12] may cover most use cases.
I was unable to locate an RDF ontology for describing the US market for healthcare services. Such an ontology might reference schema terms from [9][10][11][12].
How do providers update offerings and accepted plan agreements?
Is there a web-form with some sort of authentication and authorization?
Could it be as simple as extracting and aggregating offerings described in microdata from an offerings page?
Could it be as simple as updating structured data files in a github repository with a change log and a commit-hook?
Health Care Exchange Application
Features
Models
Is there an example dataset in JSON, XML, CSV, RDF, or SQL?
Controllers
Routes
/search
/plans/<plan-provider>/<plan-name>
/providers/<provider-id>
Views
Create, Read, Update, Delete + Authorizations
Search
List / Search Result
Faceted Search
Community Review
Feedback
Who would moderate Q&A (and update the FAQ wiki) when an answer to a question cannot be found by searching [1][2][3][4][5][6][7][8]?
Could we make a contest out of this?
In IPython:
%logstart -o log_input_and_output_to_here.py
%edit? # (`q` to close)
%ed?
%edit -p
%ed -p
?
%edit -p will launch $EDITOR and execute the entered code on editor exit. Re-running %edit -p will re-open the same block of code.
Two separate things: tools and process. IPython is a great tool.
It sounds like your current process is a loop:
Test driven development is all about automating testing (writing 'tests' first). Tests make assertions about inputs and outputs.
A TDD feedback loop looks more like:
A unit test tests an individual unit of source code:
https://github.com/flavioamieiro/nose-ipdb can assist you with http://en.wikipedia.org/wiki/Test-driven_development . nose-ipdb is an extension for https://nose.readthedocs.org/en/latest/ which launches IPython as a debugger ( https://pypi.python.org/pypi/ipdb )
From IPython:
%run nosetests --ipdb
!nosetests --ipdb
Thanks. ~greatest common factor vs browser preferences.
sage: http://sagemath.org/
"Algorithmic Graph Theory" David Joyner, Minh Van Nguyen, Nathann Cohen (2012) https://code.google.com/p/graphbook/
"Explorations in Algorithmic Graph Theory with Sage" Chris Godsil, Rob Beezer (2010) http://buzzard.pugetsound.edu/sage-practice/
Awesome, thanks!
The linked page lists font coverage stats by operating system; enabling design of more widely appropriate CSS monospace font style rules.
The use of Courier indicates a Mac-centric design. Is there a reason for not just specifying monospace to respect local preferences?
EDIT: http://www.w3.org/TR/CSS2/fonts.html#generic-font-families :
Generic font families are a fallback mechanism, a means of preserving some of the style sheet author's intent in the worst case when none of the specified fonts can be selected. For optimum typographic control, particular named fonts should be used in style sheets.
All five generic font families are defined to exist in all CSS implementations (they need not necessarily map to five distinct actual fonts). User agents should provide reasonable default choices for the generic font families, which express the characteristics of each family as well as possible within the limits allowed by the underlying technology.
User agents are encouraged to allow users to select alternative choices for the generic fonts.
Most of the time, it is better to limit the importable modules to only the set necessary for an app's particular function. A shorter sys.path is faster and less likely to cause problems. This requires extra work for sysadmins attempting to keep their packages updated.
Testing is core.
How would one know that the user always wins?
From http://en.wikipedia.org/wiki/Acetate#Acetate_in_biology
it has been proposed that acetate resulting from oxidation of ethanol is a major factor in causing hangovers
... ?
I read the blog post. Impressive demonstration of exposed Python internals. Fun-looking CTF.
The Python documentation does not claim that eval (with a limited set of locals and builtins to optimize lookups) is a sandbox.
http://docs.python.org/2/library/functions.html#eval is not a http://en.wikipedia.org/wiki/Sandbox_(computer_security)
Chroot is not a sandbox.
...
ast.literal_eval(node_or_string)
Safely evaluate an expression node or a string containing a Python expression. The string or node provided may only consist of the following Python literal structures: strings, numbers, tuples, lists, dicts, booleans, and None.
This can be used for safely evaluating strings containing Python expressions from untrusted sources without the need to parse the values oneself
(upvoted)
from __future__ import print_function # < python 3
print(*objects, sep=' ', end='\n', file=sys.stdout)
import pprint
pprint.pprint(object, stream=None, indent=1, width=80, depth=None)
_ = 'racecar'
assert _ == _[::-1]
I guess it depends on the choice of patterns. Decorators are useful for http://en.wikipedia.org/wiki/Aspect-oriented_programming
There are also times where it can be alot easier to decorate (or instrument) a class/function/method for debugging or tracing than to step through or set_trace and muck around.
%timeit+1. with python < {3, 2.7}, it is generally faster to instantiate a tuple than a list.
not:
set([1,2,3,4])
but:
set((1,2,3,4))
This may have a bit more breadth than language syntax, but:
it seems like you are asking about best practices for indicating that a particular URI is actionable?
on_<condition> -> POST(url, data) -> request_handler(url, data) -> { feed fridge, clean fridge, recreate diet }
(Awesome project!)
Eloquent metaphor, but factually incorrect; as well as being unnecessarily suggestive of artificial cognitive limitations. "Don't shoot for the moon, you fools."
For reference:
With Sphinx and ReStructuredText it is possible to inline info field lists in function, class, module, and method docstrings.
def ex(a, b):
"""
example function
:param a: first value
:type a: int
:param b: second value
:type b: [str] | iterable of strs
:rtype: str
"""
EDIT: http://google-styleguide.googlecode.com/svn/trunk/pyguide.html?showone=Comments#Comments
Sphinx.ext.autodoc can then generate Sphinx documentation sets from docstrings that can be included into whatever document hierarchy suits your purpose.
It can be noisy when reading/tracing through code and file-level commit logs, though, so it is also possible (maybe even advisable?) to maintain a separate .rst (or .txt, if you enjoy setting editor syntax manually) file with a /-ified namespace as the referenced code. The parallel documentation page can then just include the docstring signature amidst narrative documentation and relevant up-to-date usage examples.
IMHO the Pyramid docs are a good example of maximizing the utility of Sphinx:
When there is a canonical function/module/class/method block to link to, relative intra-project (:py: domain) links look like:
:py:module::`itertools`
:py:function::`itertools.cycle`
:py:class::`csv.DictWriter`
:py:method::`csv.DictWriter.writerow`
I can't remember exactly what happens when a docstring is manually included more than once or not at all.
Intersphinx mappings function alot like URL curie macros. The intersphinx mapping prefix is substituted for a base URL at compile time, which is nice:
:ref:`itertools <python:itertools>`
Sphinx documentation sets do not require internet access: they can be built from source and served locally or generated into interlinked PDF. And/or ePub.
Open Source Documentation Hosting
install && sphinx-build && python -m SimpleHTTPServer localhost:8080I was considering writing additional documentation.
I am astounded at the lack of additional documentation produced by this thread. You all should be ashamed of yourselves.
Um, admittedly, I have been working in Python for a number of years, so it is a bit difficult to view things from a newcomer's perspective. Everyone learns differently.
There are different approaches to coping with perceived inadequacies in free online resources.
There are some very generous people in the Python community (particularly in r/learnpython) who enjoy helping people. (They write books, which are awesome.) If you respectfully ask a specific question, with sample code, you will probably get an answer. You are more likely to get an answer (and help other people) if you link to where all you have searched for an answer before requesting others' time.
There are also people in the Python community who contribute documentation and code. Like you, these people are busy. They are not your guardians. They do not 'belong' to you. When they (a) see a need; or (b) are feeling generous, they tend to work on discrete tasks. You are more likely to earn respect and get what you're looking for if you contribute specific bug/defect/issue reports.
"Someone should do this for me, or learn me this, for free, because otherwise I'm going to spread negative vibes about it and insult your hard work" sets such a terrible example.
Reverse proxies are single points of failure. If you are trying to write a reverse proxy in Python but having trouble with the documentation for str.__len__, it would be more responsible to search pypi for an existing implementation of a "reverse proxy" or a "reverse HTTP proxy". Are you writing a tutorial that you would like to share?
There are people with more patience who may respond well to "someone should write a patch for something, because I am too busy".
Can we produce a list of specific parts of the documentation that could be improved?
proposing to write additional documentation
We are all free to propose constructive documentation patches.
There may be an issue filed at http://bugs.python.org with a title like this post.
Python documentation is written in ReStructuredText.
Constructively, it would be great to have full argspecs for things in there.
searching for documentation
The search function for the sphinx-generated documentation is also open source. sphinx-haystack looks useful.
http://ipython.org/ipython-doc/stable/interactive/tutorial.html#tab-completion
http://ipython.org/ipython-doc/stable/interactive/tutorial.html#exploring-your-objects
http://google.com/?q=python+<terms>
entitlement
How often does smearing "I didn't ask for this" community FUD get you results? Ask respectfully and/or donate.
Dependence, Co-dependence, Interdependence
matplotlib's hexbin may help with creating a 2D histogram visualization: http://matplotlib.org/examples/pylab_examples/hexbin_demo.html
+1. Most algorithms can be succinctly expressed in Python.
Also, SICP in Python would be great.
Cool solution for instancifying kwargs.
Most SQL ORMs also have some sort of __init__ magic for instance variables.
These may also be useful for similar use cases:
Knowledge, creativity, problem solving...
(Gardner's theories are common elements of business psychology courses that focus on maximizing strengths.)
I think there are gradients of attributes for ideas guys:
n. Please add to this list.
Is there a CVE ID for this issue?
https://github.com/pypa/pip/issues/425 (a year ago: "pip should not execute arbitrary code from the internet")
Here are some links which may help in developing a solution to this vulnerability:
It looks like there is an issue filed for this in the project's issue tracker:
How easy/reasonable would it be to patch pip to utilize/depend on requests?
What time was this at?
Thanks!
Just found this paper with "Principles, Techniques and Practice of Spreadsheet Style" that may be useful in developing your course: http://arxiv.org/abs/1301.5878
One suggested strategy that may be particularly useful is "[drawing] a dependency graph". An automated method for extracting a dependency graph from a spreadsheet would be very helpful.
How many employers want Python programmers?
Here are alot of Python jobs (I searched for "python jobs"):
Is Python better as a stepping stone to more complicated languages?
Is Python better than what?
From the Zen of Python (import this):
Simple is better than complex.
Complex is better than complicated.
This is also a great answer to "How can I learn to write idiomatic Python?" : http://qr.ae/1eNah
I have learned by reading the CPython stdlib module sources. For example: pdb, inspect, pickle, and collections:
(CPython source is mirrored (many times over) with GitHub.)
[EDIT]
This is the documentation for installing IPython (and IPython notebook):
I am not sure what the intended scope of this installation document is. Whoever champions this may want to ask how appropriate/helpful it would be to link to all of the techniques for installing IPython notebook.
Here are a few ways to install and maintain an IPython notebook installation:
Scientific (and OS) python distributions have advantages and disadvantages.
If you would prefer to roll your own, wheel may be useful.
These simple shell scripts work for me, but YMMV:
The preceding comment is in the public domain (CC0).
Interesting! Great course!
Ideas for new lessons or topics not already included in the lesson plan.
As a web developer, here are some further questions that may be of use to you:
And also:
Beautiful PDF!
Is there a web ( HTML ) version of this? I would like to:
"OCLC provides downloadable linked data file for the 1 million most widely held works in WorldCat"
How do, um, we, as Americans, rationalize our inferiority complex by needing attention gained by negatively portraying others? We sponsor media events that enable scapegoats to take control of their lives and learn to love one another.
Because that's who we are, and that's what we do.
Do you have a link to the MSI sources?
Are you offering to donate resources to this project?
Why doesn't %PROGRAMFILES% default to C:/usr/lib ?
Why is it netstat -h and not netstat /?
Very helpful guides to installing and working with multiple versions of python, virtualenv, and virtualenvwrapper, thanks!
Python-guide is another useful resource:
Also, tox is great for running tests with multiple python versions.
You might find
pip freeze
particularly helpful.
I tried
netstat /?
but that didn't work. Then I found the following helpful links:
Downvoted for trolling. Is this a http://cwe.mitre.org/data/definitions/770.html ?
From http://www.python.org/about/apps/ :
From http://scipy.org/Topical_Software :
Pythonic Python code may happen to compile into more optimized code paths. Pythonic Python code fits idioms that will be understandable by other Python programmers.
timeit will show actual performance on your system.
In dpbedia,
rdfs:labels aren't simply strings, they're more like lists.
From http://www.w3.org/TR/rdf-schema/#ch_label :
The
rdfs:domainofrdfs:labelisrdfs:Resource. Therdfs:rangeofrdfs:labelisrdfs:Literal.
rdfs:labels should be rdfs:Literals, which are regexable. There may be multiple instances of rdfs:label for a particular rdfs:Resource (such as http://dbpedia.org/page/D_(programming_language)). Each instance may be for a different verbal language (like @en for english).
How do I filter for records that have a certain entry IN the
rdfs:label?
The following query is adapted from your similar question "How do I consistently query DBPedia for programming languages by name" http://www.reddit.com/r/semanticweb/comments/1257bm/how_do_i_consistently_query_dbpedia_for/c6sapxt :
PREFIX rdf: <http://www.w3.org/1999/02/22-rdf-syntax-ns#>
PREFIX dbpedia-owl: <http://dbpedia.org/ontology/>
SELECT ?pl {
?pl rdf:type dbpedia-owl:ProgrammingLanguage .
?pl rdf:label ?label .
FILTER regex(?label, "D_(programming_language)")
}
SPARQL REGEX is basically XPath REGEX.
The documentation for SPARQL 1.1 REGEX is at http://www.w3.org/TR/sparql11-query/#func-regex
The documentation for XPath REGEX is at http://www.w3.org/TR/xpath-functions/#regex-syntax
DBpedia SPARQL is served by OpenLink Virtuoso. OpenLink Virtuoso also supports additional query constructs like bif:contains for filtering queries with predicates: http://docs.openlinksw.com/virtuoso/rdfsparql.html#rdfpredicatessparql
You might try http://answers.semanticweb.com/search/?q=label+regex
SPARQL REGEX [1] is basically XPath REGEX [2]
Re: ISSUE-10: Guidance around ETags
How should a resource (rdf:Bag) be ordered before adding an ETag? [2]
This encourages me to be more careful about mapping between resources and objects.
I am getting 404s on the following links due to trailing parentheses.
This issue may also include the comments made about the use of ETags by Leigh Dodds (http://lists.w3.org/Archives/Public/public-ldp-wg/2012Jun/0013.html) and Steve Speicher (http://lists.w3.org/Archives/Public/public-ldp-wg/2012Jul/0006.html) which led to the need of "crafting the right set of guidance around ETags".
PREFIX rdf: <http://www.w3.org/1999/02/22-rdf-syntax-ns#>
PREFIX dbpedia-owl: <http://dbpedia.org/ontology/>
SELECT ?pl {
?pl rdf:type dbpedia-owl:ProgrammingLanguage .
?pl rdf:label ?label .
FILTER regex(?label, "C++", "i")
}
Here's this from the RDF Query Specification about adding Term Constraints [1] to various Query Forms [2]:
PREFIX dc: <http://purl.org/dc/elements/1.1/>
SELECT ?title
WHERE { ?x dc:title ?title
FILTER regex(?title, "web", "i" )
}
[EDIT]
Cool. I am not a fan of modelines; or trying to determine how to reformat code to fit within http://www.python.org/dev/peps/pep-0008/#maximum-line-length
Limit all lines to a maximum of 79 characters.
There are still many devices around that are limited to 80 character lines; plus, limiting windows to 80 characters makes it possible to have several windows side-by-side. The default wrapping on such devices disrupts the visual structure of the code, making it more difficult to understand. Therefore, please limit all lines to a maximum of 79 characters. For flowing long blocks of text (docstrings or comments), limiting the length to 72 characters is recommended.
The preferred way of wrapping long lines is by using Python's implied line continuation inside parentheses, brackets and braces. Long lines can be broken over multiple lines by wrapping expressions in parentheses. These should be used in preference to using a backslash for line continuation. Make sure to indent the continued line appropriately. The preferred place to break around a binary operator is after the operator, not before it. Some examples:
class Rectangle(Blob):
def __init__(self, width, height,
color='black', emphasis=None, highlight=0):
if (width == 0 and height == 0 and
color == 'red' and emphasis == 'strong' or
highlight > 100):
raise ValueError("sorry, you lose")
if width == 0 and height == 0 and (color == 'red' or
emphasis is None):
raise ValueError("I don't think so -- values are %s, %s" %
(width, height))
Blob.__init__(self, width, height,
color, emphasis, highlight)
I have considered adding a PEP8 commit hook.
https://github.com/jcrocholl/pep8 is great.
It is wholly up to you, but http://stackoverflow.com/questions/120926/why-does-python-pep-8-strongly-recommend-spaces-over-tabs-for-indentation .
From http://www.python.org/dev/peps/pep-0008/#tabs-or-spaces :
Never mix tabs and spaces.
The most popular way of indenting Python is with spaces only. The second-most popular way is with tabs only. Code indented with a mixture of tabs and spaces should be converted to using spaces exclusively. When invoking the Python command line interpreter with the -t option, it issues warnings about code that illegally mixes tabs and spaces. When using -tt these warnings become errors. These options are highly recommended!
For new projects, spaces-only are strongly recommended over tabs. Most editors have features that make this easy to do.
The section entitled "Making Basic Queries" (#basicpatterns) describes how to formulate basic graph patterns. The answers.semanticweb.com question and accepted answer #4068 link to a good SPARQL By Example tutorial.
In terms of actually writing your query, it appears that you have already answered your question with http://www.reddit.com/r/semanticweb/comments/11kcl5/how_would_i_query_dbpedia_for_a_list_of/c6n7q1z , though your question specifically asks for 100 programming languages, so the correct LIMIT clause to list 100 programming languages would be "LIMIT 100".
PREFIX dbpedia: <http://dbpedia.org/ontology/>
SELECT DISTINCT ?language {
?language rdf:type dbpedia:ProgrammingLanguage
} LIMIT 100
Are you familiar with http://wiki.opencog.org/w/OpenCogPrime:KnowledgeRepresentation? http://wiki.opencog.org/w/CogPrime_Overview#Truth_Values_and_Attention_Values describes how Atoms are quantified in OpenCog.
Thrift (https://thrift.apache.org/) and Protocol Buffers (https://code.google.com/p/protobuf/) are both useful for fast cross-language data serialization. Both Thrift and Protocol Buffers define data structures in a language-independent format.
[EDIT]
http://en.wikipedia.org/wiki/Application_software ⊇ http://en.wikipedia.org/wiki/Web_application ... the browser displays the interface ( HTML, JS, flash, canvas, ___ )
https://github.com/seedifferently/the-great-web-framework-shootout
http://en.wikipedia.org/wiki/Model%E2%80%93view%E2%80%93controller is one popular http://en.wikipedia.org/wiki/Architectural_pattern_%28computer_science%29 for applications
As a Markdown task list:
https://www.reddit.com/r/semanticweb/wiki/index
With ReStructuredText::
```restructuredtext
========
Title
========
.. index:: DBPedia
.. _dbpedia:
`<Subject <#dbpedia>`__
============================
| Wikipedia: `<https://en.wikipedia.org/wiki/Dbpedia>`__
| Homepage: http://dbpedia.org
| Docs: http://dbpedia.org/About
| Docs: http://wiki.dbpedia.org/Downloads2014
| SPARQL: http://dbpedia.org/sparql
DBPedia is an extract of RDF facts from Wikipedia. (description)
```
From https://www.reddit.com/r/semanticweb/comments/2n1bea/is_there_an_awesomesemanticweb_or_an/cm9ffxx :
> Thing > CreativeWork > http://schema.org/SoftwareApplication
>
> Thing > CreativeWork > Article > http://schema.org/ScholarlyArticle
>
> Thing > CreativeWork > http://schema.org/Code
>
> Thing > CreativeWork > http://schema.org/Dataset
Thing > CreativeWork > http://schema.org/SoftwareApplication
Thing > CreativeWork > Article > http://schema.org/ScholarlyArticle
Thing > CreativeWork > http://schema.org/Code
Thing > CreativeWork > http://schema.org/Dataset
I hereby claim:
To claim this, I am signing this object:
{
"body": {
"key": {
"fingerprint": "c408263df40dd078b04fb32b87ba41deffef15f4",
"host": "keybase.io",
"key_id": "87ba41deffef15f4",
"uid": "5bec45f4849cb5569a706370741da500",
"username": "westurner"
},
"service": {
"name": "reddit",
"username": "westurner"
},
"type": "web_service_binding",
"version": 1
},
"ctime": 1414817718,
"expire_in": 157680000,
"prev": "1318b3aa382fd296d981634f6c787d51554868095886dfbaa4ea38e510b9a423",
"seqno": 3,
"tag": "signature"
}
with the PGP key referenced above, yielding the PGP signature:
-----BEGIN PGP MESSAGE-----
Version: Keybase OpenPGP v1.1.3
Comment: https://keybase.io/crypto
yMHSAnicO8LLzMDFmL/rW6+TDcccxtMH3pQyhISkb6tWSspPqVSyqlbKTgVTaZl5
6alFBUWZeSVKVkrJJgYWRmbGKWkmBikpBuYWSQYmaUnGRkkW5kmJJoYpqWlpqWmG
pmkmSjpKGfnFIB1AY5ISi1P1MvOBYkBOfGYKUBSL+lKwhGlSarIJUMDCxDI5ydTU
zDLR3MDM2NzAHKg60dTAAKSwOLUoLzE3Fai6PLW4pLQoL7VIqVZHCShclpmcCnI0
VLooNSUlswSPlpLKAohYUjxUd3xSZl4K0MtATWWpRcWZ+XlKVoZAlcklmSDthiaG
JhaG5uaGFjpKqRUFmUWp8ZkgFabmZhYGQKCjVFCUWgY00tDY0CLJODHR2MIoLcXI
0izF0sLQzNgkzSzZ3MI8xdTQ1NTEAqjF0tTCwiwlLSkx0SQVqDbV1NAgyTLRxMhY
CeSfwrx8JStjoDMT04FGFmem5yUC3Z6qVHvoQAwLAyMXAxsrEyjSGLg4BWBRmSHJ
wTDJwfOt0xO/V5/FWJ4xsZlODrrSbRfdHpJT/XkWc+eZpB8afDetJusfOc8QNT+/
LNCquIx9Rk+F3qZXnjrKal5/jm3+4PZtXrf6zJmh2k1WZQcbvM7Jre7xW3cvo3/b
5MmLX8uK5MfLJaSElU99furQovk3Lu82ENjT2p2y7cStV7UbXJRdj5mt/S3skcNm
0vRd7GpQuOxFjuoeDeVdv01X+2YVhvzVmzRDpk3tMFP93epl8d5LpKdOXbWk+4Xe
wW0emxPWtty/+7GvcBozR/Hajw5tkesSdjff3nR/7nLH85/OmnBa9D28+Kt7x8ST
DnP+XZ4nE2Kkl3p1vjTPzilPV9Q9Fuc/dDnircXHbXUAHicUBg==
=kR+y
-----END PGP MESSAGE-----
Finally, I am proving my reddit account by posting it in KeybaseProofs.
Anyone have any ideas for how the UMLS and OpenFDA APIs could be integrated?
https://github.com/FDA/openfda
http://www.nlm.nih.gov/research/umls/
https://en.wikipedia.org/wiki/Unified_Medical_Language_System
We are one of seven states that has not yet adopted Common Core curriculum standards.
http://www.corestandards.org/standards-in-your-state/
How do Nebraska curriculum standards differ from Common Core?
https://en.wikipedia.org/wiki/CURIE
[schema:Thing] --> http://schema.org/Thing
https://en.wikipedia.org/wiki/QName
@prefix schema: <http://schema.org/>
schema:Thing --> http://schema.org/Thing
QNames:
https://en.wikipedia.org/wiki/Linked_data
https://en.wikipedia.org/wiki/Reproducibility
Are there tools and processes which simplify statistical data analysis workflows with linked data?
Possible topics/categories/clusters:
Standard References
"Joint Declaration of Data Citation Principles" http://www.force11.org/datacitation ( http://redd.it/1z7owb )
These citation principles are not comprehensive recommendations for data stewardship. And, as practices vary across communities and technologies will evolve over time, we do not include recommendations for specific implementations, but encourage communities to develop practices and tools that embody these principles.
We can convert BibTeX to RDF:
There are tools for working with BibTeX in http://schema.org/ScholarlyArticle s.
What are some best practices for working with citations as RDF and BibTex?
We can encode structured citation metadata within HTML as e.g. RDFa and JSON-LD. How and where do we store metadata for PDFs?
How do we deliver a PDF and Datasets as a bundled package (with stable URIs and URLs)?
/r/autowikibot has a few features for things like upvote/downvote, banned subreddits, etc.
A few (additional?) features that may be useful:
shorturl/shortlink support
"deep-linking" to specific answers
(x-post from http://redd.it/1vlkoq#cetjebh)
How is anything but completely automated analysis with a null hypothesis not biased?
https://en.wikipedia.org/wiki/Blind_experiment
https://en.wikipedia.org/wiki/Bias_(statistics)
https://en.wikipedia.org/wiki/Null_hypothesis
https://en.wikipedia.org/wiki/Reproducibility
https://en.wikipedia.org/wiki/Statistical_analysis
How many random seeds are there?
A few class-based approaches to working with URLs and URIs in Python:
https://pypi.python.org/pypi/URLObject
https://pypi.python.org/pypi/rdflib
https://pypi.python.org/pypi/fs
stdlib
Are there more?
https://en.wikipedia.org/wiki/Path_(computing)
https://en.wikipedia.org/wiki/Uniform_resource_locator
https://en.wikipedia.org/wiki/Uniform_resource_identifier
https://en.wikipedia.org/wiki/CURIE
https://en.wikipedia.org/wiki/QName (XML, RDF, RDFa)
What are some of the best practices (tools, techniques, procedures) for working with SPARQL in Javascript?
How should string concatenation issues be handled?
How does JSON-LD integrate with JS framewoks?
Is there a way to generate templates/bindings from existing models?
Is there a standard for mapping RDF classes to JS UI 'widgets'?
http://www.reddit.com/dev/api#GET_user_{username}_{where}
...
...
( Sidebar -> "Show Source") [http://ipython.org/ipython-doc/dev/_sources/development/ipython_directive.txt] )
.. ipython::
In [1]: height = 2
In [2]: height**3
Out[3]: 8
# ...
In [4]: width = height * 3
In [5]: width
Out[6]: 6
In [7]: print width
--------> print(width)
6
In [8]: area = width[) # assertRaises(SyntaxError)
------------------------------------------------------------
File "<ipython console>", line 1
area = width[) # assertRaises(SyntaxError)
^
SyntaxError: invalid syntax
# ... With syntax highlighting
seeAlso:
http://read-the-docs.readthedocs.org
Sphinx and ReStructuredText (.rst, ReST)
Contention
"This one article that I read by J. Doe is great".
Why do pop-science writers so frequently fail to link to the academic papers they are writing about?
To me, it seems natural to link to the content being summarized and sensationalized; and it seems wasteful (what ads?) to create an HTML page without a link to the topic of discussion.
Citations for Journalists
Cool tube.
Metadata Microdata / RDFa
Schema.org/Article (IPTC rNews) metadata would be extremely helpful for meta-analyses:
These are all of the schema.org types on one HTML page: schema.org / docs / full.html.
Questions
http://pyramid.readthedocs.org/en/latest/designdefense.html
http://en.wikipedia.org/wiki/Software_design_pattern
http://en.wikipedia.org/wiki/Inversion_of_Control#Implementation_techniques
In attempting to reconcile my ZCA vocabulary with Java IoC terminology:
Do the Pyramid configuration system and Pyramid Zope Component Architecture Application Registry (ZCA) implement a service locator pattern?
/r/Python links to http://reddit.com/r/Python
It would be great if /w/Wikipedia or /w/en/Wikipedia linked to one of:
A comment could then contain something like:
[Python](/w/Python_(Programming_Language))
Similar
Schema.org is a standard web schema for Linked Data content that can be shared in a number of traditional and semantic web data formats.
schema:Thing > schema:CreativeWork > schema:Dataset * ^
=> implies)From http://schema.rdfs.org/all.ttl :
@prefix schema: <http://schema.org/>.
@prefix rdf: <http://www.w3.org/1999/02/22-rdf-syntax-ns#>.
@prefix rdfs: <http://www.w3.org/2000/01/rdf-schema#>.
@prefix owl: <http://www.w3.org/2002/07/owl#>.
@prefix xsd: <http://www.w3.org/2001/XMLSchema#>.
@prefix foaf: <http://xmlns.com/foaf/0.1/>.
@prefix dct: <http://purl.org/dc/terms/>.
<http://schema.rdfs.org/all> a owl:Ontology;
dct:title "The schema.org terms in RDFS+OWL"@en;
dct:description "This is a conversion of the terms defined at
schema.org to RDFS and OWL."@en;
foaf:page <http://schema.rdfs.org/>;
rdfs:seeAlso <http://schema.org/>;
rdfs:seeAlso <http://github.com/mhausenblas/schema-org-rdf>;
dct:hasFormat <http://schema.rdfs.org/all.ttl>;
dct:hasFormat <http://schema.rdfs.org/all.rdf>;
dct:hasFormat <http://schema.rdfs.org/all.nt>;
dct:hasFormat <http://schema.rdfs.org/all.json>;
dct:hasFormat [
dct:hasPart <http://schema.rdfs.org/all-classes.csv>;
dct:hasPart <http://schema.rdfs.org/all-properties.csv>;
];
dct:source <http://schema.org/>;
dct:license <http://schema.org/docs/terms.html>;
dct:valid "2013-05-09"^^xsd:date;
.
schema:Thing a rdfs:Class;
rdfs:label "Thing"@en;
rdfs:comment "The most generic type of item."@en;
rdfs:isDefinedBy <http://schema.org/Thing>;
.
schema:Class a rdfs:Class;
rdfs:label "Class"@en;
rdfs:comment "A class, also often called a 'Type';
equivalent to rdfs:Class."@en;
rdfs:subClassOf schema:Thing;
rdfs:isDefinedBy <http://schema.org/Class>;
.
schema:CreativeWork a rdfs:Class;
rdfs:label "Creative Work"@en;
rdfs:comment
"The most generic kind of creative work,
including books, movies, photographs, software programs, etc."@en;
rdfs:subClassOf schema:Thing;
rdfs:isDefinedBy <http://schema.org/CreativeWork>;
# [...]
schema:DataCatalog a rdfs:Class;
rdfs:label "Data Catalog"@en;
rdfs:comment "A collection of datasets."@en;
rdfs:subClassOf schema:CreativeWork;
rdfs:isDefinedBy <http://schema.org/DataCatalog>;
.
schema:Dataset a rdfs:Class;
rdfs:label "Dataset"@en;
rdfs:comment "A body of structured information describing
some topic(s) of interest."@en;
rdfs:subClassOf schema:CreativeWork;
rdfs:isDefinedBy <http://schema.org/Dataset>;
# [...]
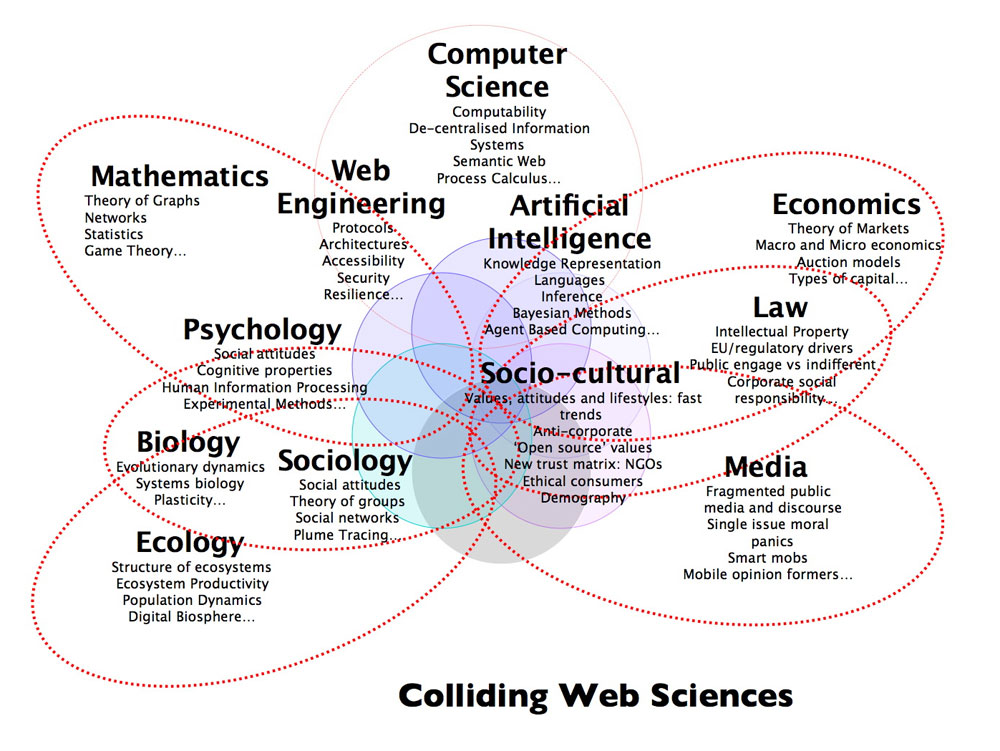{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
http://sarge.readthedocs.org/en/latest/overview.html#why-not-just-use-subprocess